

 个人中心
个人中心 退出
退出




机器学习选择 Python 还是 R 语言?要不直接用 SQL 吧!
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
MindsDB 简介
MindsDB 安装
使用案例
配置 MySQL
配置 MindsDB
训练模型
预测结果
删除模型
多目标预测
总结
机器学习离不开数据,机器学习框架(TensorFlow、scikit-learn、Pytorch 等)通常都需要从 CSV 文件或者其他数据源读取数据,其中主要的数据源就是数据库。所以,无论你是使用 Python、R 还是其他编程语言,都需要编写一些代码获取和准备数据;同时这种数据的格式转换和传输都需要消耗一定的时间和资源。
如果能够直接在数据库中训练机器学习模型并且进行预测,而且一切都使用 SQL 语句完成,是不是更加简单高效呢😎!今天我们给大家介绍一个基于数据库的机器学习平台:MindsDB,了解一下如何通过 SQL 语句实现机器学习预测模型。
如果觉得文章有用,欢迎评论📝、点赞👍、推荐🎁
MindsDB 简介

MindsDB 是一个基于数据库的开源 AI 平台,通过直接为数据库引入机器学习功能,从而提高工作效率。MindsDB 可以直接通过
SQL 语句创建、训练、测试模型以及进行预测,目前支持的数据库系统包括 MySQL、MariaDB、SQL
Server、PostgreSQL、ClickHouse、MongoDB 等。
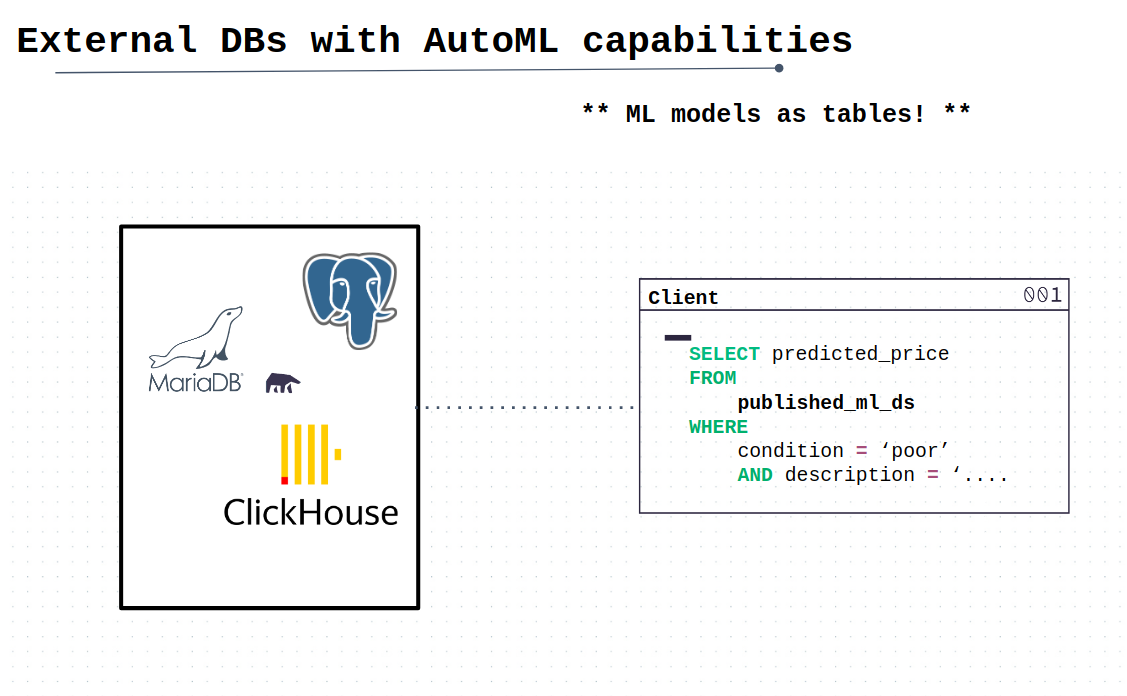
MindsDB 是一个基于 Python(Pytorch)的 AutoML 框架,也支持通过编码进行模型的训练和预测,除了数据库之外还支持 CSV、Excel、JSON、文本文件、pandas DataFrame、URL、s3 文件等数据源。 MindsDB 使用 lightwood 代码库实现了简化的自动机器学习。MindsDB 还提供了 JavaScript 和 Python 开发包,可以通过 HTTP 接口实现所有功能。
除此之外,MindsDB 还提供了一个图形管理界面 MindsDB Scout,可以从数据库、本地文件、或者外部数据源上传、分析以及可视化数据,训练模型以及查询结果。
MindsDB 安装
MindsDB 需要 python 3.6 以上版本,推荐使用虚拟环境。首先创建并激活环境:
python -m venv venv
Windows
.\venv\Scripts\activate
Linux、macOS
source venv/bin/activate
然后使用 pip 安装 MindsDB:
pip install mindsdb
最后运行 MindsDB 服务:
python -m mindsdb
运行成功返回以下类似信息:
…
mysql API: started on 47335
- GUI available at http://127.0.0.1:47334/index.html
http API: started on 47334
通过地址 http://127.0.0.1:47334 可以访问 MindsDB API;通过地址 http://127.0.0.1:47334/index.html 可以访问图形界面 MindsDB Scout。
📝其他的安装方式(包括 Docker)和相关问题,可以参考官方文档。
使用案例
接下来我们使用 MindsDB 和 MySQL 数据库训练一个预测消费的机器学习模型,并且对数据进行预测。

配置 MySQL
首先,MySQL 需要启动 FEDERATED 存储引擎支持;可以在启动服务时使用 --federated 命令行参数或者在配置文件中的 [mysqld] 部分增加一行内容:
federated
启动 MySQL 服务后使用 SHOW engines 语句确认支持 FEDERATED 存储引擎:
mysql> SHOW engines\G
*************************** 1. row ***************************
Engine: FEDERATED
Support: YES
Comment: Federated MySQL storage engine
Transactions: NO
XA: NO
Savepoints: NO
…
接下来我们需要准备一些训练模型的数据,本文使用的示例数据来源于首尔的空气污染测量数据,可以点此下载。其中 train.csv 是训练数据,test.csv 是测试数据。在 MySQL 中执行以下命令创建一个新的数据库 data 和数据表 pollution_measurement 并加载训练数据:
CREATE DATABASE IF NOT EXISTS data;
CREATE TABLE data.pollution_measurement(
measurement_date datetime,
station_code varchar(10),
address varchar(100),
latitude double,
longitude double,
so2 decimal(10, 5),
no2 decimal(10, 5),
o3 decimal(10, 5),
co decimal(10, 5),
pm10 decimal(5, 1),
pm25 decimal(5, 1)
);
LOAD DATA INFILE ‘train.csv’
INTO TABLE data.pollution_measurement columns terminated by ‘,’;
查看一下导入的训练数据:
SELECT count(*) FROM data.pollution_measurement;
| count(*) |
|---|
| 518617 |
SELECT * FROM data.pollution_measurement LIMIT 5;
| measurement_date | station_code | address | latitude | longitude | so2 | no2 | o3 | co | pm10 | pm25 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2017-01-01 00:00:00 | 101 | 19, Jong-ro 35ga-gil, Jongno-gu, Seoul, Republic of Korea | 37.572016399999995 | 127.00500749999999 | 0.00400 | 0.05900 | 0.00200 | 1.20000 | 73.0 | 57.0 |
| 2017-01-01 01:00:00 | 101 | 19, Jong-ro 35ga-gil, Jongno-gu, Seoul, Republic of Korea | 37.572016399999995 | 127.00500749999999 | 0.00400 | 0.05800 | 0.00200 | 1.20000 | 71.0 | 59.0 |
| 2017-01-01 03:00:00 | 101 | 19, Jong-ro 35ga-gil, Jongno-gu, Seoul, Republic of Korea | 37.572016399999995 | 127.00500749999999 | 0.00400 | 0.05600 | 0.00200 | 1.20000 | 70.0 | 58.0 |
配置 MindsDB
首先为 MindsDB 创建一个新的配置文件 config.json,内容如下:
{
“api”: {
“http”: {
“host”: “0.0.0.0”,
“port”: “47334”
},
“mysql”: {
“host”: “127.0.0.1”,
“password”: “Qwer!1234”,
“port”: “47335”,
“user”: “root”
}
},
“config_version”: “1.3”,
“debug”: true,
“integrations”: {
“default_mysql”: {
“enabled”: true,
“host”: “192.168.56.104”,
“password”: “pass1234!”,
“port”: 3306,
“type”: “mysql”,
“user”: “root”
}
},
“log”: {
“level”: {
“console”: “DEBUG”,
“file”: “INFO”
}
},
“storage_dir”: “/storage”
}
其中的选项如下:
api[‘http’] ,用于配置 MindsDB http 服务器的启动信息:
host(默认 127.0.0.1), mindsdb 服务器地址。
port(默认 47334),mindsdb 服务器端口。
api[‘mysql’] ,用于配置通过 MySQL 协议进行数据库集成的信息:
user(默认 root)。
password(默认为空)。
host(默认为 127.0.0.1)。
port(默认为 47335)。
