

 个人中心
个人中心 退出
退出




【总结】数据库自增字段的 3 种实现方式
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
在设计数据库的表结构时,经常会使用一个自动增长的数字序列作为主键字段(代理主键)。除了作为主键使用之外,自增字段也可以用于记录各个操作发生的先后顺序,因为它具有递增特性。当我们插入一行数据时,数据库会为自增字段生成一个新的数值。
我们今天的主题就是自增字段的实现,下表列出了主流数据库中创建自增字段的几种方法:
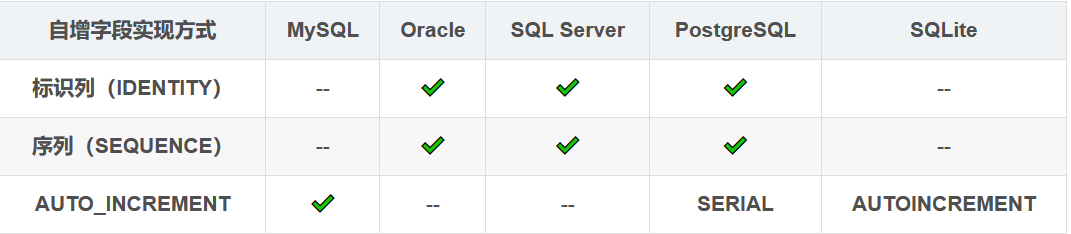
接下来我们针对不同的数据库进行详细讨论。
MySQL
AUTO_INCREMENT
MySQL 通过 AUTO_INCREMENT 属性定义自增字段,并且需要遵循以下规则:
每个表只能有一个自增字段,数据类型一般是整数;
自增字段必须创建主键(PRIMARY KEY)或者唯一索引(UNIQUE);
自增字段必须非空(NOT NULL),MySQL 会自动为自增字段设置非空约束。
以下语句创建了一个表 users,其中 user_id 是一个自增主键字段:
create table users(
user_id INT AUTO_INCREMENT PRIMARY KEY,
user_name VARCHAR(50) NOT NULL,
email VARCHAR(100)
);
接下来我们插入两条数据:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
在上面的插入语句中,我们没有指定 user_id 的值,此时 MySQL 会自动为该字段生成一个递增序列值。AUTO_INCREMENT 字段的值默认从 1 开始,每次递增也是 1。
如果插入数据时为自增字段指定了 NULL 值或者 0,MySQL 同样会自动生成一个序列值。
insert into users(user_id, user_name, email) values (null, ‘u3’, ‘u3@test.com’);
insert into users(user_id, user_name, email) values (0, ‘u4’, ‘u4@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
3|u3 |u3@test.com|
4|u4 |u4@test.com|
如果插入数据时为自增字段指定了非空也非 0 的值,MySQL 会使用我们提供的值;而且还会将自增序列的起始值值设置为该值,可能导致自增字段值的跳跃。
insert into users(user_id, user_name, email) values (100, ‘u5’, ‘u5@test.com’);
insert into users(user_name, email) values (‘u6’, ‘u6@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
3|u3 |u3@test.com|
4|u4 |u4@test.com|
100|u5 |u5@test.com|
101|u6 |u6@test.com|
上面的第一个插入语句为 user_id 提供了值 100,第二个插入语句使用系统提供的自增序列值,此时跳跃到了 101。
📝MySQL 提供了 LAST_INSERT_ID 函数,用于获取最后一次生成的序列值。
另外,MySQL 也可以使用ALTER TABLE语句设置自增序列的值:
ALTER TABLE users AUTO_INCREMENT = 200;
insert into users(user_name, email) values (‘u7’, ‘u7@test.com’);
select * from users where user_name = ‘u7’;
| user_id | user_name |
|---|
200|u7 |u7@test.com|
最后我们来看一个问题,当自增序列到达最大值之后怎么办。下面的语句演示了这种情况:
ALTER TABLE users AUTO_INCREMENT = 2147483647;
insert into users(user_name, email) values (‘u8’, ‘u8@test.com’);
insert into users(user_name, email) values (‘u9’, ‘u9@test.com’);
SQL Error [1062] [23000]: Duplicate entry ‘2147483647’ for key ‘users.PRIMARY’
先将 AUTO_INCREMENT 的值设置为 INT 类型的最大值;然后插入两条数据,第二个插入语句出现主键值重复,意味着自增字段到达最大值之后一直保持不变。
如果担心自增字段的值不够用,可以将 INT 类型改成 INT UNSIGNED,最大值可以到达 4294967295( 2 32 2^{32} 232 - 1);还不够的话改成 BIGINT,最大值可以到达 9223372036854775807( 2 63 2^{63} 263 - 1)。
📝MySQL 中的 SERIAL 是 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE 的同义词。
