

 个人中心
个人中心 退出
退出




自然语言处理:网购商品评论情感判定
目录
自然语言处理(Natural Language Processing,简称NLP),是为各类企业及开发者提供的用于文本分析及挖掘的核心工具,旨在帮助用户高效的处理文本,已经广泛应用在电商、文娱、司法、公安、金融、医疗、电力等行业客户的多项业务中,取得了良好的效果。
1、项目背景
任何行业领域,用户对产品的评价都显得尤为重要。通过用户评论,可以对用户情感倾向进行判定。
例如,目前最为普遍的网购行为:对于用户来说,参考评论可以做出更优的购买决策;对于商家来说,对商品评论按照情感倾向进行分类,并通过文本聚类得到普遍提及的商品优缺点,可以进一步改良产品。

本案例主要讨论如何对商品评论进行情感倾向判定。下图为某电商平台上针对某款手机的部分评论:

2、数据集
这份某款手机的商品评论信息数据集,包含2个属性,共计8187个样本。

使用Pandas中的read_excel函数读取xls格式的数据集文件,注意文件的编码设置为gb18030,代码如下所示:
- import pandas as pd
-
- #读入数据集
- data = pd.read_excel("data.xls", encoding='gb18030')
- print(data.head())
读取数据集效果(部分)如下所示:

查看数据集的相关信息,包括行列数,列名,以及各个类别的样本数,实现代码如下所示:
- # 数据集的大小
- print(data.shape)
-
- # 数据集的列名
- print(data.columns.values)
-
- # 不同类别数据记录的统计
- print(data['Class'].value_counts())
效果如下所示
- (8186, 2)
-
- array([u'Comment', u'Class'], dtype=object)
-
- 1 3042
- -1 2657
- 0 2487
- Name: Class, dtype: int64
3、数据预处理
现在,我们要将Comment列的文本信息,转化成数值矩阵表示,也就是将文本映射到特征空间。
首先,通过jieba,使用HMM模型,对文本进行中文分词,实现代码如下所示:
- # 导入中文分词库jieba
- import jieba
- import numpy as np
接下来,对数据集的每个样本的文本进行中文分词,如遇到缺失值,使用“还行、一般吧”进行填充,实现代码如下所示:
- cutted = []
- for row in data.values:
- try:
- raw_words = (" ".join(jieba.cut(row[0])))
- cutted.append(raw_words)
- except AttributeError:
- print row[0]
- cutted.append(u"还行 一般吧")
-
- cutted_array = np.array(cutted)
-
- # 生成新数据文件,Comment字段为分词后的内容
- data_cutted = pd.DataFrame({
- 'Comment': cutted_array,
- 'Class': data['Class']
- })
读取并查看预处理后的数据,实现代码如下所示:
print(data_cutted.head())数据集效果(部分)如下所示:

为了更直观地观察词频高的词语,我们使用第三方库wordcloud进行文本的可视化,导入库实现代码如下所示:
- # 导入第三方库wordcloud
-
- from wordcloud import WordCloud
- import matplotlib.pyplot as plt
针对好评,中评和差评的文本,建立WordCloud对象,绘制词云,好评词云可视化实现代码如下所示:
- # 好评
- wc = WordCloud(font_path='Courier.ttf')
- wc.generate(''.join(data_cutted['Comment'][data_cutted['Class'] == 1]))
- plt.axis('off')
- plt.imshow(wc)
- plt.show()
好评词云效果如下所示:

中评词云可视化实现代码如下所示:
- # 中评
-
- wc = WordCloud(font_path='Courier.ttf')
- wc.generate(''.join(data_cutted['Comment'][data_cutted['Class'] == 0]))
- plt.axis('off')
- plt.imshow(wc)
- plt.show()
中评词云效果如下所示:

差评词云可视化实现代码如下所示:
- # 差评
-
- wc = WordCloud(font_path='Courier.ttf')
- wc.generate(''.join(data_cutted['Comment'][data_cutted['Class'] == -1]))
- plt.axis('off')
- plt.imshow(wc)
- plt.show()
差评词云效果如下所示:

从词云展现的词频统计图来看,"手机","就是","屏幕","收到"等词对于区分毫无帮助而且会造成偏差。因此,需要把这些对区分类没有意义的词语筛选出来,放到停用词文件stopwords.txt中。实现代码如下所示:
- # 读入停用词文件
- import codecs
-
- with codecs.open('stopwords.txt', 'r', encoding='utf-8') as f:
