

 个人中心
个人中心 退出
退出




十种方法实现图像数据集降维
目录
3.7.2、modified LLE
3.7.3、hessian LLE
3.7.4、LTSA
降维是通过单幅图像数据的高维化,对单幅图像转化为高维空间中的数据集合进行的一种操作。机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。
本项目将依托于MNIST数据集,手把手实现图像数据集降维。
MNIST数据集来自美国国家标准与技术研究所,是入门级的计算机视觉数据集。它是由6万张训练图片和1万张测试图片构成的,这些图片是手写的从0到9的数字,50%采集美国中学生,50%来自人口普查局(the Census Bureau)的工作人员。这些数字图片进行过预处理和格式化,均为黑白色构成,做了大小调整(28×28像素)并居中处理。MNIST数据集效果如下图所示:

1、获取数据集
在本案例中,选择直接从sklearn.datasets模块中通过load_digits导入手写数字图片数据集,该数据集是UCI datasets的Optical Recognition of Handwritten Digits Data Set中的测试集,并且只是MNIST的很小的子集,一共有1797张分辨率为8××8的手写数字图片。同时,该图片有从0到9共十类数字。
先导入load_digits模块及本案例所需的相关的包,实现代码如下所示:
- from time import time # 用于计算运行时间
- import matplotlib.pyplot as plt
- import numpy as np
- from matplotlib import offsetbox # 定义图形box的格式
- from sklearn import (manifold, datasets, decomposition, ensemble,
- discriminant_analysis, random_projection)
load_digits中有n_class参数,可以指定选择提取多少类的图片(从数字0开始),缺省值为10;还有一个return_X_y参数(sklearn 0.18版本的新参数),若该参数值为True,则返回图片数据data和标签target,默认为False。return_X_y为False的情况下,将会返回一个Bunch对象,该对象是一个类似字典的对象,其中包括了数据data、images和数据集的完整描述信息DESCR。
下面就这两种读取方式分别展示:
方法一:返回Bunch对象,实现代码如下所示:
- digits = datasets.load_digits(n_class=6)
- print(digits)
- # 获取bunch中的data,target
- print(digits.data)
- print(digits.target)
输出结果如下所示:
- [[ 0. 0. 5. ..., 0. 0. 0.]
- [ 0. 0. 0. ..., 10. 0. 0.]
- [ 0. 0. 0. ..., 16. 9. 0.]
- ...,
- [ 0. 0. 0. ..., 9. 0. 0.]
- [ 0. 0. 0. ..., 4. 0. 0.]
- [ 0. 0. 6. ..., 6. 0. 0.]]
- [0 1 2 ..., 4 4 0]
方法二:只返回data和target,实现代码如下所示:
- data = datasets.load_digits(n_class=6)
- print(data)
输出结果如下所示:
- {'images': array([[[ 0., 0., 5., ..., 1., 0., 0.],
- [ 0., 0., 13., ..., 15., 5., 0.],
- [ 0., 3., 15., ..., 11., 8., 0.],
- ...,
- [ 0., 4., 11., ..., 12., 7., 0.],
- [ 0., 2., 14., ..., 12., 0., 0.],
- [ 0., 0., 6., ..., 0., 0., 0.]],
-
- [[ 0., 0., 0., ..., 5., 0., 0.],
- [ 0., 0., 0., ..., 9., 0., 0.],
- [ 0., 0., 3., ..., 6., 0., 0.],
- ...,
- [ 0., 0., 1., ..., 6., 0., 0.],
- [ 0., 0., 1., ..., 6., 0., 0.],
- [ 0., 0., 0., ..., 10., 0., 0.]],
-
- [[ 0., 0., 0., ..., 12., 0., 0.],
- [ 0., 0., 3., ..., 14., 0., 0.],
- [ 0., 0., 8., ..., 16., 0., 0.],
- ...,
- [ 0., 9., 16., ..., 0., 0., 0.],
- [ 0., 3., 13., ..., 11., 5., 0.],
- [ 0., 0., 0., ..., 16., 9., 0.]],
-
- ...,
- [[ 0., 0., 0., ..., 6., 0., 0.],
- [ 0., 0., 0., ..., 2., 0., 0.],
- [ 0., 0., 8., ..., 1., 2., 0.],
- ...,
- [ 0., 12., 16., ..., 16., 1., 0.],
- [ 0., 1., 7., ..., 13., 0., 0.],
- [ 0., 0., 0., ..., 9., 0., 0.]],
-
- [[ 0., 0., 0., ..., 4., 0., 0.],
- [ 0., 0., 4., ..., 0., 0., 0.],
- [ 0., 0., 12., ..., 4., 3., 0.],
- ...,
- [ 0., 12., 16., ..., 13., 0., 0.],
- [ 0., 0., 4., ..., 8., 0., 0.],
