

 个人中心
个人中心 退出
退出




Oracle 中实现数据透视表的几种方法
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
使用 CASE 表达式实现数据透视表
使用 PIVOT 子句实现数据透视表
使用 MODEL 子句实现数据透视表
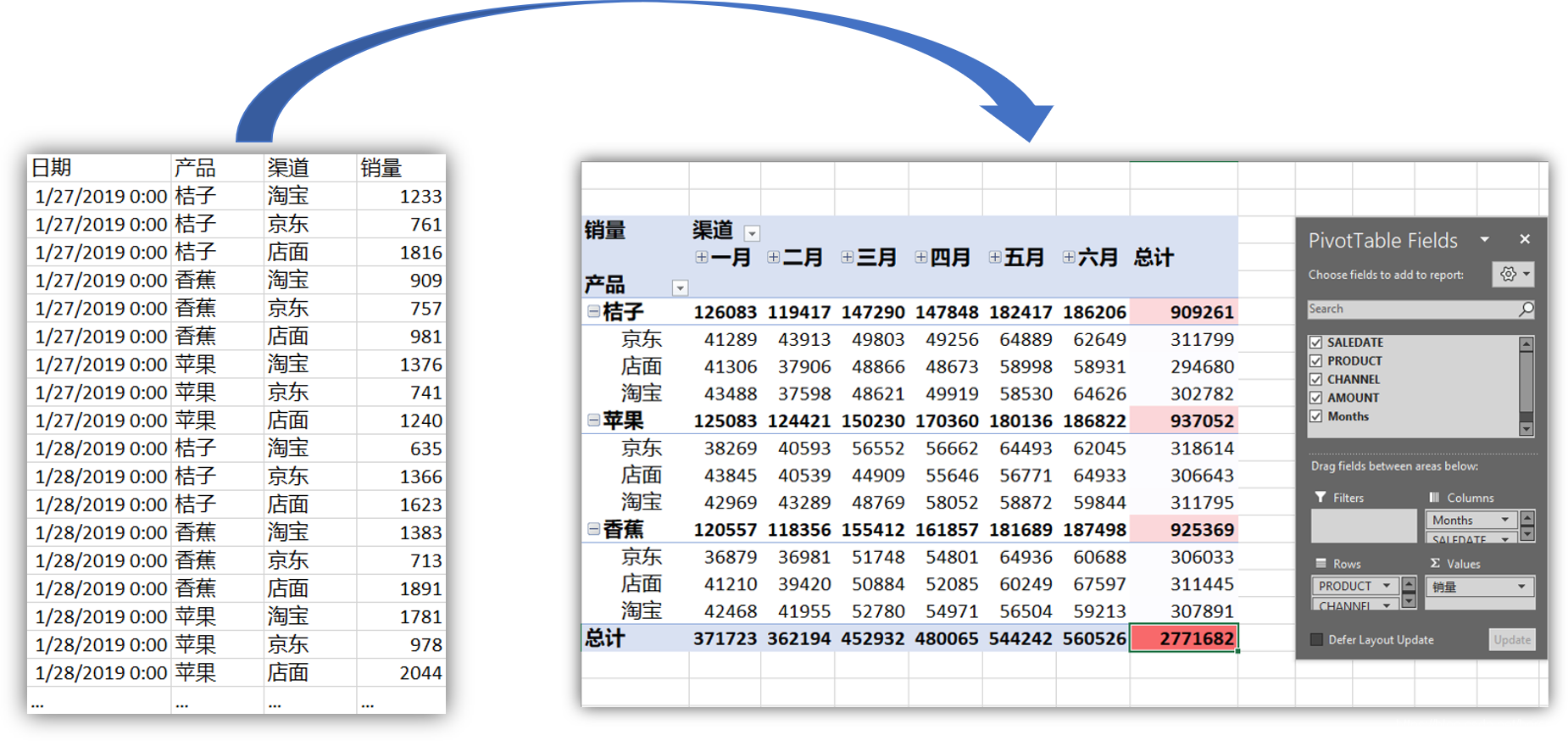
大家好,我是只谈技术不剪发的 Tony 老师。数据透视表(Pivot Table)是 Excel 中一个非常实用的分析功能,可以用于实现复杂的数据分类汇总和对比分析,是数据分析师和运营人员必备技能之一。今天我们来谈谈如何在 Oracle 数据库中实现数据透视表。
📝本文使用的示例数据可以点此下载。
使用 CASE 表达式实现数据透视表
数据透视表的本质就是按照行和列的不同组合进行数据分组,然后对结果进行汇总;因此,它和数据库中的分组(GROUP BY)和聚合函数(COUNT、SUM、AVG 等)的功能非常类似。
我们首先使用以下 GROUP BY 子句对销售数据进行分类汇总:
select coalesce(product, '【全部产品】') "产品",
coalesce(channel, '【所有渠道】') "渠道",
coalesce(to_char(saledate, 'YYYYMM'), '【所有月份】') "月份",
sum(amount) "销量"
from sales_data
group by rollup (product,channel,to_char(saledate, 'YYYYMM'));
以上语句按照产品、渠道以及月份进行汇总;rollup 选项用于生成不同层次的小计、合计以及总计;coalesce 函数用于将汇总行中的 NULL 值显示为相应的信息。查询返回的结果如下:
产品 |渠道 |月份 |销量 |
---------|---------|-----------|-------|
桔子 |京东 |201901 | 41289|
桔子 |京东 |201902 | 43913|
桔子 |京东 |201903 | 49803|
桔子 |京东 |201904 | 49256|
桔子 |京东 |201905 | 64889|
桔子 |京东 |201906 | 62649|
桔子 |京东 |【所有月份】| 311799|
桔子 |店面 |201901 | 41306|
桔子 |店面 |201902 | 37906|
桔子 |店面 |201903 | 48866|
桔子 |店面 |201904 | 48673|
桔子 |店面 |201905 | 58998|
桔子 |店面 |201906 | 58931|
桔子 |店面 |【所有月份】| 294680|
桔子 |淘宝 |201901 | 43488|
桔子 |淘宝 |201902 | 37598|
桔子 |淘宝 |201903 | 48621|
桔子 |淘宝 |201904 | 49919|
桔子 |淘宝 |201905 | 58530|
桔子 |淘宝 |201906 | 64626|
桔子 |淘宝 |【所有月份】| 302782|
桔子 |【所有渠道】|【所有月份】| 909261|
...
香蕉 |【所有渠道】|【所有月份】| 925369|
【全部产品】|【所有渠道】|【所有月份】|2771682|
实际上,我们已经得到了数据透视表的汇总结果,只不过需要将数据按照不同月份显示为不同的列;也就是需要将行转换为列,这个功能可以使用 CASE 表达式实现:
select coalesce(product, '【全部产品】') "产品", coalesce(channel, '【所有渠道】') "渠道",
sum(case to_char(saledate, 'YYYYMM') when '201901' then amount else 0 end) "一月",