- stopwords = [item.strip() for item in f]
-
- for item in stopwords[0:200]:
- print(item,)
输出停用词效果如下所示:

使用jieba库的extract_tags函数,统计好评,中评,差评文本中的TOP20关键词。
- #设定停用词文件,在统计关键词的时候,过滤停用词
- import jieba.analyse
-
- jieba.analyse.set_stop_words('stopwords.txt')
好评关键词分析,实现代码如下所示:
- # 好评关键词
- keywords_pos = jieba.analyse.extract_tags(''.join(data_cutted['Comment']
- [data_cutted['Class'] == 1]), topK=20)
- for item in keywords_pos:
- print(item,)
好评关键词TOP20如下所示:
不错 正品 赠品 五分 发货 东西 满意 机子 喜欢 收到 很漂亮 充电 好评 很快 卖家 速度 评价 流畅 快递 物流中评关键词分析,实现代码如下所示:
- #中评关键词
- keywords_med = jieba.analyse.extract_tags(''.join(data_cutted['Comment'][data_cutted
- ['Class'] == 0]), topK=20)
- for item in keywords_med:
- print(item,)
中评关键词TOP20如下所示:
充电 不错 发热 外观 感觉 电池 机子 问题 赠品 有点 无线 发烫 换货 软件 快递 安卓 内存 退货 知道 售后差评关键词分析,实现代码如下所示:
- #差评关键词
- keywords_neg = jieba.analyse.extract_tags(''.join(data_cutted['Comment'][data_cutted
- ['Class'] == -1]), topK=20)
-
- for item in keywords_neg:
- print(item,)
差评关键词TOP20如下所示:
差评 售后 垃圾 赠品 退货 问题 换货 充电 降价 发票 充电器 东西 刚买 发热 无线 机子 死机 收到 质量 15经过以上步骤的处理,整个数据集的预处理工作“告一段落”。在中文文本分析和情感分析的工作中,数据预处理的内容主要是分词。只有经过分词处理后的文本数据集才可以进行下一步的向量化操作,满足输入模型的条件。
4、基于SVM的情感分类模型
经过分词之后的文本数据集要先进行向量化之后才能输入到分类模型中进行运算。
我们使用sklearn库实现向量化方法,去掉停用词,并将其通过tf,tf-idf映射到特征空间。

其中,tftf为词频,即分词后每个词项在该条评论中出现的次数;dfdf为出现该词项评论数目;NN为评论总数,使用对数来适当抑制tftf和dfdf值的影响。
我们使用sklearn库中的函数直接实现SVM算法。在这里,我们选取以下形式的SVM模型参与运算。

为了方便,创建文本情感分析类CommentClassifier,来实现建模过程:
__init__为类的初始化函数,输入参数classifier_type和vector_type,分别代表分类模型的类型和向量化方法的类型。fit()函数,来实现向量化与模型建立的过程。
实现代码如下所示:
- # 实现向量化方法
- from sklearn.feature_extraction.text import TfidfVectorizer
- from sklearn.feature_extraction.text import CountVectorizer
-
- #实现svm和贝叶斯模型
- from sklearn.svm import SVC
- from sklearn.svm import LinearSVC
- from sklearn.linear_model import SGDClassifier
-
-
- # 实现交叉验证
- from sklearn.cross_validation import train_test_split
- from sklearn.cross_validation import cross_val_score
-
- # 实现评价指标
- from sklearn import metrics
-
- # 文本情感分类的类:CommentClassifier
- class CommentClassifier:
- def __init__(self, classifier_type, vector_type):
- self.classifier_type = classifier_type #分类器类型:支持向量机或贝叶斯分类
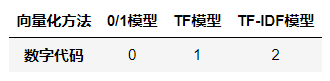
- self.vector_type = vector_type #文本向量化模型:0\1模型,TF模型,
- TF-IDF模型
-
- def fit(self, train_x, train_y, max_df):
- list_text = list(train_x)
-
- #向量化方法:0 - 0/1,1 - TF,2 - TF-IDF
- if self.vector_type == 0:
- self.vectorizer = CountVectorizer(max_df, stop_words = stopwords,
- ngram_range=(1, 3)).fit(list_text)