integrations[‘default_mysql’],指定集成类型,这里是 default_mysql。相关的配置项如下:
user(默认 root)。MySQL 用户名。
host(默认 127.0.0.1)。MySQL 服务器地址。
password,MySQL 用户密码。
type,集成类型。包括 mariadb、postgresql、mysql、clickhouse、mongodb 等。
port(默认 3306)。MySQL 服务的 TCP/IP 端口。
enabled(true | false)。是否启用该集成。
log[‘level’],日志配置(可选项):
console,日志级别,包括 INFO、DEBUG、ERROR。
file,日志文件位置。
storage_dir,mindsdb 默认和配置的存储目录。
然后重新启动 MindsDB 服务:
python -m mindsdb --api=mysql --config=“C:\Users\dongx\venv\Scripts\config.json”
其中,–api 参数指定 API 的类型为 mysql.; --config 参数指定了配置文件的位置。
启动服务之后会连接 MySQL 数据库,创建一个新的数据库 mindsdb,并且创建两个 FEDERATED 存储引擎表:
mysql> use mindsdb;
mysql> show tables;
±------------------+
| Tables_in_mindsdb |
±------------------+
| commands |
| predictors |
±------------------+
2 rows in set (0.01 sec)
其中,predictors 是用于存储预测模型、训练状态、准确率、目标变量以及训练选项的表:
mysql> show create table predictors\G
*************************** 1. row ***************************
Table: predictors
Create Table: CREATE TABLE predictors (
name varchar(500) DEFAULT NULL,
status varchar(500) DEFAULT NULL,
accuracy varchar(500) DEFAULT NULL,
predict varchar(500) DEFAULT NULL,
select_data_query varchar(500) DEFAULT NULL,
external_datasource varchar(500) DEFAULT NULL,
training_options varchar(500) DEFAULT NULL,
KEY name_key (name)
) ENGINE=FEDERATED DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CONNECTION=‘mysql://root_default_mysql:Qwer!1234@192.168.56.1:47335/mindsdb/predictors’
1 row in set (0.00 sec)
训练模型
接下来我们就可以通过 SQL 语句训练一个新的机器学习模型,只需要往 mindsdb.predictors 表中插入一条数据即可,例如:
INSERT INTO mindsdb.predictors(name, predict, select_data_query)
VALUES (‘airq_predictor’, ‘so2’, ‘SELECT * FROM data.pollution_measurement’);
其中,
name 是预测模型(predictor)的名称,类型为字符串;
predict 是想要预测的目标特征,类型为字符串。示例中为二氧化硫(SO2)含量;
select_data_query,为模型提供训练数据的查询语句,类型为字符串。
该语句需要等待一段时间,训练完成后 predictors 表中会生成一条记录:
mysql> select * from mindsdb.predictors;
±---------------±---------±---------±--------±--------------------±--------------------±-----------------+
| name | status | accuracy | predict | select_data_query | external_datasource | training_options |