sum(case to_char(saledate, 'YYYYMM') when '201902' then amount else 0 end) "二月",
sum(case to_char(saledate, 'YYYYMM') when '201903' then amount else 0 end) "三月",
sum(case to_char(saledate, 'YYYYMM') when '201904' then amount else 0 end) "四月",
sum(case to_char(saledate, 'YYYYMM') when '201905' then amount else 0 end) "五月",
sum(case to_char(saledate, 'YYYYMM') when '201906' then amount else 0 end) "六月",
sum(amount) "总计"
from sales_data
group by rollup (product, channel);
第一个 SUM 函数中的 CASE 表达式只汇总 201901 月份的销量,其他月份销量设置为 0;后面的 SUM 函数依次类推,得到了每个月的销量汇总和所有月份的总计。
产品 |渠道 |一月 |二月 |三月 |四月 |五月 |六月 |总计 |
----------|----------|------|------|------|------|------|------|-------|
桔子 |京东 | 41289| 43913| 49803| 49256| 64889| 62649| 311799|
桔子 |店面 | 41306| 37906| 48866| 48673| 58998| 58931| 294680|
桔子 |淘宝 | 43488| 37598| 48621| 49919| 58530| 64626| 302782|
桔子 |【所有渠道】|126083|119417|147290|147848|182417|186206| 909261|
苹果 |京东 | 38269| 40593| 56552| 56662| 64493| 62045| 318614|
苹果 |店面 | 43845| 40539| 44909| 55646| 56771| 64933| 306643|
苹果 |淘宝 | 42969| 43289| 48769| 58052| 58872| 59844| 311795|
苹果 |【所有渠道】|125083|124421|150230|170360|180136|186822| 937052|
香蕉 |京东 | 36879| 36981| 51748| 54801| 64936| 60688| 306033|
香蕉 |店面 | 41210| 39420| 50884| 52085| 60249| 67597| 311445|
香蕉 |淘宝 | 42468| 41955| 52780| 54971| 56504| 59213| 307891|
香蕉 |【所有渠道】|120557|118356|155412|161857|181689|187498| 925369|
【全部产品】|【所有渠道】|371723|362194|452932|480065|544242|560526|2771682|
📝Oracle 中的 decode 函数也可以实现类似 CASE 表达式的功能。
以上实现数据透视表的方法存在一定的局限性,假如还有 7 月份到 12 月份的销量需要统计,我们就需要修改查询语句增加这部分的处理。因此,Oracle 11g 引入了一个新的子句来实现自动的行转列:PIVOT。
使用 PIVOT 子句实现数据透视表
Oracle 中的 PIVOT 子句用于将行转换为列,基本语法如下:
SELECT col1, col2, ...
