

 个人中心
个人中心 退出
退出




那些年我们踩过的坑,SQL 中的空值陷阱!
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
NULL 即是空
三值逻辑
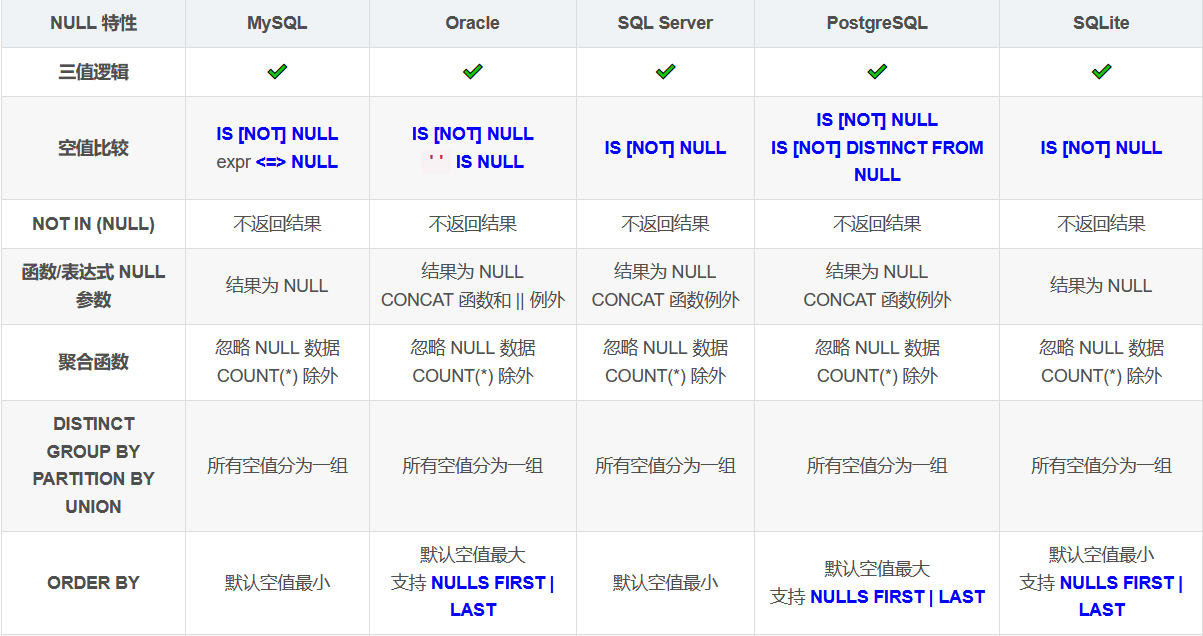
空值比较
NOT IN 与空值
函数与空值
DISTINCT、GROUP BY、UNION 与空值
ORDER BY 与空值
空值处理函数
字段约束与空值
null
SQL 是一种声明式的语言,我们只需要描述想要的结果(WHAT),而不关心数据库如何实现(HOW);虽然 SQL 比较容易学习,但是仍然有一些容易混淆和出错的概念。
今天我们就来说说 SQL 中的空值陷阱和避坑方法,涉及的数据库包括 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite。还是老规矩,结论先行:
本文使用的示例数据可以点击链接《SQL 入门教程》示例数据库下载。
NULL 即是空
在数据库中,空值(NULL)是一个特殊的值,通常用于表示缺失值或者不适用的值。比如,填写问卷时不愿意透露某些信息会导致录入项的缺失,在公司的组织结构中总会有一个人(董事长/总经理)没有上级领导。
首先一点,空值与数字 0 并不相同。假如我问你:你的钱包里有多少钱?如果你知道里面没有钱,可以说是零;如果你不确定,那么就是未知,但不能说没有。当我们需要创建一个表来存储这个信息的时候,应该是 NULL;除非我们能够确定钱包里面没有钱或者有多少钱。
另外,空值与空字符串(’’)也不相同,原因和上面类似。但是 Oracle 是一个例外,我们会在下文具体讨论。
在大多数编程语言中,访问 null 值通常会导致错误;但是 SQL 不会出错,只是会影响到运算的结果而已。
三值逻辑
在大多数编程语言中,逻辑运算的结果只有两种情况,不是真(True)就是假(False)。但是对于 SQL 而言,逻辑运算还可能是未知(Unknown):

trheevalue
引入三值逻辑主要是为了支持 NULL,因为 NULL 代表的是未知数据。因此,SQL 中的逻辑运算与(AND)、或(OR)以及非(NOT)的结果如下:
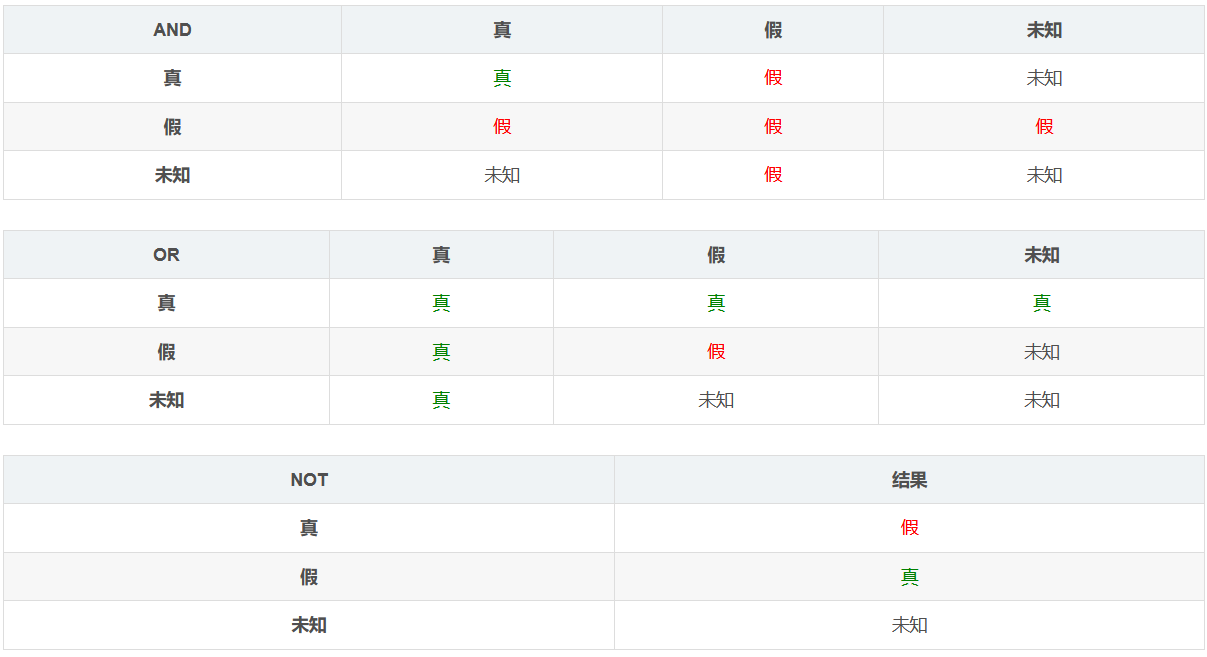
对于 AND 运算符而言,真和未知的与运算有可能是真,也有可能是假;因此,最终的结果是未知。
📝SQL 中的 WHERE、HAVING 以及 CASE WHEN 子句只返回逻辑运算结果为真的数据,不返回结果为假或未知的数据。
- 1
空值比较
当我们使用比较运算符(=、<>、<、> 等)与 NULL 进行比较时,结果既不是真也不是假,而是未知;因为 NULL 表示未知,也就意味着可能是任何值。以下运算的结果都是未知:
NULL = 0
NULL <> 0
NULL <= 0
NULL = NULL
NULL != NULL
NULL 与任何值都不相等,甚至两个 NULL 也不想等;因为我们不能说两个未知的值相同,也不能说它们不相同。
⚠️对于比较运算而言,NULL 和 NULL 不相同;但是某些 SQL 子句中的 NULL 值被看作相同的值,例如 GROUP BY。具体参考下文。
那么,如何判断一个值是否是 NULL 呢?为此,SQL 引入了两个谓词(WHERE 子句):IS NULL和IS NOT NULL。以下示例用于查找 manager 为空的员工:
– 使用比较运算符判断空值
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE manager_id = NULL;
| employee_id | first_name | last_name | manager_id |
|---|
– 使用 IS NULL 判断空值
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE manager_id IS NULL;
| employee_id | first_name | last_name | manager_id |
|---|
100|Steven |King | |