- elif self.vector_type == 1:
- self.vectorizer = TfidfVectorizer(max_df, stop_words = stopwords,
- ngram_range=(1, 3), use_idf=False).fit(list_text)
- else:
- self.vectorizer = TfidfVectorizer(max_df, stop_words = stopwords,
- ngram_range=(1, 3)).fit(list_text)
-
- self.array_trainx = self.vectorizer.transform(list_text)
- self.array_trainy = train_y
-
- #分类模型选择:1 - SVC,2 - LinearSVC,3 - SGDClassifier,三种SVM模型
- if self.classifier_type == 1:
- self.model = SVC(kernel='linear', gamma=10 ** -5, C=1).fit
- (self.array_trainx, self.array_trainy)
- elif self.classifier_type == 2:
- self.model = LinearSVC().fit(self.array_trainx, self.array_trainy)
- else:
- self.model = SGDClassifier().fit(self.array_trainx, self.array_trainy)
-
- def predict_value(self, test_x):
- list_text = list(test_x)
- self.array_testx = self.vectorizer.transform(list_text)
- array_predict = self.model.predict(self.array_testx)
- return array_predict
-
- def predict_proba(self, test_x):
- list_text = list(test_x)
- self.array_testx = self.vectorizer.transform(list_text)
- array_score = self.model.predict_proba(self.array_testx)
- return array_score
- 使用
train_test_split()函数划分训练集和测试集。训练集:80%;测试集:20%。 - 建立
classifier_type和vector_type两个参数的取值列表,来表示选择的向量化方法以及分类模型 - 输出每种向量化方法和分类模型的组合所对应的分类评价结果,内容包括混淆矩阵以及含
Precision、Recall和F1-score三个指标的评分矩阵
实现代码如下所示:
- #划分训练集,测试集
- train_x, test_x, train_y, test_y = train_test_split(data_cutted['Comment'].ravel().
- astype('U'), data_cutted['Class'].ravel(),
- test_size=0.2, random_state=4)
-
- classifier_list = [1,2,3]
- vector_list = [0,1,2]
-
- for classifier_type in classifier_list:
- for vector_type in vector_list:
- commentCls = CommentClassifier(classifier_type, vector_type)
- #max_df 设置为0.98
- commentCls.fit(train_x, train_y, 0.98)
- if classifier_type == 0:
- value_result = commentCls.predict_value(test_x)
- proba_result = commentCls.predict_proba(test_x)
- print(classifier_type,vector_type)
- print('classification report')
- print(metrics.classification_report(test_y, value_result, labels=
- [-1, 0, 1]))
- print('confusion matrix')
- print(metrics.confusion_matrix(test_y, value_result, labels=
- [-1, 0, 1]))
- else:
- value_result = commentCls.predict_value(test_x)
- print(classifier_type,vector_type)
- print('classification report')
- print(metrics.classification_report(test_y, value_result, labels=
- [-1, 0, 1]))
- print('confusion matrix')
- print(metrics.confusion_matrix(test_y, value_result, labels=[-1, 0, 1]))
输出效果如下所示:
- 1 0
