

 个人中心
个人中心 退出
退出




实战 SQL:实现百度、高德等地图中的地铁换乘线路查询
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
简单 CTE
生成数字序列
遍历组织结构图
查找地铁换乘线路
- 1
- 2
- 3
- 4
对于大多数人来说,SQL 意味着 SELECT、INSERT、UPDATE 和 DELETE。但实际上,SQL 能够实现的功能远远不止简单的增删改查;今天我们来介绍一个高级功能:通用表表达式(Common Table Expression)。CTE 可以提高复杂查询的性能和可读性,实现树状结构或者图数据的遍历。例如:
生成数字序列;
获取员工上下级的组织关系;
查询地铁、航班换乘线路;
社交网络图谱分析。
- 1
- 2
- 3
- 4
一般来说,我们只能通过应用程序或者存储过程实现这些复杂的功能,而且性能不高。但是有了 CTE,我们可以直接利用一个 SQL 语句完成以上功能。CTE 不仅强大而且通用,各种主流数据库都提供了支持。

我们通过几个实用案例,了解一下 CTE 的语法,同时介绍各种数据库中的实现差异。
简单 CTE
通用表表达式使用WITH关键字表示:
WITH t(n) AS (
SELECT 4 – – Oracle
)
SELECT * FROM t;
| n |
|---|
| 4 |
以上 WITH 子句相当于定义了一个语句级别的临时表 t(n),在随后的 SELECT、INSERT、UPDATE 以及 DELETE 语句中都可以使用。如果是 Oracle,可以使用SELECT 2 FROM dual。
📝WITH 子句定义了一个表达式,表达式的值是一个表,所以称为通用表表达式。CTE 和子查询类似,可以用于 SELECT、INSERT、UPDATE 以及 DELETE 语句。Oracle 中称之为子查询因子(subquery factoring)。
- 1
CTE 与子查询类似,只在当前语句中有效;不过一个语句中可以定义多个 CTE,而且 CTE 被定义之后可以多次引用:
WITH t1(n) AS (
SELECT 4 – FROM dual
),
t2(n) AS (
SELECT n+1 FROM t1
)
SELECT t1.n, t2.n
FROM t1
CROSS JOIN t2;
| n | n |
|---|---|
| 4 | 5 |
第一个 CTE 名为 t1;第二个 CTE 名为 t2,引用了前面定义的 t1 ;每个 CTE 之间使用逗号进行分隔;最后的 SELECT 语句使用前面定义的 2 个 CTE 进行连接查询。这种使用 CTE 的方法和编程语言中的变量非常类似。
CTE 和视图、临时表或者子查询都有点类似,但是比它们的结构更加清晰;数据库对于 CTE 只需要执行一次,性能也会更好。不过,CTE 真正强大之处是允许在定义中调用自己,也就是递归调用。
生成数字序列

numbers
WITH子句还有一种递归形式,以下语句可以生成一个 1 到 10 的数字序列:
WITH RECURSIVE t(n) AS
(
SELECT 1 – 初始化
UNION ALL
SELECT n + 1 FROM t WHERE n < 10 – 递归结束条件
)
SELECT n FROM t;
| n |
|---|
其中,RECURSIVE表示递归,Oracle 和 SQL Server 中不需要该关键字。
