

 个人中心
个人中心 退出
退出




Oracle 模拟部分索引提高查询性能
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
索引与空值
模拟部分索引
实现业务约束
总结
大家好,我是只谈技术不剪发的 Tony 老师。
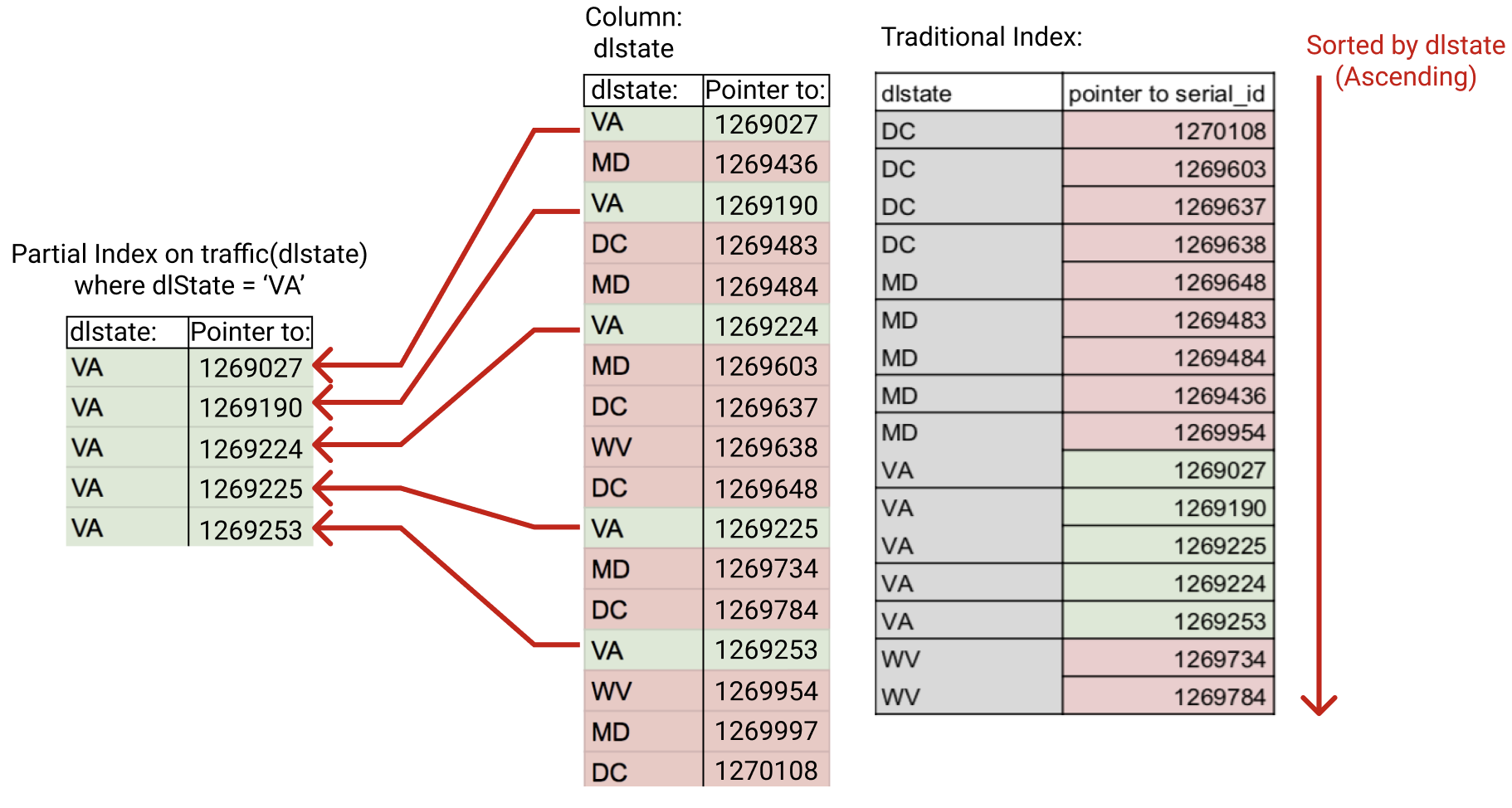
在 Oracle 数据库中,如果索引字段的取值全部为 NULL,索引中不会包含该数据行。利用这一特性,我们可以创建一个只索引满足特定条件的数据行的部分索引(partial index)。由于部分索引不需要对表中的全部数据进行索引,因此索引会更小,在特定场景下通过部分索引查找数据时性能会更好。本文就来介绍一下如何在 Oracle 中模拟部分索引。
如果觉得文章有用,欢迎评论📝、点赞👍、推荐🎁
📝Oracle 12c 中允许为分区表的部分分区创建全局索引和局部索引,也属于一种部分索引技术,具体可以参考官方文档。
索引与空值
EMPLOYEE 员工表的 MANAGER 字段上存在一个索引 IDX_EMP_MANAGER(示例表),当我们使用该字段作为条件进行查询时可以利用索引:
EXPLAIN PLAN FOR
SELECT *
FROM employee
WHERE manager = 5;
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
-------------------------------------------------------------------------------------------------------|
Plan hash value: 3813740982 |
|
-------------------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
-------------------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 4 | 224 | 2 (0)| 00:00:01 ||
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEE | 4 | 224 | 2 (0)| 00:00:01 ||
|* 2 | INDEX RANGE SCAN | IDX_EMP_MANAGER | 4 | | 1 (0)| 00:00:01 ||
-------------------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
2 - access("MANAGER"=5) |
执行计划显示该语句使用了索引范围扫描(INDEX RANGE SCAN)。但是如果想要查询没有 MANAGER 的员工时,无法利用索引进行优化:
EXPLAIN PLAN FOR
SELECT *
FROM employee
WHERE manager IS NULL;
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
------------------------------------------------------------------------------|
Plan hash value: 2119105728 |
|
------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 1 | 56 | 3 (0)| 00:00:01 ||
|* 1 | TABLE ACCESS FULL| EMPLOYEE | 1 | 56 | 3 (0)| 00:00:01 ||
------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
1 - filter("MANAGER" IS NULL) |
执行计划显示该语句使用了全表扫描(TABLE ACCESS FULL),因为索引 IDX_EMP_MANAGER 中没有相关的数据。
对于复合索引(多列索引),如果至少有一个索引字段的值不为空,就会创建相应的索引项。我们创建一个基于 DEPT_ID 和 MANAGER 字段的复合索引:
CREATE INDEX IDX_EMP_DEPT_MANAGER ON EMPLOYEE(DEPT_ID, MANAGER);
由于 DEPT_ID 字段不会为空,即使 MANAGER 为空的数据也会生成相应的索引项。再次执行上面的查询语句:
EXPLAIN PLAN FOR
SELECT *
FROM employee
WHERE manager IS NULL;
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
------------------------------------------------------------------------------------------------------------|
Plan hash value: 4053329608 |
|
------------------------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
------------------------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 1 | 56 | 2 (0)| 00:00:01 ||
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEE | 1 | 56 | 2 (0)| 00:00:01 ||
|* 2 | INDEX SKIP SCAN | IDX_EMP_DEPT_MANAGER | 1 | | 1 (0)| 00:00:01 ||
------------------------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
2 - access("MANAGER" IS NULL) |