- classification report
- precision recall f1-score support
-
- -1 0.68 0.62 0.65 519
- 0 0.55 0.49 0.52 485
- 1 0.75 0.86 0.80 634
-
- avg / total 0.67 0.68 0.67 1638
-
- confusion matrix
- [[324 130 65]
- [131 236 118]
- [ 24 64 546]]
- 1 1
- classification report
- precision recall f1-score support
-
- -1 0.71 0.74 0.72 519
- 0 0.58 0.54 0.56 485
- 1 0.84 0.85 0.85 634
-
- avg / total 0.72 0.72 0.72 1638
-
- confusion matrix
- [[385 109 25]
- [145 263 77]
- [ 15 80 539]]
- 1 2
- classification report
- precision recall f1-score support
-
- -1 0.70 0.74 0.72 519
- 0 0.58 0.52 0.55 485
- 1 0.84 0.86 0.85 634
-
- avg / total 0.72 0.72 0.72 1638
-
- confusion matrix
- [[386 106 27]
- [151 254 80]
- [ 14 76 544]]
- 2 0
- classification report
- precision recall f1-score support
-
- -1 0.70 0.62 0.66 519
- 0 0.56 0.51 0.54 485
- 1 0.76 0.88 0.82 634
-
- avg / total 0.68 0.69 0.68 1638
-
- confusion matrix
- [[320 135 64]
- [122 248 115]
- [ 16 57 561]]
- 2 1
- classification report
- precision recall f1-score support
-
- -1 0.69 0.73 0.71 519
- 0 0.61 0.48 0.54 485
- 1 0.81 0.91 0.86 634
-
- avg / total 0.71 0.73 0.72 1638
-
- confusion matrix
- [[377 108 34]
- [154 233 98]
- [ 12 44 578]]
- 2 2
- classification report
- precision recall f1-score support
-
- -1 0.70 0.74 0.72 519
- 0 0.61 0.50 0.55 485
- 1 0.83 0.91 0.87 634
-
- avg / total 0.72 0.73 0.73 1638
-
- confusion matrix
- [[383 108 28]
- [154 241 90]
- [ 13 43 578]]
- 3 0
- classification report
- precision recall f1-score support
-
- -1 0.69 0.69 0.69 519
- 0 0.58 0.47 0.52 485
- 1 0.79 0.90 0.84 634
-
- avg / total 0.70 0.71 0.70 1638
-
- confusion matrix
- [[359 118 42]
- [148 228 109]
- [ 14 47 573]]
- 3 1
- classification report
- precision recall f1-score support
-
- -1 0.70 0.74 0.72 519
- 0 0.60 0.49 0.54 485
- 1 0.81 0.88 0.84 634
-
- avg / total 0.71 0.72 0.71 1638
-
- confusion matrix
- [[386 96 37]
- [152 240 93]
- [ 13 66 555]]
- 3 2
- classification report
- precision recall f1-score support
-
- -1 0.65 0.75 0.69 519
- 0 0.63 0.49 0.55 485
- 1 0.83 0.86 0.85 634
-
- avg / total 0.71 0.72 0.71 1638
-
- confusion matrix
- [[389 98 32]
- [169 236 80]
- [ 45 41 548]]
从结果上来看,选择tfidf向量化方法,使用LinearSVC模型效果比较好,f1-socre为0.73
从混淆矩阵来看,我们会发现多数的错误分类都出现在中评和差评上。我们可以将原始数据集的中评删除。实现代码如下所示:
- data_bi = data_cutted[data_cutted['Class'] != 0]
- data_bi['Class'].value_counts()
效果如下所示:
- 1 3042
- -1 2658
- Name: Class, dtype: int64
再次运行分类模型,查看分类结果,如下所示:
- 1 0
- classification report