参考文档:MySQL 官方文档 AUTO_INCREMENT。
Oracle
Oracle 数据库提供了两种创建自增字段的方法:
使用标识列(IDENTITY),需要使用 Oracle 12c 以上版本;
使用序列(SEQUENCE)。标识列
Oracle 12c 提供创建 SQL 标准定义的标识列功能:
GENERATED [ ALWAYS | BY DEFAULT [ ON NULL ] ]
AS IDENTITY [ ( identity_options ) ]
其中,
GENERATED ALWAYS表示总是为标识列使用 Oracle 生成的值,如果用户指定该字段的值将会出错;
GENERATED BY DEFAULT表示如果用户没有提供值,使用 Oracle 生成的值;如果提供了值,使用用户提供的值;如果指定了 NULL 值将会出错;
GENERATED BY DEFAULT ON NULL表示如果用户没有提供值或者提供了 NULL 值,使用 Oracle 生成的值;否则使用用户提供的值。
Oracle 中的标识列实际上是一个内部创建序列对象,因此 identity_options 与序列的属性类似,主要包括:
START WITH n指定序列的初始值,默认为 1;
INCREMENT BY n指定序列的增量值,默认为 1;
MAXVALUE n和MINVALUE n指定序列的最大值和最小值,默认值为 9999999999999999999999999999 和 1;
CYCLE和NOCYCLE指定是否循环使用序列中的值,默认不循环使用;
CACHE n和NOCACHE指定是否缓存序列值,缓存可以提高性能。默认缓存 20 个。
以下语句创建了一个表 users,其中 user_id 是一个自增主键字段:
create table users(
user_id NUMBER GENERATED BY DEFAULT AS IDENTITY INCREMENT BY 10 START WITH 100 PRIMARY KEY,
user_name VARCHAR2(50) NOT NULL,
email VARCHAR2(100)
);
其中,INCREMENT BY 10 表示每次增量为 10;START WITH 100 表示序列值从 100 开始。
我们测试一下数据插入:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| USER_ID | USER_NAME |
|---|
100|u1 |u1@test.com|
110|u2 |u2@test.com|
我们没有使用GENERATED BY DEFAULT ON NULL选项,如果插入 NULL 值将会出错:
insert into users(user_id, user_name, email) values (null, ‘u3’, ‘u3@test.com’);
SQL Error [1400] [23000]: ORA-01400: cannot insert NULL into (“TONY”.“USERS”.“USER_ID”)
不过,我们可以为 user_id 指定非空的值:
insert into users(user_id, user_name, email) values (0, ‘u4’, ‘u4@test.com’);
select * from users;
| USER_ID | USER_NAME |
|---|
100|u1 |u1@test.com|
110|u2 |u2@test.com|
0|u4 |u4@test.com|
Oracle 标识列需要遵循以下限制:
每个表只能有一个标识列;
标识列的数据类型必须是数字类型,不能使用自定义类型;
CREATE TABLE AS SELECT语句不会继承标识列;
标识列不能指定 DEFAULT 约束。
参考文档:Oracle 官方文档 CREATE TABLE 语句。
序列
序列(Sequence)是数据库中的一种对象,用于生成一系列递增或递减的数字。序列使用CREATE SEQUENCE语句创建:
CREATE SEQUENCE seq_users;
以上语句使用默认选项创建了一个序列 seq_users,等价于下面的语句:
CREATE SEQUENCE seq_users
START WITH 1
INCREMENT BY 1
NOMAXVALUE
NOMINVALUE
CACHE 20
NOCYCLE;
Oracle 序列的数据类型为 NUMBER,包含一个最小值,一个最大值,一个起始值,一个增量值,缓存选项以及一个循环使用选项。这些参数的作用可以参考上面的标识列。
创建之后,我们可以使用 NEXTVAL 和 CURRVAL 伪列获取序列的值:
SELECT seq_users.nextval FROM dual;
| NEXTVAL |
|---|
1|
SELECT seq_users.currval FROM dual;
| CURRVAL |
|---|
1|
NEXTVAL 用于从序列中获取下一个值,CURRVAL 返回了当前会话最后一次获取的序列值。
利用序列,我们可以为表中的字段生成不重复的数值:
create table users(
user_id NUMBER PRIMARY KEY,