其中,第一个查询使用比较运算符判断空值,不会返回任何结果;第二个查询使用 IS NULL 判断空值,返回了正确的结果。
除了标准的IS [NOT] NULL之外,还有一些数据库扩展的运算符可以用于空值比较:
– MySQL
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE manager_id <=> NULL;
| employee_id | first_name | last_name | manager_id |
|---|
100|Steven |King | |
– PostgreSQL
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE manager_id IS NOT DISTINCT FROM NULL;
| employee_id | first_name | last_name | manager_id |
|---|
100|Steven |King | |
MySQL 中的<=>可以用于等值比较,支持两个 NULL 值;PostgreSQL 中的IS [NOT] DISTINCT FROM可以用于等值比较,支持两个 NULL 值。
以下查询的结果也不会返回任何结果:
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE (1 = NULL) OR (1 != NULL);
因为根据上面的三值逻辑,两个未知结果的 OR 运算最终还是未知。
前文我们说过,空字符串不是 NULL;但是 Oracle 中的空字符串被看作 NULL。例如:
– Oracle
SELECT 1
FROM dual
WHERE ‘’ IS NULL;
| VAL |
|---|
| 1 |
– 其他数据库
SELECT 1 AS val
WHERE ‘’ IS NULL;
| val |
|---|
当然,我们如果使用等值(=)运算符判断空字符串与 NULL,结果仍然为空。
NOT IN 与空值
对于 WHERE 条件中的 IN 和 NOT IN 运算符,使用的是等值比较。所以如果 NOT IN 碰到了 NULL 值,永远不会返回任何结果。例如:
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE 1 NOT IN (NULL, 2);
因为上面的条件实际上等价于:
SELECT employee_id, first_name, last_name, manager_id
FROM employees
WHERE 1 != NULL AND 1 != 2;
1 不等于 NULL 的结果是未知,1 不等于 2 的结果是真,未知和真的 AND 运算结果还是未知。
⚠️如果使用 NOT IN,一定要确保括号中的值不会出现 NULL;或者尽量使用 NOT EXISTS。
- 1
函数与空值
一般来说,函数和表达式的参数中如果存在 NULL,其结果也是 NULL。当然也有一些例外,比如聚合函数。
以下查询返回的都是 NULL:
SELECT ABS(NULL), 1 + NULL
FROM employees
WHERE employee_id = 100;
| ABS(NULL) | 1 + NULL |
|---|---|
| [NULL] | [NULL] |
一个未知值的绝对值仍然未知,1 加上一个未知值结果还是未知。
但是一个常见的例外是字符串与 NULL 的连接:
– Oracle、SQL Server、PostgreSQL
SELECT CONCAT(‘Hello’, NULL)
FROM employees
WHERE employee_id = 100;
| CONCAT(‘HELLO’,NULL) |
|---|
| Hello |
– MySQL
SELECT CONCAT(‘Hello’, NULL)
FROM employees
WHERE employee_id = 100;
| CONCAT(‘Hello’, NULL) |
|---|
[NULL]|