- precision recall f1-score support
-
- -1 0.90 0.79 0.84 537
- 1 0.83 0.92 0.87 603
-
- avg / total 0.86 0.86 0.86 1140
-
- confusion matrix
- [[425 112]
- [ 48 555]]
- 1 1
- classification report
- precision recall f1-score support
-
- -1 0.87 0.92 0.90 537
- 1 0.93 0.88 0.90 603
-
- avg / total 0.90 0.90 0.90 1140
-
- confusion matrix
- [[496 41]
- [ 71 532]]
- 1 2
- classification report
- precision recall f1-score support
-
- -1 0.88 0.93 0.90 537
- 1 0.93 0.88 0.91 603
-
- avg / total 0.90 0.90 0.90 1140
-
- confusion matrix
- [[497 40]
- [ 70 533]]
- 2 0
- classification report
- precision recall f1-score support
-
- -1 0.90 0.80 0.85 537
- 1 0.84 0.92 0.88 603
-
- avg / total 0.87 0.86 0.86 1140
-
- confusion matrix
- [[431 106]
- [ 48 555]]
- 2 1
- classification report
- precision recall f1-score support
-
- -1 0.92 0.91 0.91 537
- 1 0.92 0.93 0.92 603
-
- avg / total 0.92 0.92 0.92 1140
-
- confusion matrix
- [[486 51]
- [ 43 560]]
- 2 2
- classification report
- precision recall f1-score support
-
- -1 0.93 0.91 0.92 537
- 1 0.92 0.94 0.93 603
-
- avg / total 0.92 0.92 0.92 1140
-
- confusion matrix
- [[488 49]
- [ 39 564]]
- 3 0
- classification report
- precision recall f1-score support
-
- -1 0.92 0.82 0.87 537
- 1 0.86 0.94 0.90 603
-
- avg / total 0.89 0.88 0.88 1140
-
- confusion matrix
- [[443 94]
- [ 38 565]]
- 3 1
- classification report
- precision recall f1-score support
-
- -1 0.92 0.91 0.91 537
- 1 0.92 0.93 0.92 603
-
- avg / total 0.92 0.92 0.92 1140
-
- confusion matrix
- [[486 51]
- [ 41 562]]
- 3 2
- classification report
- precision recall f1-score support
-
- -1 0.88 0.93 0.90 537
- 1 0.93 0.89 0.91 603
-
- avg / total 0.91 0.91 0.91 1140
-
- confusion matrix
- [[497 40]
- [ 67 536]]
删除差评之后,不同组合的分类模型效果均有显著提升。这也说明,分类模型能够有效地将好评区分出来。
数据集中存在标注不准确的问题,主要集中在中评。由于人在评论时,除非有问题否则一般都会打好评,如果打了中评说明对产品有不满意之处,在情感的表达上就会趋向于负向情感,同时评论具有很大主观性,很多中评会将其归为差评,但数据集中却认为是中评。因此,将一条评论分类为好评、中评、差评是不够客观,中评与差评之间的边界很模糊,因此识别率很难提高。
5、基于word2vec中doc2vec的无监督分类模型
开源文本向量化工具word2vec,可以为文本数据寻求更加深层次的特征表示。词语之间可以进行运算:
w2v(woman)-w2v(man)+w2v(king)=w2v(queen)
基于word2vec的doc2vec,将每个文档表示为一个向量,并且通过余弦距离可以计算两个文档的相似程度,那么就可以计算一句话和一句极好的好评的距离,以及一句话到极差的差评的距离。
在本案例的数据集中:
- 好评:快 就是 手感 满意 也好 喜欢 也 流畅 很 服务态度 实用 超快 挺快 用着 速度 礼品 也不错 非常好 挺好 感觉 才来 还行 好看 也快 不错的 送了 非常不错 超级 赞 好多东西 很实用 各方面 挺好的 很多 漂亮 配件 还不错 也多 特意 慢 满分 好用 非常漂亮......
- 差评:不多说 上当 差差 刚用 服务差 一点也不 不要 简直 还是去 实体店 大家 保证 不肯 生气 开发票 磨损 后悔 印记 网 什么破 烂烂 左边 失效 太 骗 掉价 走下坡路 不说了 彻底 三星手机 自营 几次 真心 别的 看完 简单说 机会 这是 生气了 触动 缝隙 冲动了 失望......