递归 CTE 包含两部分,UNION ALL 上面的查询语句用于生成初始化数据;下面的查询语句用于递归,引用了它自身( t )。
运行初始化语句,生成数字 1;
第 1 次运行递归部分,此时 n 等于 1,返回数字 2( n+1 );
第 2 次运行递归部分,此时 n 等于 2,返回数字 3( n+1 );
第 9 次运行递归部分,此时 n 等于 9,返回数字 10( n+1 );
第 10 次运行递归部分,此时 n 等于 10;由于查询不满足条件( WHERE n < 10 ),不返回任何结果,并且递归结束;
最后的查询语句返回 t 中的全部数据,也就是一个 1 到 10 的数字序列。
- 1
- 2
- 3
- 4
- 5
- 6
只要是具有一定规律的数字序列都可以通过递归 CTE 生成,例如斐波那契数列。
遍历组织结构图
在公司的组织结构中,存在上下级的管理关系,如下图所示。
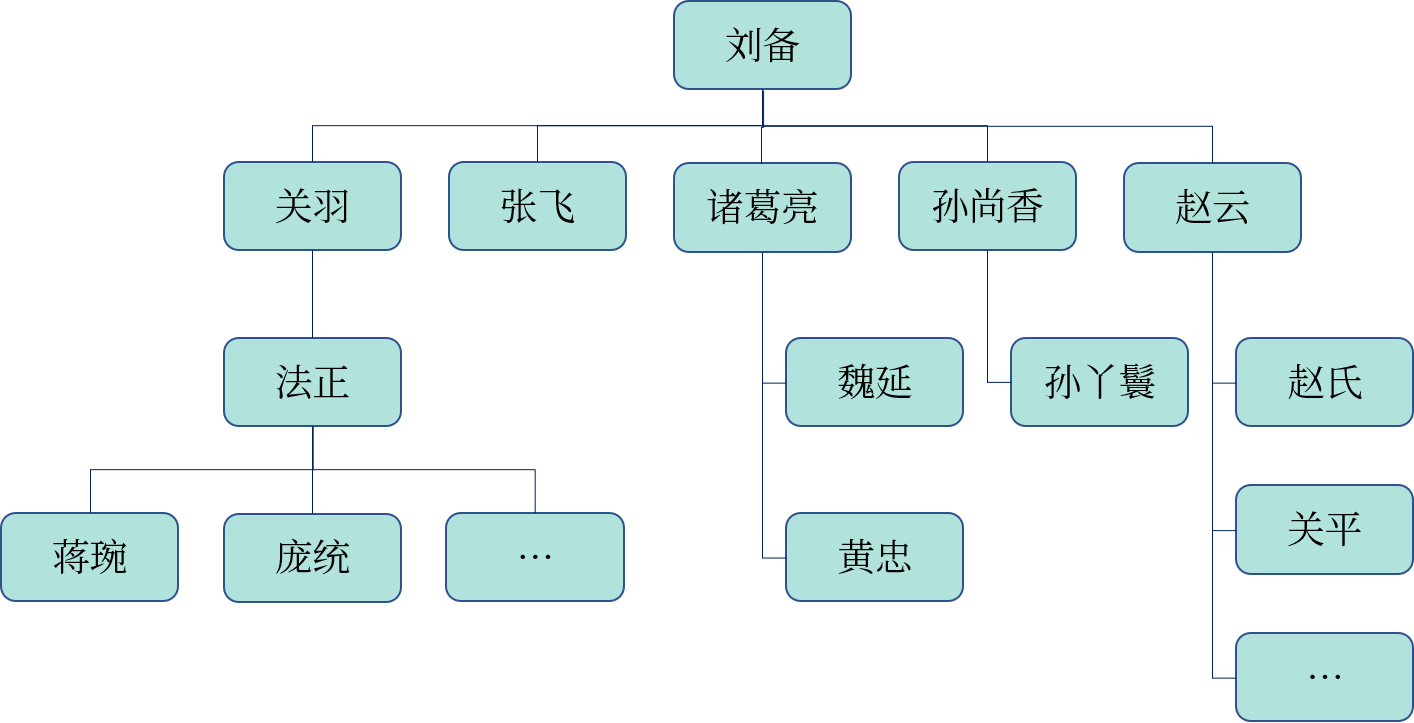
示例表和数据点此下载。如果我们想要知道某个员工从上至下的各级领导,可以使用递归 CTE 实现:
WITH RECURSIVE employee_path (emp_id, emp_name, path) AS
(
SELECT emp_id, emp_name, CAST(emp_name AS CHAR(1000)) AS path
FROM employee
WHERE manager IS NULL
UNION ALL
SELECT e.emp_id, e.emp_name, CAST(CONCAT(ep.path, ‘->’, e.emp_name) AS CHAR(1000))
FROM employee_path ep
JOIN employee e ON ep.emp_id = e.manager
)
SELECT * FROM employee_path WHERE emp_name = ‘黄忠’;
| emp_id | emp_name | path |
|---|
5|黄忠 |刘备->诸葛亮->黄忠|
- 1
上面是 MySQL 中的语法。在 Oracle 以及 SQL Server 中需要将 CHAR(1000) 改为 VARCHAR(1000),同时省略 RECURSIVE 关键字;在 PostgreSQL 中需要将 CAST 函数里的 CHAR(1000) 改为 VARCHAR(1000);SQLite 没有提供 CONCAT 函数,使用连接操作符(||)即可。
其中,初始化查询用于查找没有 manager 的员工,也就是最上级的领导;递归查询通过将员工的 manager 和上级员工的 emp_id 进行关联,获取上下级管理关系;递归结束的条件就是没有找到任何数据。当然,我们也可以从下级往上级进行遍历。
其他具有这种层级关系的数据包括多层菜单、博客文章中的评论等。
查找地铁换乘线路
地铁、公交、航班等,包括社交网站上的关注,都是一种有向图数据结构。我们通常需要查找某一站点到另一站点的最短路径,利用递归 CTE 可以实现这类需求。示例数据中目前只有地铁 1 号线和 2 号线的数据,但是足够我们进行演示。
以下语句用于查找“王府井”到“积水潭”的换乘路线,使用 PostgreSQL 数据库实现:
WITH RECURSIVE paths (start_station, stop_station, stops, path) AS (