user_name VARCHAR2(50) NOT NULL,
email VARCHAR2(100)
);
insert into users(user_id, user_name, email) values (seq_users.nextval, ‘u1’, ‘u1@test.com’);
insert into users(user_id, user_name, email) values (seq_users.nextval, ‘u2’, ‘u2@test.com’);
select * from users;
| USER_ID | USER_NAME |
|---|
2|u1 |u1@test.com|
3|u2 |u2@test.com|
在上面的示例中,我们手动为 user_id 字段指定了 seq_users.nextval 值。如果想要实现自增字段的效果,可以利用触发器实现:
CREATE OR REPLACE TRIGGER tri_user_insert
BEFORE INSERT ON users
FOR EACH ROW
DECLARE
BEGIN
IF (:NEW.user_id IS NULL) THEN
SELECT seq_users.nextval INTO :NEW.user_id FROM dual;
END IF;
END;
该触发器在插入数据之前判断 user_id 是否为空,如果为空就生成一个新的序列号。我们再插入一些数据:
insert into users(user_id, user_name, email) values (null, ‘u3’, ‘u3@test.com’);
insert into users(user_name, email) values (‘u4’, ‘u4@test.com’);
select * from users;
| USER_ID | USER_NAME |
|---|
2|u1 |u1@test.com|
3|u2 |u2@test.com|
4|u3 |u3@test.com|
5|u4 |u4@test.com|
上面两个插入语句都没有为 user_id 提供数据,而是由触发器自动生成一个数字编号。
另一个更简单的方式就是将字段的默认值设置为序列的值:
create table users(
user_id NUMBER DEFAULT seq_users.nextval PRIMARY KEY,
user_name VARCHAR2(50) NOT NULL,
email VARCHAR2(100)
);
实际上,Oracle 中的标识列就是采用这种方法实现的,只不过增加了一些额外的限制而已。
Oracle 提供了ALTER SEQUENCE语句,可以修改序列的属性:
ALTER SEQUENCE seq_users
INCREMENT BY 2
MAXVALUE 10000
CYCLE;
以上语句将序列 seq_users 的增量修改为 2,最大值修改为 10000,并且再到达最大值之后再次从最小值开始循环。不过,Oracle 序列不能修改起始值(START WITH),只能使用DROP SEQUENCE seq_name;语句删除序列再重建创建。
参考文档:Oracle 官方文档 CREATE SEQUENCE 语句。
SQL Server
Microsoft SQL Server 提供了两种创建自增字段的方法:
使用标识列(IDENTITY);
使用序列(SEQUENCE)。
标识列
SQL Server 支持为字段指定 IDENTITY(start, increment) 属性的方法定义一个标识列,start 表示序列的起始值,increment 表示每次的增量值。例如:
create table users(
user_id int identity primary key,
user_name varchar(50) not null,
email varchar(100)
);
其中,user_id 是一个 INTEGER 类型的标识列;系统生成的序列值默认从 1 开始,每次递增也是 1。SQL Server 中每个表只能定义一个标识列。
我们插入一些测试数据:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
以上语句通过标识列自动生成了两个用户编号。我们可以利用获取最后一次插入的标识列的值:
select @@identity;
需要注意的是,不能为标识列指定 NULL 值;默认也不能为标识列手动指定值。
insert into users(user_id, user_name, email) values (null, ‘u3’, ‘u3@test.com’);
SQL Error [339] [S0001]: DEFAULT or NULL are not allowed as explicit identity values.
insert into users(user_id, user_name, email) values (0, ‘u4’, ‘u4@test.com’);
SQL Error [544] [S0001]: Cannot insert explicit value for identity column in table ‘users’ when IDENTITY_INSERT is set to OFF.