我们使用第三方库gensim来实现doc2vec模型。
实现代码如下所示:
- import pandas as pd
- from gensim.models import Doc2Vec
- from gensim.models.doc2vec import TaggedDocument
- import logging
-
- logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',
- level=logging.INFO)
-
- train_x = data_bi['Comment'].ravel()
- train_y = data_bi['Class'].ravel()
-
- #为train_x列贴上标签"TRAIN"
- def labelizeReviews(reviews, label_type):
- labelized = []
- for i, v in enumerate(reviews):
- label = '%s_%s' % (label_type, i)
- labelized.append(TaggedDocument(v.split(" "), [label]))
- return labelized
-
-
- train_x = labelizeReviews(train_x, "TRAIN")
-
- #建立Doc2Vec模型model
- size = 300
- all_data = []
- all_data.extend(train_x)
-
- model = Doc2Vec(min_count=1, window=8, size=size, sample=1e-4, negative=5,
- hs=0, iter=5, workers=8)
- model.build_vocab(all_data)
-
- # 设置迭代次数10
- for epoch in range(10):
- model.train(train_x)
-
- #建立空列表pos和neg以对相似度计算结果进行存储,计算每个评论和极好评论之间的余弦距离,
- 并存在pos列表中
- #计算每个评论和极差评论之间的余弦距离,并存在neg列表中
- pos = []
- neg = []
-
- for i in range(0,len(train_x)):
- pos.append(model.docvecs.similarity("TRAIN_0","TRAIN_{}".format(i)))
- neg.append(model.docvecs.similarity("TRAIN_1","TRAIN_{}".format(i)))
-
- #将pos列表和neg列表更新到原始数据文件中,分别表示为字段PosSim和字段NegSim
- data_bi[u'PosSim'] = pos
- data_bi[u'NegSim'] = neg
模型训练过程如下所示:
- 2017-05-27 14:30:28,393 : INFO : collecting all words and their counts
- 2017-05-27 14:30:28,394 : INFO : PROGRESS: at example #0, processed 0 words (0/s),
- 0 word types, 0 tags
- 2017-05-27 14:30:28,593 : INFO : collected 10545 word types and 5700 unique tags
- from a corpus of 5700 examples and 482148 words
- 2017-05-27 14:30:28,595 : INFO : Loading a fresh vocabulary
- 2017-05-27 14:30:28,649 : INFO : min_count=1 retains 10545 unique words
- (100% of original 10545, drops 0)
- 2017-05-27 14:30:28,650 : INFO : min_count=1 leaves 482148 word corpus
- (100% of original 482148, drops 0)
- 2017-05-27 14:30:28,705 : INFO : deleting the raw counts dictionary of 10545 items
- 2017-05-27 14:30:28,706 : INFO : sample=0.0001 downsamples 217 most-common words
- 2017-05-27 14:30:28,707 : INFO : downsampling leaves estimated 108356 word corpus
- (22.5% of prior 482148)
- 2017-05-27 14:30:28,709 : INFO : estimated required memory for 10545 words and
- 300 dimensions: 38560500 bytes
- 2017-05-27 14:30:28,784 : INFO : resetting layer weights
- 2017-05-27 14:30:29,120 : INFO : training model with 8 workers on 10545 vocabulary
- and 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:29,121 : INFO : expecting 5700 sentences, matching count from
- corpus used for vocabulary survey
- 2017-05-27 14:30:30,176 : INFO : PROGRESS: at 10.24% examples, 72316 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:31,211 : INFO : PROGRESS: at 29.96% examples, 91057 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:32,218 : INFO : PROGRESS: at 66.30% examples, 126742 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:33,231 : INFO : PROGRESS: at 86.00% examples, 122698 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:33,571 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:33,573 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:33,605 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:33,647 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:33,678 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:33,696 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:33,711 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:33,722 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:33,724 : INFO : training on 2410740 raw words (570332 effective words)
- took 4.6s, 124032 effective words/s
- 2017-05-27 14:30:33,727 : INFO : training model with 8 workers on 10545 vocabulary and
- 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:33,731 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:34,753 : INFO : PROGRESS: at 36.38% examples, 212225 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:35,762 : INFO : PROGRESS: at 75.24% examples, 216859 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:36,243 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:36,244 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:36,264 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:36,306 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:36,311 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:36,320 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:36,330 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:36,336 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:36,338 : INFO : training on 2410740 raw words (570008 effective words)
- took 2.6s, 219523 effective words/s
- 2017-05-27 14:30:36,339 : INFO : training model with 8 workers on 10545 vocabulary