SELECT station_name, next_station, 1, ARRAY[station_name::text, next_station::text]
FROM bj_subway WHERE station_name = ‘王府井’
UNION ALL
SELECT p.start_station, e.next_station, stops + 1, p.path || ARRAY[e.next_station::text]
FROM paths p
JOIN bj_subway e
ON p.stop_station = e.station_name AND NOT e.next_station = ANY(p.path)
)
SELECT * FROM paths WHERE stop_station =‘积水潭’;
| start_station | stop_station | stops | path |
|---|---|---|---|
| 王府井 | 积水潭 | 8 | {王府井,天安门东,天安门西,西单,复兴门,阜成门,车公庄,西直门,积水潭} |
| 王府井 | 积水潭 | 9 | {王府井,东单,建国门,朝阳门,东四十条,东直门,雍和宫,安定门,鼓楼大街,积水潭} |
| 王府井 | 积水潭 | 13 | {王府井,东单,建国门,北京站,崇文门,前门,和平门,宣武门,长椿街,复兴门,阜成门,车公庄,西直门,积水潭} |
| 王府井 | 积水潭 | 18 | {王府井,天安门东,天安门西,西单,复兴门,长椿街,宣武门,和平门,前门,崇文门,北京站,建国门,朝阳门,东四十条,东直门,雍和宫,安定门,鼓楼大街,积水潭} |
查询结果显示有 4 条路线,如果选择最短路线就是第一条。其中的 path 字段是个数组,用于存储走过的站点;最后的 NOT e.next_station = ANY(p.path) 条件用于避免反复经过同一个站点,因为地铁线路是一个双向图。
我们还可以进一步计算换乘次数,实现最少换乘路线;如果在表中增加一些字段,记录每两个站点之间的时间和换乘时间,还可以计算最快捷路线。
其他数据库没有提供数组类型,但是可以使用其他方法实现,以下是 MySQL 中的实现:
WITH RECURSIVE paths (start_station, stop_station, stops, path) AS (
SELECT station_name, next_station, 1, CAST(CONCAT(station_name , ‘,’, next_station) AS CHAR(1000))
FROM bj_subway WHERE station_name = ‘王府井’
UNION ALL
SELECT p.start_station, e.next_station, stops + 1, CONCAT_WS(’,’, p.path, e.next_station)
FROM paths p
JOIN bj_subway e
ON p.stop_station = e.station_name AND (INSTR(p.path, e.next_station) = 0)
)
SELECT * FROM paths WHERE stop_station =‘积水潭’;
我们使用了逗号分隔符的字符串模拟数组的效果,这种方法也适用于其他数据库。你用哪种数据库,有没有提供这种功能?
 分类导航
分类导航