第一个语句为 user_id 指定了 NULL 值;第二个语句的错误在于为 user_id 指定了明确的值,不过可以通过设置表的 IDENTITY_INSERT 属性修改默认行为。
参考文档:SQL Server 官方文档 CREATE TABLE 语句。
序列
SQL Server 提供了和 Oracle 类似的序列对象,用于生成一个递增或递减的数字序列。创建序列的完整语法如下:
CREATE SEQUENCE sequence_name
[ AS integer_type ]
[ START WITH ]
[ INCREMENT BY ]
[ { MINVALUE [ ] } | { NO MINVALUE } ]
[ { MAXVALUE [ ] } | { NO MAXVALUE } ]
[ CYCLE | { NO CYCLE } ]
[ { CACHE [ ] } | { NO CACHE } ];
其中,
sequence_name 是序列名;
AS 定义了序列的类型。默认为 BIGINT,也可以是 TINYINT、SMALLINT、INT 或者不带小数位的 DECIMAL 和 NUMERIC;
START WITH 定义了序列的起始值,默认为 integer_type 类型的最小值;
INCREMENT BY 指定了序列的增量值,可以是负数,默认为 1;
MINVALUE 和 MAXVALUE 分别定义序列的最小值和最大值,默认为 integer_type 类型的最小值和最大值;
CYCLE 表示循环使用序列的值,默认为 NO CYCLE;
CACHE 表示缓存的序列值个数,可以提高访问性能。默认不缓存。
以下语句使用默认值创建一个序列 seq_users:
create sequence seq_users;
使用 NEXT VALUE FOR 函数获取一个序列的值:
select next value for seq_users;
|
--------------------|
-9223372036854775808|
返回的是 INTEGR 类型的最小值。
我们可以将字段的默认值设置为序列的 NEXT VALUE FOR 函数值,实现自增效果:
create table users(
user_id bigint default next value for seq_users primary key,
user_name varchar(50) not null,
email varchar(100)
);
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name | |
|---|---|---|
| -9223372036854775806 | u1 | u1@test.com |
| -9223372036854775805 | u2 | u2@test.com |
ALTER SEQUENCE语句可以修改序列的属性,参数与CREATE SEQUENCE类似,除了 integer_type 之外的参数都可以修改。例如:
alter sequence seq_users restart with 1;
insert into users(user_name, email) values (‘u3’, ‘u3@test.com’);
select * from users;
| user_id | user_name | |
|---|---|---|
| -9223372036854775807 | u1 | u1@test.com |
| -9223372036854775806 | u2 | u2@test.com |
1|u3 |u3@test.com|
参考文档:SQL Server 官方文档-序列。
PostgreSQL
PostgreSQL 提供了多种方法实现自增字段,包括:
标识列(IDENTITY),PostgreSQL 10 以及更高版本;
序列(SEQUENCE);
SERIAL。
标识列
PostgreSQL 实现了 SQL 标准中的标识列,语法与 Oracle 几乎相同:
column_name data_type GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY[ ( sequence_option ) ]
其中,
data_type 可以是 SMALLINT、INT或者 BIGINT 等整数类型;
GENERATED ALWAYS表示总是使用 PostgreSQL 生成的值,如果用户指定该字段的值将会出错,除非指定了 OVERRIDING SYSTEM VALUE 选项;
GENERATED BY DEFAULT表示如果用户没有提供值,使用 PostgreSQL 生成的值;如果提供了值,使用用户的值;
sequence_option 用于指定序列对象的选项。PostgreSQL 标识列实际上使用一个内部的序列对象来实现,具体选项参考下文中的序列。
以下语句创建了一个表 users,其中 user_id 是一个标识列:
create table users(
user_id int generated always as identity primary key,
user_name varchar(50) not null,
email varchar(100)
);
此时,PostgreSQL 自动创建了一个序列对象 users_user_id_seq。我们测试一下数据插入:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
标识列默认从 1 开始,每次递增也是 1。
如果我们为 user_id 指定明确的值:
insert into users(user_id, user_name, email) values (3, ‘u3’, ‘u3@test.com’);
SQL Error [428C9]: ERROR: cannot insert into column “user_id”
Detail: Column “user_id” is an identity column defined as GENERATED ALWAYS.
