

 个人中心
个人中心 退出
退出




《MySQL 性能优化》之覆盖索引不是索引
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
覆盖索引
优化示例
总结
大家好,我是只谈技术不剪发的 Tony 老师。
今天我们来讨论一个特殊的性能优化技术:覆盖索引。
如果觉得文章有用,欢迎评论📝、点赞👍、推荐🎁
覆盖索引
在某些情况下,查询语句通过索引访问就可以返回所需的结果,不需要访问表中的数据,此时我们把这个索引称为覆盖索引(Covering Index)。某些数据库中称之为 Index Only Scan。
准确来说,覆盖索引是优化器选择的一种执行计划;或者也可以说,任何索引在某种情况下都可能称为覆盖索引。
显然,覆盖索引减少了表的访问(磁盘 IO 访问),在某些情况下可以明显提高查询的性能。InnoDB 存储引擎比 MyISAM 存储引擎可以获得更多的优化提升,因为它的辅助索引存储的是主键字段,覆盖索引避免了回表操作(通过主键访问表中的数据)。不过,InnoDB 无法针对正在被其他事务修改数据的表应用这一优化技术,必须等待其他事务的结束。
优化示例
我们首先创建一个测试表 test 和一些数据:
CREATE TABLE test(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
col1 INT,
col2 INT,
col3 INT
) ENGINE = InnoDB;
SET SESSION cte_max_recursion_depth = 999999;
INSERT INTO test(col1, col2, col3)
WITH RECURSIVE d AS (
SELECT 1 n, 1000*rand() c1, 1000*rand() c2, 1000*rand() c3
UNION ALL
SELECT n+1, 1000*rand(), 1000*rand(), 1000*rand()
FROM d
WHERE n<10000
)
SELECT c1, c2, c3 FROM d;
除了主键之外,test 表上没有其他索引。
现在我们通过 col1 字段查询数据:
EXPLAIN
SELECT col1, col3
FROM test
WHERE col1 = 100;
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra |
--|-----------|-----|----------|----|-------------|---|-------|---|----|--------|-----------|
1|SIMPLE |test | |ALL | | | | |9991| 10.0|Using where|
由于缺少索引,MySQL 只能选择全表扫描。为了优化以上查询,我们可以在 col1 字段上创建一个索引:
CREATE INDEX idx_test_col1 USING BTREE ON test(col1);
然后再次执行以上查询:
EXPLAIN format=json
SELECT col1, col3
FROM test
WHERE col1 = 100;
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "3.50"
},
"table": {
"table_name": "test",
"access_type": "ref",
"possible_keys": [
"idx_test_col1"
],
"key": "idx_test_col1",
"used_key_parts": [
"col1"
],
"key_length": "5",
"ref": [
"const"
],
"rows_examined_per_scan": 10,
"rows_produced_per_join": 10,
"filtered": "100.00",
"cost_info": {
"read_cost": "2.50",
"eval_cost": "1.00",
"prefix_cost": "3.50",
"data_read_per_join": "240"
},
"used_columns": [
"col1",
"col3"
]
}
}
}
此时,MySQL 选择了通过索引 idx_test_col1 查找数据。
如果我们想要使用覆盖索引进一步优化以上查询,可以基于 col1 和 col3 创建一个复合索引:
CREATE INDEX idx_test_col1col3 USING BTREE ON test(col1, col3);
再次查看执行计划:
EXPLAIN format=json
SELECT col1, col3
FROM test
WHERE col1 = 100;
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1.95"
},
"table": {
"table_name": "test",
"access_type": "ref",
"possible_keys": [
"idx_test_col1",
"idx_test_col1col3"
],
"key": "idx_test_col1col3",
"used_key_parts": [
"col1"
],
"key_length": "5",
"ref": [
"const"
],
"rows_examined_per_scan": 10,
"rows_produced_per_join": 10,
"filtered": "100.00",
"using_index": true,
"cost_info": {
"read_cost": "0.95",
"eval_cost": "1.00",