- and 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:36,341 : INFO : expecting 5700 sentences, matching count from
- corpus used for vocabulary survey
- 2017-05-27 14:30:37,353 : INFO : PROGRESS: at 28.23% examples, 177496 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:38,372 : INFO : PROGRESS: at 66.30% examples, 193880 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:39,061 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:39,062 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:39,074 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:39,115 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:39,122 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:39,132 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:39,147 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:39,154 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:39,155 : INFO : training on 2410740 raw words (570746 effective words)
- took 2.8s, 203312 effective words/s
- 2017-05-27 14:30:39,158 : INFO : training model with 8 workers on 10545 vocabulary
- and 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:39,159 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:40,168 : INFO : PROGRESS: at 37.74% examples, 222816 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:41,177 : INFO : PROGRESS: at 77.55% examples, 223202 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:41,605 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:41,610 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:41,614 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:41,645 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:41,670 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:41,674 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:41,682 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:41,690 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:41,692 : INFO : training on 2410740 raw words (569889 effective words)
- took 2.5s, 225457 effective words/s
- 2017-05-27 14:30:41,694 : INFO : training model with 8 workers on 10545 vocabulary
- and 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:41,696 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:42,712 : INFO : PROGRESS: at 29.16% examples, 183182 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:43,754 : INFO : PROGRESS: at 69.96% examples, 203560 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:44,804 : INFO : PROGRESS: at 91.97% examples, 173787 words/s,
- in_qsize 14, out_qsize 0
- 2017-05-27 14:30:44,973 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:44,989 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:45,028 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:45,061 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:45,097 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:45,101 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:45,121 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:45,125 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:45,128 : INFO : training on 2410740 raw words (569903 effective words)
- took 3.4s, 166370 effective words/s
- 2017-05-27 14:30:45,131 : INFO : training model with 8 workers on 10545 vocabulary and
- 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:45,132 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:46,152 : INFO : PROGRESS: at 11.26% examples, 79348 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:47,153 : INFO : PROGRESS: at 27.52% examples, 85992 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:48,166 : INFO : PROGRESS: at 66.47% examples, 130273 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:49,061 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:49,076 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:49,088 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:49,123 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:49,144 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:49,147 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:49,152 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:49,159 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:49,160 : INFO : training on 2410740 raw words (570333 effective words)
- took 4.0s, 141860 effective words/s
- 2017-05-27 14:30:49,161 : INFO : training model with 8 workers on 10545 vocabulary and