Hint: Use OVERRIDING SYSTEM VALUE to override.
该语句执行错误,不过我们可以使用INSERT语句的 OVERRIDING SYSTEM VALUE 选项覆盖系统提供的值。
参考文档:PostgreSQL 官方文档 CREATE TABLE 语句。
序列
与 Oracle 和 SQL Server 类似,PostgreSQL 也实现了 SQL 标准中的序列对象。创建序列的语法如下:
CREATE SEQUENCE [ IF NOT EXISTS ] name
[ AS data_type ]
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ]
[ CACHE cache ]
[ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]
其中,
name 是序列名;
AS 定义了序列的类型。默认为 BIGINT,也可以是 SMALLINT或者 INTEGER;
INCREMENT BY 指定了序列的增量值,可以是负数,默认为 1;
MINVALUE 和 MAXVALUE 分别定义序列的最小值和最大值,默认为 integer_type 类型的最小值和最大值;
START WITH 定义了序列的起始值,默认为 integer_type 类型的最小值;
CACHE 表示缓存的序列值个数,可以提高访问性能。默认不缓存;
CYCLE 表示循环使用序列的值,默认为 NO CYCLE;
OWNED BY 用于将序列与指定表的字段关联,此时删除该字段会级联删除序列;默认为 NONE。
以下语句使用默认值创建一个序列 seq_users:
create sequence seq_users;
该语句创建了一个从 1 开始,增量为 1,最小值为 1,最大值为 ( 2 63 2^{63} 263 - 1) 的非循环序列。
PostgreSQL 使用 nextval 和 currval 函数获取一个序列的值:
select nextval(‘seq_users’);
| nextval |
|---|
1|
select currval(‘seq_users’);
| currval |
|---|
1|
我们可以将字段的默认值设置为序列的 nextval 函数值,实现自增效果:
create table users(
user_id bigint default nextval(‘seq_users’) primary key,
user_name varchar(50) not null,
email varchar(100)
);
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name |
|---|
2|u1 |u1@test.com|
3|u2 |u2@test.com|
ALTER SEQUENCE语句可以修改序列的属性,参数与CREATE SEQUENCE类似。例如:
alter sequence seq_users restart with 100;
insert into users(user_name, email) values (‘u3’, ‘u3@test.com’);
select * from users;
| user_id | user_name |
|---|
2|u1 |u1@test.com|
3|u2 |u2@test.com|
100|u3 |u3@test.com|
除此之外,使用 setval 函数也可以修改序列的值。
参考文档:PostgreSQL 官方文档 CREATE SEQUENCE 语句。
SERIAL
SERIAL 与 PostgreSQL 标识列类似,实际上是一个内部的序列对象。例如:
create table users(
user_id serial primary key,
user_name varchar(50) not null,
email varchar(100)
);
等价于:
CREATE SEQUENCE users_user_id_seq AS integer;
create table users(
user_id integer NOT NULL DEFAULT nextval(‘users_user_id_seq’) primary key,
user_name varchar(50) not null,
email varchar(100)
);
ALTER SEQUENCE users_user_id_seq OWNED BY users.user_id;
PostgreSQL 首先创建一个序列对象,并且将该序列的 nextval 值设置为字段 user_id 的默认值;然后为 user_id 字段设置 NOT NULL 约束;最后将该序列的属主设置为 user_id 字段,因此删除该字段会级联删除序列对象。
然后插入一些测试数据:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_name, email) values (‘u2’, ‘u2@test.com’);
select * from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
除了 serial 之外,PostgreSQL 还提供了 smallserial 和 bigserial,分别对应 smallint 和 bigint 数据类型。
参考文档:PostgreSQL 官方文档 SERIAL 类型。
SQLite
简单来说,在 SQLite 中不推荐使用 AUTOINCREMENT 字段。因为 SQLite 实现了一个隐式的自增字段 ROWID,很少有必要再显式指定自增字段。