FROM tbl
PIVOT (
pivot_clause,
pivot_for_clause,
pivot_in_clause
);
PIVOT 子句包含 3 个部分:
pivot_clause,定义需要汇总的数据,也就是聚合函数。例如使用 SUM(amount) 汇总销量;
pivot_for_clause,指定需要从行转换成列的字段。例如使用 for saledate 将每个月的数据显示为一列;
pivot_in_clause,指定将 pivot_for_clause 字段中的哪些数据值转换为列。例如 in (‘201901’, ‘201902’) 表示只将 201901 和 201902 两个月份的数据转换为列。
对于上文中的示例,我们可以使用以下 PIVOT 子句:
with d(saledate, product, channel, amount) as (
select to_char(saledate, 'YYYYMM'),
product,
channel,
amount
from sales_data
)
select *
from d
pivot (
sum(amount)
for saledate
in ('201901', '201902', '201903', '201904', '201905', '201906')
)
order by product, channel;
其中,PIVOT 子句按照月份对销量进行汇总并且将月份转换为列显示,返回的结果如下:
PRODUCT |CHANNEL |'201901'|'201902'|'201903'|'201904'|'201905'|'201906'|
---------|--------|--------|--------|--------|--------|--------|--------|
桔子 |京东 | 41289| 43913| 49803| 49256| 64889| 62649|
桔子 |店面 | 41306| 37906| 48866| 48673| 58998| 58931|
桔子 |淘宝 | 43488| 37598| 48621| 49919| 58530| 64626|
苹果 |京东 | 38269| 40593| 56552| 56662| 64493| 62045|
苹果 |店面 | 43845| 40539| 44909| 55646| 56771| 64933|
苹果 |淘宝 | 42969| 43289| 48769| 58052| 58872| 59844|
香蕉 |京东 | 36879| 36981| 51748| 54801| 64936| 60688|
香蕉 |店面 | 41210| 39420| 50884| 52085| 60249| 67597|
香蕉 |淘宝 | 42468| 41955| 52780| 54971| 56504| 59213|
接下来我们需要增加一个总计行和总计列,为此可以先将 sales_data 数据进行分组统计然后再使用 PIVOT 子句进行转换:
with d(saledate, product, channel, amount) as (
select to_char(saledate, 'YYYYMM'),
product,
channel,
sum(amount)
from sales_data
group by rollup (to_char(saledate, 'YYYYMM'), product, channel)
), pt as (
select *
from d
pivot (
sum(amount)
for saledate
in ('201901' s01, '201902' s02, '201903' s03, '201904' s04, '201905' s05, '201906' s06)
)
)
select coalesce(product, '【全部产品】') "产品",
coalesce(channel, '【所有渠道】') "渠道",
s01 "一月", s02 "二月", s03 "三月", s04 "四月", s05 "五月", s06 "六月",
s01+s02+s03+s04+s05+s06 "总计"
from pt
order by product, channel;
我们在 PIVOT 子句返回的结果之上增加了一个 SELECT 查询,并且修改了返回字段的名称,让结果更加接近 EXCEL 数据透视表:
产品 |渠道 |一月 |二月 |三月 |四月 |五月 |六月 |总计 |
----------|----------|------|------|------|------|------|------|-------|
桔子 |京东 | 41289| 43913| 49803| 49256| 64889| 62649| 311799|
桔子 |店面 | 41306| 37906| 48866| 48673| 58998| 58931| 294680|
桔子 |淘宝 | 43488| 37598| 48621| 49919| 58530| 64626| 302782|
桔子 |【所有渠道】|126083|119417|147290|147848|182417|186206| 909261|
苹果 |京东 | 38269| 40593| 56552| 56662| 64493| 62045| 318614|