Oracle 将 NULL 看作空字符串,所以查询结果为“Hello”;SQL Server 和 PostgreSQL 虽然区分了 NULL 和空字符串,但是 CONCAT 函数中这两者等价;MySQL 中 NULL 参数导致 CONCAT 函数结果为 NULL;SQLite 没有提供 CONCAT 函数。
另外,Oracle 中的 || 也将 NULL 看作空字符串;其他数据库 || 中的 NULL 将参数会产生 NULL 结果;SQL Server 中使用 + 连接字符串,NULL 参数将会产生 NULL 结果。
聚合函数(SUM、COUNT、AVG 等)通常会在进行计算之前删除 NULL 数据:
SELECT SUM(salary + commission_pct) sum1,
SUM(salary) + SUM(commission_pct) sum2,
COUNT(salary),
COUNT(commission_pct)
FROM employees;
| SUM1 | SUM2 | COUNT(SALARY) | COUNT(COMMISSION_PCT) |
|---|---|---|---|
| 311507.8 | 691423.8 | 107 | 35 |
第一个 SUM 函数返回的是 salary 和 commission_pct 都不为空的数据总和;第而个 SUM 函数返回的是 salary 不为空的数据总和加上 commission_pct 不为空的数据总和,所以比第一个数据大;COUNT 函数结果显示 salary 有 107 条记录不为空,commission_pct 只有 35 条记录不为空。
如果输入数据都是 NULL 值,除了 COUNT 函数之外的其他聚合函数返回 NULL:
SELECT COUNT(*), COUNT(commission_pct), AVG(commission_pct), SUM(commission_pct)
FROM employees
WHERE commission_pct IS NULL;
| COUNT(*) | COUNT(COMMISSION_PCT) | AVG(COMMISSION_PCT) | SUM(COMMISSION_PCT) |
|---|
72| 0| [NULL]| [NULL]|
COUNT(*) 总是返回数据的行数,不受空值的影响;COUNT(commission_pct) 返回了零;AVG 和 SUM 返回了 NULL。
DISTINCT、GROUP BY、UNION 与空值
SQL 中的分组操作将所有的 NULL 值分到同一个组,包括 DISTINCT、GROUP BY 以及窗口函数中的 PARTITION BY。例如:
SELECT DISTINCT commission_pct
FROM employees;
| commission_pct |
|---|
[NULL]|
0.40|
0.30|
0.20|
0.25|
0.15|
0.35|
0.10|
SELECT commission_pct
FROM employees
GROUP BY commission_pct;
| commission_pct |
|---|
[NULL]|
0.40|
0.30|
0.20|
0.25|
0.15|
0.35|
0.10|
从上面的示例可以看出,commission_pct 为空的数据有 72 条,但是分组之后只有一个 NULL 组。
除此之外,UNION 操作符也将所有的 NULL 看作相同值:
SELECT manager_id
FROM employees
WHERE manager_id IS NULL
UNION
SELECT manager_id
FROM employees
WHERE manager_id IS NULL;
| manager_id |
|---|
[NULL]|
如果将 UNION 换成 UNION ALL,查询结果将会保留 2 个 NULL 值。
ORDER BY 与空值
SQL 标准没有定义 NULL 值的排序顺序,但是为 ORDER BY 定义了 NULLS FIRST 和 NULLS LAST 选项,用于明确指定空值排在其他数据之前或者之后。
不同数据库对此提供了不同的实现:
SELECT employee_id, manager_id
FROM employees
WHERE employee_id IN (100, 101, 102)
ORDER BY manager_id;
– Oracle、PostgreSQL
| EMPLOYEE_ID | MANAGER_ID |
|---|
101| 100|
102| 100|
100| [NULL]|
– MySQL、SQL Server、SQLite
| employee_id | manager_id |
|---|
100| [NULL]|
101| 100|
102| 100|
其中,Oracle 和 PostgreSQL 默认将 NULL 作为最大值,升序时排在最后;MySQL、SQL Server 和 SQLite 默认将 NULL 作为最小值,升序时排在最前。
另外,Oracle、PostgreSQL 和 SQLite 提供了扩展的 NULLS FIRST 和 NULLS LAST 选项:
– Oracle、PostgreSQL 和 SQLite
SELECT employee_id, manager_id
FROM employees
WHERE employee_id IN (100, 101, 102)
ORDER BY manager_id NULLS FIRST;
| employee_id | manager_id |
|---|
100| [NULL]|
101| 100|
102| 100|
我们也可以使用 CASE 表达式实现类似的效果。以下示例与 NULLS LAST 作用相同,而且所有数据库都可以使用:
SELECT employee_id, manager_id
FROM employees
WHERE employee_id IN (100, 101, 102)
ORDER BY CASE WHEN manager_id IS NULL THEN 1
ELSE 0
END,
manager_id;
| employee_id | manager_id |
|---|
101| 100|
102| 100|
100| [NULL]|
首先,CASE 表达式将 manager_id 为空的数据转换为 1,非空的数据转换为 0,所以空值排在其他数据之后;第二个排序字段 manager_id 确保了非空的数据从小到大排序。
空值处理函数
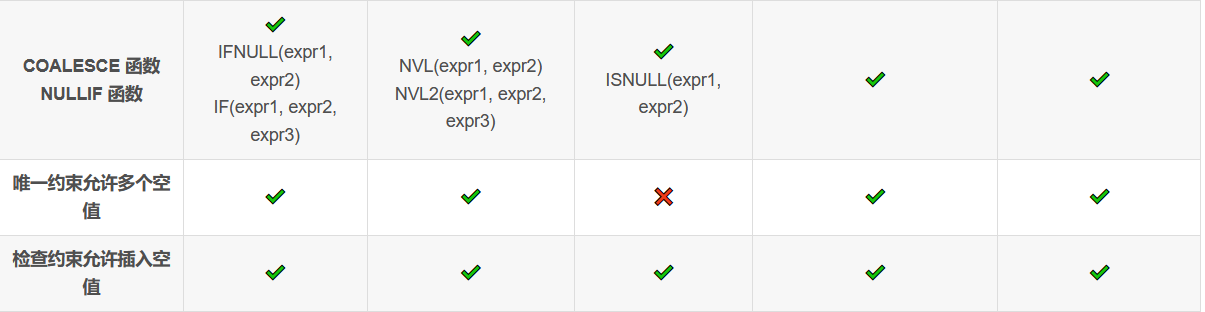
由于空值的特殊性,我们在分析数据时经常需要进行空值和其他值的转换。为此,SQL 提供了两个标准的空值函数:COALESCE 和 NULLIF。
COALESCE(exp1, exp2, …) 函数用于将 NULL 转换为其他值。当 exp1 不为空时返回 exp1,否则检查 exp2;如果 exp2 不为空时返回 exp2,依次类推。例如:
SELECT COALESCE(NULL, NULL, 3)
FROM employees
WHERE employee_id = 100;
| COALESCE(NULL, NULL, 3) |
|---|
3|
由于前面两个参数都是 NULL,COALESCE 最终返回了 3。
COALESCE 函数也可以使用 CASE 表达式改写如下:
CASE WHEN exp1 IS NOT NULL THEN exp1
WHEN exp2 IS NOT NULL THEN exp2
…
ELSE expN
END
NULLIF(exp1, exp2) 函数用于将指定值转换为 NULL。当 exp1 等于 exp2 时,返回 NULL;否则,返回 exp1 。NULLIF 最常见的用途是防止除零错误,例如:
SELECT 1 / NULLIF(0, 0) – 1 / 0
FROM employees
WHERE employee_id = 100;
示例中的 NULLIF 将第一个零转换为 NULL,因此查询结果返回 NULL;如果直接使用 1 / 0,查询将会返回除零错误。MySQL 中的除零错误由 sql_mode 变量控制。
NULLIF 函数同样可以使用 CASE 表达式改写如下:
CASE WHEN exp1 = exp2 THEN NULL