filter("MANAGER" IS NULL) |
执行计划显示该语句使用了索引跳跃扫描(INDEX SKIP SCAN)。为了进一步优化该查询,可以将复合索引中的字段交换顺序,也就是将 MANAGER 放在最左侧:
DROP INDEX IDX_EMP_DEPT_MANAGER;
CREATE INDEX IDX_EMP_DEPT_MANAGER ON EMPLOYEE(MANAGER, DEPT_ID);
然后再次查看执行计划:
PLAN_TABLE_OUTPUT |
------------------------------------------------------------------------------------------------------------|
Plan hash value: 3287566901 |
|
------------------------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
------------------------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 1 | 56 | 2 (0)| 00:00:01 ||
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEE | 1 | 56 | 2 (0)| 00:00:01 ||
|* 2 | INDEX RANGE SCAN | IDX_EMP_DEPT_MANAGER | 1 | | 1 (0)| 00:00:01 ||
------------------------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
2 - access("MANAGER" IS NULL) |
执行计划显示该语句使用了索引范围扫描(INDEX RANGE SCAN)。索引中的 DEPT_ID 可以是其他任何非空字段,确保 MANAGER 字段为空的数据存在索引。我们甚至可以使用一个常量创建该索引:
DROP INDEX IDX_EMP_DEPT_MANAGER;
CREATE INDEX IDX_EMP_DEPT_MANAGER ON EMPLOYEE(MANAGER, 0);
以上索引实际上是一个函数索引,函数的值是常量 0。这种方式也可以实现对 NULL 值的索引。
模拟部分索引
利用 Oracle 对索引字段中 NULL 值的处理方式,我们可以模拟一个部分索引。例如,对于以下订单表 orders:
CREATE TABLE orders (
id INTEGER PRIMARY KEY,
customer_id INTEGER,
status VARCHAR(10)
);
INSERT INTO orders (id, customer_id, status)
WITH t(id, customer_id, status) AS (
SELECT 1,
floor(dbms_random.value * 10000),
CASE floor(dbms_random.value * 100)
WHEN 0 THEN 'pending'
WHEN 1 THEN 'shipped'
ELSE 'completed'
END
FROM dual
UNION ALL
SELECT id + 1,
floor(dbms_random.value * 10000),
CASE floor(dbms_random.value * 100)
WHEN 0 THEN 'pending'
WHEN 1 THEN 'shipped'
ELSE 'completed'
END
FROM t WHERE id < 1000000
)
SELECT id, customer_id, status
FROM t;
SELECT count(*) FROM orders;
COUNT(*)|
--------|
1000000|
orders 表中总共有 1000000 个订单,其中绝大部的订单都处于完成状态。通常我们只需要针对某个用户未完成的订单进行查询跟踪,因此可以创建一个基于用户编号和状态的部分索引:
CREATE INDEX full_idx ON orders (customer_id, status);
BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
OWNNAME => 'TONY',
TABNAME => 'ORDERS'
);
END;
然后查看以下语句的执行计划:
EXPLAIN PLAN FOR
SELECT *
FROM orders
WHERE customer_id = 6666
AND status != 'completed';
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
------------------------------------------------------------------------------------------------|
Plan hash value: 2146694866 |
|
------------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
------------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 2 | 38 | 5 (0)| 00:00:01 ||
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| ORDERS | 2 | 38 | 5 (0)| 00:00:01 ||
|* 2 | INDEX RANGE SCAN | FULL_IDX | 2 | | 3 (0)| 00:00:01 ||
------------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
2 - access("CUSTOMER_ID"=6666) |
filter("STATUS"<>'completed') |