苹果 |店面 | 43845| 40539| 44909| 55646| 56771| 64933| 306643|
苹果 |淘宝 | 42969| 43289| 48769| 58052| 58872| 59844| 311795|
苹果 |【所有渠道】|125083|124421|150230|170360|180136|186822| 937052|
香蕉 |京东 | 36879| 36981| 51748| 54801| 64936| 60688| 306033|
香蕉 |店面 | 41210| 39420| 50884| 52085| 60249| 67597| 311445|
香蕉 |淘宝 | 42468| 41955| 52780| 54971| 56504| 59213| 307891|
香蕉 |【所有渠道】|120557|118356|155412|161857|181689|187498| 925369|
【全部产品】|【所有渠道】|371723|362194|452932|480065|544242|560526|2771682|
PIVOT 子句也可以一次执行多个聚合操作,或者按照多个字段进行分组。例如:
with d(saledate, product, channel, amount) as (
select to_char(saledate, 'YYYYMM'), product, channel, amount
from sales_data
where to_char(saledate, 'YYYYMM') in ('201901', '201902', '201903')
)
select *
from d
pivot (
sum(amount)
for (channel, saledate)
in (('淘宝','201901'), ('店面','201901'), ('京东','201901'),
('淘宝','201902'), ('店面','201902'), ('京东','201902'),
('淘宝','201903'), ('店面','201903'), ('京东','201903'))
);
PRODUCT|'淘宝'_'201901'|'店面'_'201901'|'京东'_'201901'|'淘宝'_'201902'|'店面'_'201902'|'京东'_'201902'|'淘宝'_'201903'|'店面'_'201903'|'京东'_'201903'|
-------|--------------|--------------|--------------|--------------|--------------|--------------|--------------|--------------|--------------|
香蕉 | 42468| 41210| 36879|
41955| 39420| 36981| 52780|
50884| 51748|
桔子 | 43488| 41306|
41289| 37598| 37906| 43913|
48621| 48866| 49803|
苹果 | 42969|
43845| 38269| 43289| 40539|
40593| 48769| 44909| 56552|
以上查询返回了按照渠道和月份分组的汇总结果,并且将它们转换为列进行显示。
与 PIVOT 相反的操作是 UNPIVOT,它可以将列转换为行。我们通过以下示例将行专列之后的数据再转换回来:
with d(saledate, product, channel, amount) as (
select to_char(saledate, 'YYYYMM'),
product,
channel,
amount
from sales_data
),
pt as (
select *
from d
pivot (
sum(amount)
for saledate
in ('201901' "201901", '201902' "201902", '201903' "201903", '201904' "201904", '201905' "201905", '201906' "201906")
)
)
select * from pt
unpivot (
amount
for saledate
IN ("201901", "201902", "201903", "201904", "201905", "201906")
);
其中,unpivot 子句也有三个选项,将每个月份代表的列转换为 saledate 字段中的行,并且将对应的数据转换为 amount 字段中的行。以上查询返回的结果如下:
PRODUCT |CHANNEL |SALEDATE|AMOUNT|
--------|--------|--------|------|
桔子 |京东 |201901 | 41289|
桔子 |京东 |201902 | 43913|
桔子 |京东 |201903 | 49803|
桔子 |京东 |201904 | 49256|
桔子 |京东 |201905 | 64889|
桔子 |京东 |201906 | 62649|
香蕉 |店面 |201901 | 41210|
香蕉 |店面 |201902 | 39420|
香蕉 |店面 |201903 | 50884|
香蕉 |店面 |201904 | 52085|
香蕉 |店面 |201905 | 60249|
香蕉 |店面 |201906 | 67597|
...