ELSE exp1
END
利用 CASE 表达式,我们还可以轻松实现多个值到 NULL 的转换:
CASE WHEN expr IN (value1, value2, …)
THEN NULL
ELSE expr
END
📝COALESCE 和 NULLIF 实际上是 CASE 表达式的两种缩写形式。
除了标准 SQL 函数之外,数据库还提供了一些专用的函数:
Oracle 中的 NVL(expr1, expr2) 相当于 2 个参数的 COALESCE。另外,NVL2(expr1, expr2, expr3) 如果第一个参数不为空,返回第二个参数的值;否则,返回第三个参数的值;
MySQL 中的 IFNULL(expr1, expr2) 相当于 2 个参数的 COALESCE。另外,IF(expr1, expr2, expr3) 如果第一个参数为真(expr1 <> 0 并且 expr1 不为空),返回第二个参数的值;否则,返回第三个参数的值;
SQL Server 中的 ISNULL(expr1, expr2) 相当于 2 个参数的 COALESCE。
字段约束与空值
如果不允许字段中存在未知或者缺失的数据,可以使用字段的 NOT NULL 约束。
对于唯一约束(UNIQUE),多个 NULL 被看作是不同的值;因此,唯一约束字段中可以存在多个空值。不过 SQL Server 是个例外:
CREATE TABLE t_unique(id INT UNIQUE);
INSERT INTO t_unique VALUES(1);
INSERT INTO t_unique VALUES(NULL);
INSERT INTO t_unique VALUES(NULL); – SQL Server 产生唯一键冲突错误
– SQL Server 除外
SELECT * FROM t_unique;
id|
------|
[NULL]|
[NULL]|
1|
– SQL Server 除外
SELECT * FROM t_unique;
id|
------|
[NULL]|
1|
对于 SQL Server 而言,唯一约束中只允许存在一个 NULL 数据;所以第 3 个 INSERT 语句执行出错,最终只有两条记录。
如果是复合索引,情况略有不同:
CREATE TABLE t_unique2(c1 INT, c2 INT, UNIQUE(c1,c2));
INSERT INTO t_unique2 VALUES(1, 1);
INSERT INTO t_unique2 VALUES(NULL, NULL);
INSERT INTO t_unique2 VALUES(NULL, NULL); – SQL Server 产生唯一键冲突错误
INSERT INTO t_unique2 VALUES(1, NULL);
INSERT INTO t_unique2 VALUES(1, NULL); – Oracle 和 SQL Server 产生唯一键冲突错误
其中,SQL Server 只允许有一个记录的全部索引字段为空;如果某个字段不为空,Oracle 和 SQL Server 只允许有一个记录的其他索引字段为空。
另外,检查约束(CHECK)对于 NULL 的处理与 WHERE 条件正好相反:只要数据的检查结果不是假都可以插入成功。例如:
CREATE TABLE t_check (
c1 INT CHECK (c1 >= 0),
c2 INT CHECK (c2 >= 0),
CHECK (c1 + c2 <= 100)
);
INSERT INTO t_check VALUES (5, 5);
INSERT INTO t_check VALUES (NULL, NULL);
INSERT INTO t_check VALUES (200, NULL);
SELECT * FROM t_check;
| c1 | c2 |
|---|
5| 5|
[NULL]|[NULL]|
200|[NULL]|
如果 c1 和 c2 都有值的话,都必须大于等于零并且和值小于等于 100;c1 和 c2 都可以为空;如果其中之一为空,另一个字段的值可以大于 100。
 分类导航
分类导航