±---------------±---------±---------±--------±--------------------±--------------------±-----------------+
| airq_predictor | complete | 0.987 | so2 | MySqlDS: mysql/None | | |
±---------------±---------±---------±--------±--------------------±--------------------±-----------------+
1 row in set (0.61 sec)
其中 status 字段为 complete 表示模型训练完成。
预测结果
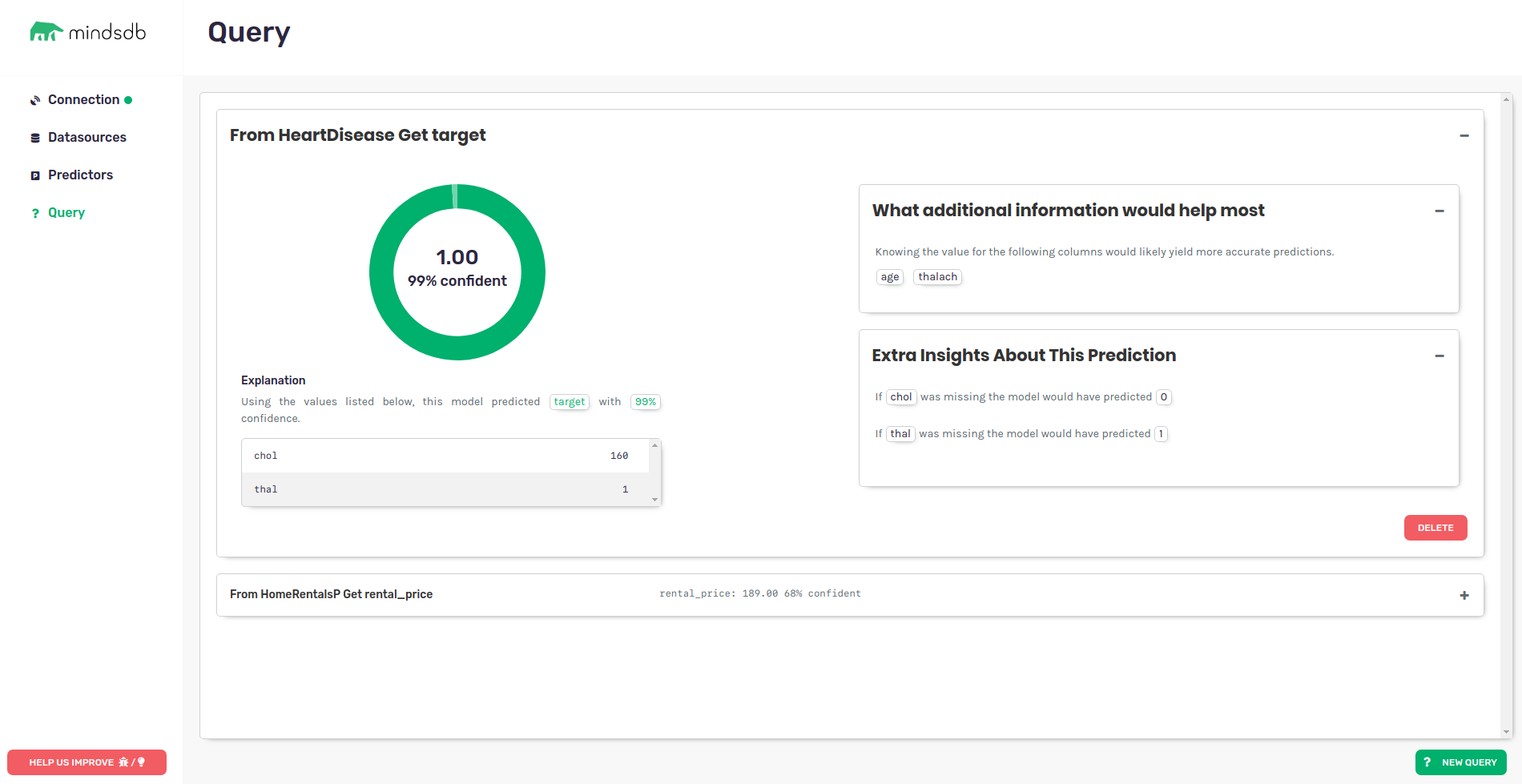
预测模型训练完成之后,还会创建一个模型表 airq_predictor。直接查询模型表就可以获取预测的目标变量、置信度以及解释信息,例如:
SELECT
so2 AS predicted,
so2_confidence AS confidence,
so2_explain AS info
FROM airq_predictor
WHERE (no2 = 0.005)
AND (co = 1.2)
AND (pm10 = 5)\G
*************************** 1. row ***************************
predicted: 0.001156540079952395
confidence: 0.9869
info: {
“predicted_value”: 0.001156540079952395,
“confidence”: 0.9869,
“prediction_quality”: “very confident”,
“confidence_interval”: [0.003184904620383531, 0.013975553923630717],
“important_missing_information”: [“Station code”, “Latitude”, “O3”],
“confidence_composition”: {
“co”: 0.006
},
“extra_insights”: {
“if_missing”: [{
“no2”: 0.007549311956155897
}, {
“co”: 0.005459383721227349
}, {
“pm10”: 0.003870252306568623
}]
}
}
1 row in set (0.00 sec)
从结果可以看出,MindsDB 预测的二氧化硫数值为 0.0011565,置信度为 98.69 %。
删除模型
如果想要删除之前创建的预测模型,可以执行以下 SQL 语句:
INSERT INTO mindsdb.commands values (‘DELETE predictor airq_predictor’);
多目标预测
另外,MindsDB 也可以训练预测多个目标特征的模型,只需要为 predict 字段指定一个逗号分隔的预测目标。例如,使用以下语句创建一个预测 so2 和 pm25 的模型:
INSERT INTO mindsdb.predictors(name, predict, select_data_query)
VALUES (‘airq_predictor’, ‘so2, pm25’, ‘SELECT * FROM data.pollution_measurement’);
然后使用以下语句进行预测:
SELECT
so2 AS predicted,
so2_confidence AS confidence,
so2_explain AS info
FROM
mindsdb.airq_predictor
WHERE
select_data_query=‘SELECT pm25 FROM mindsdb.airq_predictor limit 10’;
总结
本文介绍了如何利用 MindsDB 机器学习平台编写 SQL 语句实现预测模型,可以看出这种方式非常简单易用。当然,MindsDB 还提供了一个更简单的图形用户界面 Scout,意味着直接在页面点击即可完成模型的训练和预测。
除了使用 SQL 语句之外,MindsDB 同样支持编写 Python 或者 Javascript 代码创建预测模型,更多的功能和示例可以参考官方文档 和 GitHub 示例。
 分类导航
分类导航