📝如果想要解锁更多的 PIVOT 和 UNPIVOT 的使用姿势,可以参考官方文档中的定义和示例。
使用 MODEL 子句实现数据透视表
除了 PIVOT 子句之外,Oracle 还提供一个更加强大的功能:MODEL 子句。简单来说,MODEL 子句可以实现 EXCEL 等电子表格中基于位置和符号的单元格引用以及复杂的公式计算。
完整的 MODEL 子句比较复杂,我们直接看一个示例:
with d(saledate, product, channel, amount) as (
select to_char(saledate, 'YYYYMM'), product, channel, sum(amount)
from sales_data
group by rollup (to_char(saledate, 'YYYYMM'), product, channel)
)
select coalesce(product, '【全部产品】') "产品",
coalesce(channel, '【所有渠道】') "渠道",
s201901 "一月", s201902 "二月", s201903 "三月", s201904 "四月", s201905 "五月", s201906 "六月",
stotal "总计"
from d
model
return updated rows
partition by (product, channel)
dimension by (saledate)
measures (amount, 0 s201901, 0 s201902, 0 s201903, 0 s201904, 0 s201905, 0 s201906, 0 stotal)
unique dimension
rules upsert all
(s201901[0] = amount['201901'],
s201902[0] = amount['201902'],
s201903[0] = amount['201903'],
s201904[0] = amount['201904'],
s201905[0] = amount['201905'],
s201906[0] = amount['201906'],
stotal[0] = sum(amount)[saledate between '201901' and '201906'])
order by product, channel;
首先,通过 with 子句获得基本数据。然后使用 model 子句实现行专列;return updated rows 表示只返回计算模型更新和插入的数据,partition by 用于定义分区(产品和渠道),每个分区独立计算;dimension by 指定度量的维度(月份);measures 定义度量,amount 来自源表,0 s201901 表示创建一个度量 s201901 并初始化为 0;unique dimension 表示 partition by 加 dimension by 字段可以唯一确定模型中的每个单元格;rules 用于定义给每个度量赋值的表达式,upsert all 表示更新已有的单元格,如果不存在则创建单元格;s201901[0] 是通过位置对单元格的引用(维度为 1),amount[‘201901’] 表示月份 201901 对应的 amount 字段值,stotal[0] 是所有月份的总和。
以上语句返回的结果如下:
产品 |渠道 |一月 |二月 |三月 |四月 |五月 |六月 |总计 |
----------|----------|------|------|------|------|------|------|-------|
桔子 |京东 | 41289| 43913| 49803| 49256| 64889| 62649| 311799|
桔子 |店面 | 41306| 37906| 48866| 48673| 58998| 58931| 294680|
桔子 |淘宝 | 43488| 37598| 48621| 49919| 58530| 64626| 302782|
桔子 |【所有渠道】|126083|119417|147290|147848|182417|186206| 909261|
苹果 |京东 | 38269| 40593| 56552| 56662| 64493| 62045| 318614|
苹果 |店面 | 43845| 40539| 44909| 55646| 56771| 64933| 306643|
苹果 |淘宝 | 42969| 43289| 48769| 58052| 58872| 59844| 311795|
苹果 |【所有渠道】|125083|124421|150230|170360|180136|186822| 937052|
香蕉 |京东 | 36879| 36981| 51748| 54801| 64936| 60688| 306033|
香蕉 |店面 | 41210| 39420| 50884| 52085| 60249| 67597| 311445|
香蕉 |淘宝 | 42468| 41955| 52780| 54971| 56504| 59213| 307891|
香蕉 |【所有渠道】|120557|118356|155412|161857|181689|187498| 925369|
【全部产品】|【所有渠道】|371723|362194|452932|480065|544242|560526|2771682|
MODEL 子句允许通过分区(PARTITION BY)和维度(DIMENSION BY)创建一个多维数组,并且通过指定规则(RULES)来操作和更新数组中单元格中的度量值(MEASURES)。其中,规则支持通配符和循环迭代,度量可以使用聚合函数和窗口函数。
MODEL 子句完整的使用姿势请参考官方文档。
如果觉得文章对你有用,欢迎关注❤️、评论📝、点赞👍! 分类导航
分类导航