

 个人中心
个人中心 退出
退出




5 分钟理解数据库死锁
作者: 不剪发的Tony老师
毕业于北京航空航天大学,十多年数据库管理与开发经验,目前在一家全球性的金融公司从事数据库架构设计。CSDN学院签约讲师以及GitChat专栏作者。csdn上的博客收藏于以下地址:https://tonydong.blog.csdn.net
文章目录
死锁是如何产生的?
如何解决并避免死锁
总结
🍺知人者智,自知者明。胜人者有力,胜己者强。知足者富,强行者有志。不失其所者久,死而不亡者寿。——老子
- 1
- 2
- 3
- 4
- 5
大家好!我是只谈技术不剪发的 Tony 老师。
加锁(Locking)是数据库在并发访问时保证数据一致性和完整性的主要机制。任何事务都需要获得相应对象上的锁才能访问数据,读取数据的事务通常只需要获得读锁(共享锁),修改数据的事务需要获得写锁(排他锁)。当两个事务互相之间需要等待对方释放获得的资源时,如果系统不进行干预则会一直等待下去,也就是进入了死锁(deadlock)状态。
本文给大家演示一下死锁产生的场景和解决方法,如果觉得文章有用,欢迎评论📝、点赞👍、推荐🎁
以下内容适用于各种常见的数据库管理系统,包括 Oracle、MySQL、Microsoft SQL Server 以及 PostgreSQL 等。
- 1
死锁是如何产生的?
演示死锁的产生非常简单,我们只需要创建一个包含两行数据的简单示例表:
CREATE TABLE t_lock(id int PRIMARY KEY, col int);
INSERT INTO t_lock VALUES (1, 100);
INSERT INTO t_lock VALUES (2, 200);
SELECT * FROM t_lock;
id|col|
–±--+
1|100|
2|200|
如果我们在不同事务中以不同的顺序修改数据,就可能引起事务之间的相互等待。一个事务等待另一个事务释放资源不会产生什么问题,但是如果两个事务互相等待对方的资源,数据库管理系统只有两个选择:无限等待或者中止一个事务并让另一个事务成功执行。
显然无限等待不是解决问题的方法,因此数据库通常是等待一定时间之后中止其中一个事务。
以下是一个死锁的演示案例:
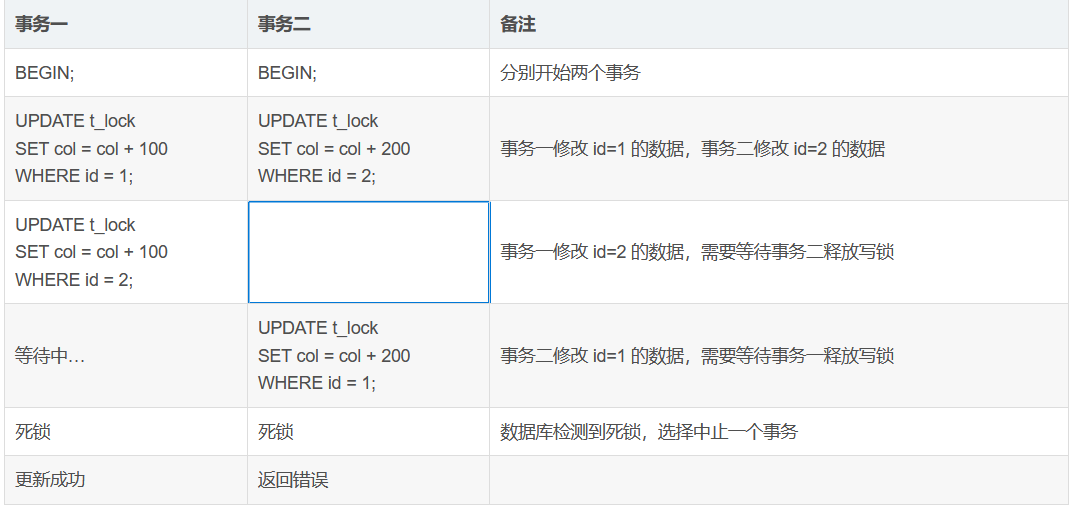
对于 MySQL InnoDB,默认启用了 innodb_deadlock_detect 选项,事务二返回以下错误信息:
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
1
- 1
如果我们禁用 InnoDB 死锁检测选项,事务二在等待 50 s(innodb_lock_wait_timeout )后提示等待超时:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
1
- 1
Oracle 检测到死锁时返回以下错误:
ORA-00060: 等待资源时检测到死锁
1
- 1
Microsoft SQL Server 检测到死锁时返回的错误如下
消息 1205,级别 13,状态 51,第 7 行
事务(进程 ID 67)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品。请重新运行该事务。
PostgreSQL 检测到死锁时返回的错误如下:
SQL 错误 [40P01]: 错误: 检测到死锁
详细:进程32等待在事务 4765上的ShareLock; 由进程16552阻塞.
进程16552等待在事务 4766上的ShareLock; 由进程32阻塞.
建议:详细信息请查看服务器日志.
在位置:当更新关系"t_lock"的元组(0, 1)时
如何解决并避免死锁
死锁不是数据库自身的问题,我们无法通过优化数据库配置来解决或者避免死锁,只能通过修改应用程序来解决。简单来说,我们应该在程序中按照相同的顺序修改数据,避免产生相互等待资源的情况发生。例如:
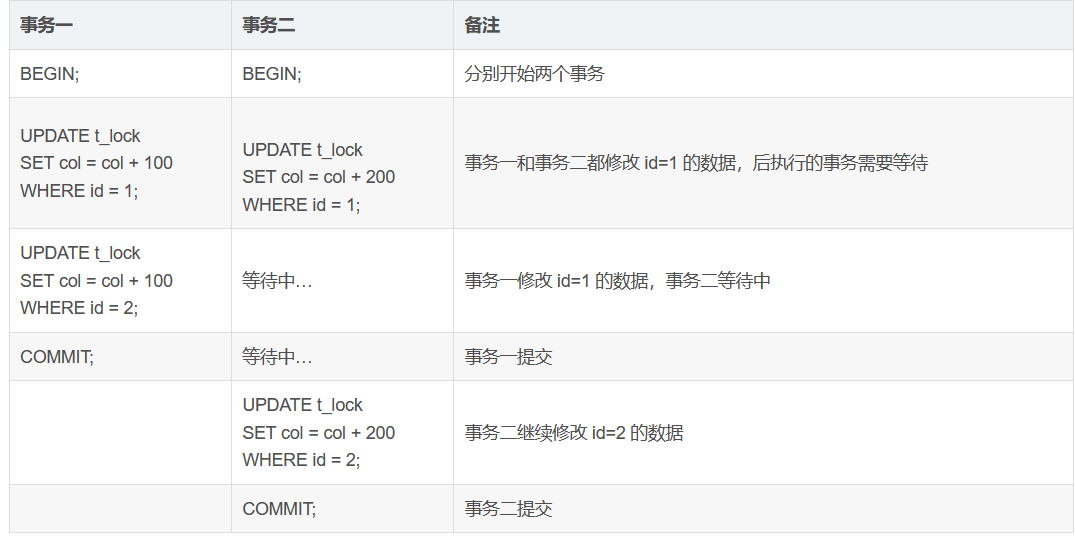
以上场景不会产生死锁。不过,我们在实际应用中可能无法完全按照相同顺序修改数据。如果出现了不可避免的死锁情况,另一种解决方法就是捕获系统返回的死锁异常并在程序中加入重试机制。
总结
本文简要介绍了数据库死锁产生的原因和解决方法。
 分类导航
分类导航