ROWID
默认情况下,CREATE TABLE语句创建的表中包含一个隐式的自增字段 rowid;它是一个 64 位的有符号整数,用于唯一标识每一行数据。
首先,创建一个 users 表:
create table users(
user_name text not null,
email text
);
然后插入一些数据:
insert into users values (‘u1’, ‘u1@test.com’), (‘u2’, ‘u2@test.com’);
select rowid, user_name, email
from users;
| rowid | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
从上面的查询结果可以看出,users 表包含了一个 rowid 字段,并且自动插入了从 1 开始递增的数字。
📝 SQLite 中的 _rowid_ 和 oid 都是 rowid 的同义词。
如果在创建表时指定了 INTEGER 类型的主键字段,该字段实际上就是 rowid 的同义词。例如:
drop table users;
create table users(
user_id integer primary key,
user_name text not null,
email text
);
其中,user_id 是 INTGER 类型的主键。此时我们插入一些数据:
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_id, user_name, email) values (null, ‘u2’, ‘u2@test.com’);
select rowid, user_id, user_name, email
from users;
| user_id | user_id | user_name |
|---|
1| 1|u1 |u1@test.com|
2| 2|u2 |u2@test.com|
第一个插入语句没有指定 user_id 的值,第二个语句为 user_id 指定了 NULL 值;这两种情况下,SQLite 都会基于表中最大的 rowid 值生成一个递增数字。
rowid 最大的值为 9223372036854775807( 2 63 2^{63} 263 - 1);到达最大值之后,SQLite 会尝试复用已经被删除的数字;如果没有找到,将会提示 SQLITE_FULL 错误。
insert into users(user_id, user_name, email) values (9223372036854775807, ‘u3’, ‘u3@test.com’);
insert into users(user_name, email) values (‘u4’, ‘u4@test.com’);
select user_id, user_name, email
from users;
| user_id | user_name |
|---|
1|u1 |u1@test.com|
2|u2 |u2@test.com|
4461153425269426579|u4 |u4@test.com|
9223372036854775807|u3 |u3@test.com|
最后一个插入语句生成了一个未占用的数字作为 user_id 的值。
参考文档:SQLite 官方文档 CREATE TABLE 语句。
AUTOINCREMENT
SQLite 不推荐使用 AUTOINCREMENT 字段,因为大部分情况下都不需要,而且这种字段会消耗更多的 CPU、内存、磁盘以及 I/O。
AUTOINCREMENT 字段与系统 rowid 字段的唯一区别在于:AUTOINCREMENT 字段到达最大值之后不会重复生成未占用的数字,而是直接报错。例如:
drop table users;
create table users(
user_id integer primary key autoincrement,
user_name text not null,
email text
);
insert into users(user_name, email) values (‘u1’, ‘u1@test.com’);
insert into users(user_id, user_name, email) values (null, ‘u2’, ‘u2@test.com’);
select rowid, user_id, user_name, email
from users;
| user_id | user_id | user_name |
|---|
1| 1|u1 |u1@test.com|
2| 2|u2 |u2@test.com|
其中,user_id 字段是自增主键。我们来看一下自增字段到达最大值之后的情况:
insert into users(user_id, user_name, email) values (9223372036854775807, ‘u3’, ‘u3@test.com’);
insert into users(user_name, email) values (‘u4’, ‘u4@test.com’);
SQL Error [13]: [SQLITE_FULL] Insertion failed because database is full (database or disk is full)
最后一个插入语句执行失败,提示数据库或者磁盘已满。
参考文档:SQLite 官方文档 Autoincrement 。
 分类导航
分类导航