执行计划输出结果显示,该语句使用了索引范围扫描(INDEX RANGE SCAN)。我们可以查看一下索引 FULL_IDX 占用的空间大小:
SELECT sum(bytes)/1024/1024 AS MB
FROM user_segments
WHERE segment_type ='INDEX'
AND segment_name = 'FULL_IDX';
MB|
--|
28|
下面我们再创建一个部分索引,只包含未完成的订单数据,从而减少索引的数据量。为此需要先创建一个函数:
CREATE OR REPLACE
FUNCTION f_order_status(status VARCHAR2, customer_id INTEGER)
RETURN INTEGER
DETERMINISTIC
AS
BEGIN
IF status != 'completed' THEN
RETURN customer_id;
ELSE
RETURN NULL;
END IF;
END;
如果输入参数 status 不等于 completed,直接返回输入参数 customer_id;否则,返回 NULL。另外,作为索引使用的函数必须指定 DETERMINISTIC 属性。
然后我们创建一个函数索引:
CREATE INDEX partial_idx ON orders (f_order_status(status, customer_id));
BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
OWNNAME => 'TONY',
TABNAME => 'ORDERS'
);
END;
索引 partial_idx 中只包含状态未完成的订单,而且只包含 customer_id 字段。然后再次查看执行计划,需要修改一下查询语句的写法:
EXPLAIN PLAN FOR
SELECT *
FROM orders
WHERE f_order_status(status, customer_id) = 6666;
SELECT * FROM TABLE(DBMS_XPLAN.display);
PLAN_TABLE_OUTPUT |
---------------------------------------------------------------------------------------------------|
Plan hash value: 2791331943 |
|
---------------------------------------------------------------------------------------------------|
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time ||
---------------------------------------------------------------------------------------------------|
| 0 | SELECT STATEMENT | | 2 | 40 | 4 (0)| 00:00:01 ||
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| ORDERS | 2 | 40 | 4 (0)| 00:00:01 ||
|* 2 | INDEX RANGE SCAN | PARTIAL_IDX | 2 | | 1 (0)| 00:00:01 ||
---------------------------------------------------------------------------------------------------|
|
Predicate Information (identified by operation id): |
--------------------------------------------------- |
|
2 - access("TONY"."F_ORDER_STATUS"("STATUS","CUSTOMER_ID")=6666) |
查询条件中使用了 f_order_status 函数返回指定用户未完成的订单。输出结果显示执行计划选择了索引 PARTIAL_IDX,而不是 FULL_IDX;因为这样性能更好,只需要扫描更少的索引记录就可以得到结果。
我们同样可以查看一下索引 PARTIAL_IDX 占用的空间大小:
SELECT sum(bytes)/1024/1024 AS MB
FROM user_segments
WHERE segment_type ='INDEX'
AND segment_name = 'PARTIAL_IDX';
MB |
------|
0.4375|
索引只有 0.4375 MB,而不是 28 MB;索引缩小到了原来的 1/64,因为绝大多数订单都处于完成状态。
实现业务约束
利用部分索引还可以用于实现其他的功能。例如,我们可以将索引 PARTIAL_IDX 定义为唯一索引,从而实现每个客户只能存在一个未完成订单的约束。
DROP INDEX partial_idx;
TRUNCATE TABLE orders;
CREATE UNIQUE INDEX partial_idx ON orders (f_order_status(status, customer_id));
INSERT INTO orders(id, customer_id, status) VALUES (1, 1, 'pending');
INSERT INTO orders(id, customer_id, status) VALUES (2, 1, 'pending');
SQL Error [1] [23000]: ORA-00001: unique constraint (TONY.PARTIAL_IDX) violated
增加唯一约束之后,客户必须完成一个订单之后才能继续创建新的订单。
总结
数据库中的部分索引只针对满足特定条件的数据进行索引,通常比普通索引更加节省空间,可以用于优化特定条件的查询。利用 Oracle 不对空值进行索引的特性可以模拟实现一个部分索引。
 分类导航
分类导航