"prefix_cost": "1.95",
"data_read_per_join": "240"
},
"used_columns": [
"col1",
"col3"
]
}
}
}
索引 idx_test_col1col3 中存储了查询所需的全部数据,因此可以实现覆盖索引,或者索引覆盖查询。执行计划输出可以看出,query_cost 从之前的 3.50 下降到了 1.95(减少了 44%),“using_index”: true 表示只需要访问索引就可以返回查询结果。
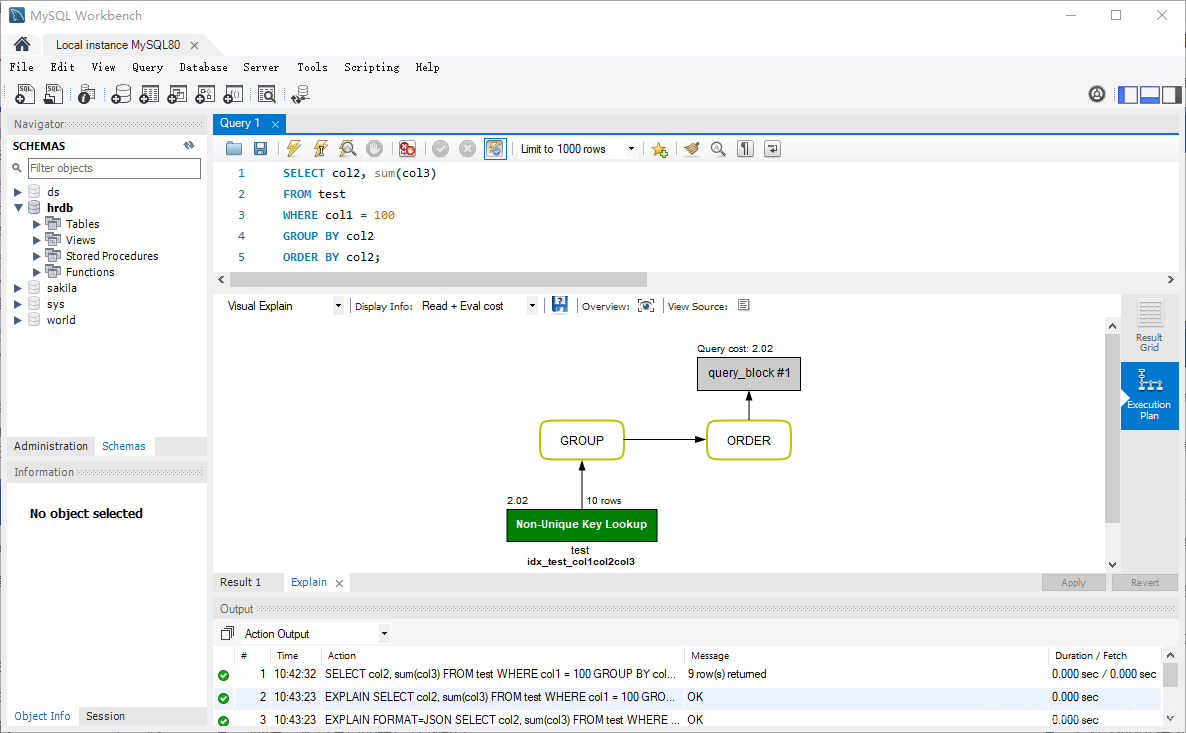
我们再来看一个查询示例:
EXPLAIN -- format=json
SELECT col2, sum(col3)
FROM test
WHERE col1 = 100
GROUP BY col2
ORDER BY col2;
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra |
--|-----------|-----|----------|----|-------------------------------|-------------|-------|-----|----|--------|-------------------------------|
1|SIMPLE |test | |ref |idx_test_col1,idx_test_col1col3|idx_test_col1|5 |const| 10| 100.0|Using temporary; Using filesort|
以上查询使用 col1 字段作为条件,同时按照 col2 字段进行分组,统计 col3 字段的和值,最后基于 col2 字段进行排序。虽然可以通过索引 idx_test_col1 查找数据,但是仍然需要回表以及额外的排序。
为了优化以上查询语句,我们可以将 col1、col2 以及 col3 一起创建一个复合索引:
CREATE INDEX idx_test_col1col2col3 USING BTREE ON test(col1, col2, col3);
注意,创建复合索引时字段的顺序一般是 WHERE 子句中的字段、GROUP BY 以及 ORDER BY 子句中的字段,最后才是 SELECT 列表中的其他字段。
此时,查询语句的执行计划如下:
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra |
--|-----------|-----|----------|----|-----------------------------------------------------|---------------------|-------|-----|----|--------|-----------|
1|SIMPLE |test | |ref |idx_test_col1,idx_test_col1col3,idx_test_col1col2col3|idx_test_col1col2col3|5 |const| 10| 100.0|Using index|
此时查询同样可以利用覆盖索引进行优化。
通过以上示例可以看出,为了实现覆盖索引,我们必须将查询涉及的字段全部添加到索引中。这样一来可能会导致另一个问题,那就是索引需要占用更多的磁盘空间和维护成本,当表的数据量很大时尤其如此。另外,覆盖索引通常只能用于优化特定的查询语句,大多数情况下查询可能不能满足覆盖条件。
最后,任何索引都有可能成为覆盖索引,例如:
EXPLAIN -- format=json
SELECT id
FROM test
WHERE col1 = 100;
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra |
--|-----------|-----|----------|----|-----------------------------------------------------|---------------------|-------|-----|----|--------|-----------|
1|SIMPLE |test | |ref |idx_test_col1,idx_test_col1col3,idx_test_col1col2col3|idx_test_col1col2col3|5 |const| 10| 100.0|Using index|
EXPLAIN -- format=json
SELECT count(*)
FROM test
WHERE col1 = 100;
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra |
--|-----------|-----|----------|----|-----------------------------------------------------|---------------------|-------|-----|----|--------|-----------|
1|SIMPLE |test | |ref |idx_test_col1,idx_test_col1col3,idx_test_col1col2col3|idx_test_col1col2col3|5 |const| 10| 100.0|Using index|
MySQL 二级索引中包含了主键 id 的数值,因此第一个查询可以使用覆盖索引。第二个查询只需要统计字段 col1 的数量,也可以使用覆盖索引。
总结
利用覆盖索引技术,MySQL 只需要访问索引就可以得到查询所需要的数据,不需要访问表中的数据。覆盖索引可以用于优化某些情况下的查询语句。
 分类导航
分类导航