- 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:49,163 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:50,185 : INFO : PROGRESS: at 31.78% examples, 193530 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:51,244 : INFO : PROGRESS: at 48.51% examples, 141817 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:52,278 : INFO : PROGRESS: at 69.96% examples, 134399 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:30:52,918 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:52,936 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:52,945 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:52,976 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:52,979 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:52,984 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:52,995 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:52,998 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:52,999 : INFO : training on 2410740 raw words (570031 effective words)
- took 3.8s, 148864 effective words/s
- 2017-05-27 14:30:53,000 : INFO : training model with 8 workers on 10545 vocabulary
- and 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:53,002 : INFO : expecting 5700 sentences, matching count from
- corpus used for vocabulary survey
- 2017-05-27 14:30:54,024 : INFO : PROGRESS: at 34.48% examples, 202424 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:55,035 : INFO : PROGRESS: at 68.58% examples, 201499 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:56,010 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:56,017 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:56,048 : INFO : PROGRESS: at 96.89% examples, 183861 words/s,
- in_qsize 5, out_qsize 1
- 2017-05-27 14:30:56,049 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:56,071 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:56,084 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:56,099 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:56,101 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:56,104 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:56,104 : INFO : training on 2410740 raw words (570328 effective words)
- took 3.1s, 184129 effective words/s
- 2017-05-27 14:30:56,105 : INFO : training model with 8 workers on 10545 vocabulary and
- 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:56,107 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:57,134 : INFO : PROGRESS: at 33.13% examples, 197730 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:58,140 : INFO : PROGRESS: at 69.96% examples, 206423 words/s,
- in_qsize 15, out_qsize 0
- 2017-05-27 14:30:58,876 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:30:58,883 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:30:58,889 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:30:58,937 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:30:58,949 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:30:58,953 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:30:58,960 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:30:58,967 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:30:58,968 : INFO : training on 2410740 raw words (570312 effective words)
- took 2.9s, 199922 effective words/s
- 2017-05-27 14:30:58,969 : INFO : training model with 8 workers on 10545 vocabulary and
- 300 features, using sg=0 hs=0 sample=0.0001 negative=5 window=8
- 2017-05-27 14:30:58,970 : INFO : expecting 5700 sentences, matching count from corpus
- used for vocabulary survey
- 2017-05-27 14:30:59,991 : INFO : PROGRESS: at 32.86% examples, 198045 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:31:00,993 : INFO : PROGRESS: at 68.23% examples, 201443 words/s,
- in_qsize 16, out_qsize 0
- 2017-05-27 14:31:01,881 : INFO : worker thread finished; awaiting finish of 7
- more threads
- 2017-05-27 14:31:01,888 : INFO : worker thread finished; awaiting finish of 6
- more threads
- 2017-05-27 14:31:01,907 : INFO : worker thread finished; awaiting finish of 5
- more threads
- 2017-05-27 14:31:01,922 : INFO : worker thread finished; awaiting finish of 4
- more threads
- 2017-05-27 14:31:01,941 : INFO : worker thread finished; awaiting finish of 3
- more threads
- 2017-05-27 14:31:01,948 : INFO : worker thread finished; awaiting finish of 2
- more threads
- 2017-05-27 14:31:01,955 : INFO : worker thread finished; awaiting finish of 1
- more threads
- 2017-05-27 14:31:01,961 : INFO : worker thread finished; awaiting finish of 0
- more threads
- 2017-05-27 14:31:01,962 : INFO : training on 2410740 raw words (570826 effective words)
- took 3.0s, 191072 effective words/s
最后可视化评论分类效果,实现代码如下所示:
- from matplotlib import pyplot as plt
-
- label= data_bi['Class'].ravel()
- values = data_bi[['PosSim' , 'NegSim']].values
-
- plt.scatter(values[:,0], values[:,1], c=label, alpha=0.4)
- plt.show()
效果如下所示:
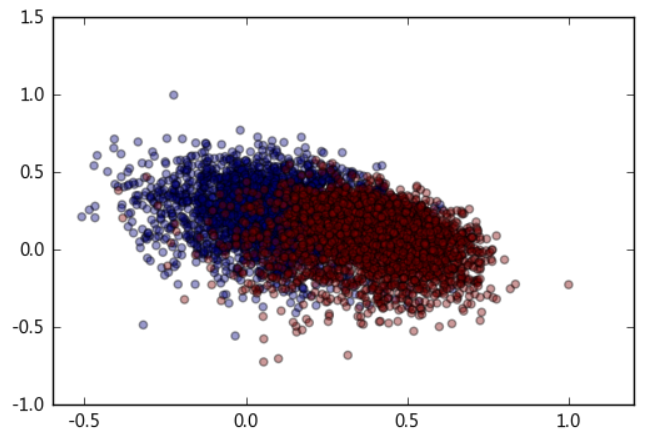
从上图中可以看到,好评与差评基本上可以通过一条直线区分开(蓝色为差评,红色为好评)
该方法与传统思路完全不同,没有使用词频率,情感词等特征,其优点有:
- 将数据集映射到了极低维度的空间,只有二维
- 一种无监督的学习方法,不需要对原始训练数据进行标注
- 具有普适性,在其他领域也可以用这种方法,只需要先找出该领域极其正和极其负的方法,将其与所有待识别的数据通过doc2vec转化为向量计算距离即可
关注公众号,发送关键字:Java车牌识别,获取项目源码。
 分类导航
分类导航