- [ 0., 0., 0., ..., 4., 0., 0.]],
-
- [[ 0., 0., 6., ..., 11., 1., 0.],
- [ 0., 0., 16., ..., 16., 1., 0.],
- [ 0., 3., 16., ..., 13., 6., 0.],
- ...,
- [ 0., 5., 16., ..., 16., 5., 0.],
- [ 0., 1., 15., ..., 16., 1., 0.],
- [ 0., 0., 6., ..., 6., 0., 0.]]]), 'data': array([[ 0., 0., 5.,
- ..., 0., 0., 0.],
- [ 0., 0., 0., ..., 10., 0., 0.],
- [ 0., 0., 0., ..., 16., 9., 0.],
- ...,
- [ 0., 0., 0., ..., 9., 0., 0.],
- [ 0., 0., 0., ..., 4., 0., 0.],
- [ 0., 0., 6., ..., 6., 0., 0.]]), 'target_names': array
- ([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), 'DESCR': "Optical Recognition of Handwritten Digits
- Data Set\n===================================================\n\nNotes\n-----\nData
- Set Characteristics:\n :Number of Instances: 5620\n :Number of Attributes: 64\n
- :Attribute Information: 8x8 image of integer pixels in the range 0..16.\n :Missing
- Attribute Values: None\n :Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)\n :
- Date: July; 1998\n\nThis is a copy of the test set of the UCI ML hand-written digits
- datasets\nhttp://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+
- Digits\n\nThe data set contains images of hand-written digits: 10 classes where\neach
- class refers to a digit.\n\nPreprocessing programs made available by NIST were used to
- extract\nnormalized bitmaps of handwritten digits from a preprinted form. From a\ntota
- l of 43 people, 30 contributed to the training set and different 13\nto the test set.
- 32x32 bitmaps are divided into nonoverlapping blocks of\n4x4 and the number of on
- pixels are counted in each block. This generates\nan input matrix of 8x8 where each
- element is an integer in the range\n0..16. This reduces dimensionality and gives
- invariance to small\ndistortions.\n\nFor info on NIST preprocessing routines,
- see M. D. Garris, J. L. Blue, G.\nT. Candela, D. L. Dimmick, J. Geist, P. J.
- Grother, S. A. Janet, and C.\nL. Wilson, NIST Form-Based Handprint Recognition System,
- NISTIR 5469,\n1994.\n\nReferences\n----------\n - C. Kaynak (1995) Methods of
- Combining Multiple Classifiers and Their\n Applications to Handwritten Digit
- Recognition, MSc Thesis, Institute of\n Graduate Studies in Science and Engineering,
- Bogazici University.\n - E. Alpaydin, C. Kaynak (1998) Cascading Classifiers,
- Kybernetika.\n - Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.\n
- Linear dimensionalityreduction using relevance weighted LDA. School of\n
- Electrical and Electronic Engineering Nanyang Technological University.\n
- 2005.\n - Claudio Gentile. A New Approximate Maximal Margin Classification\n
- Algorithm. NIPS. 2000.\n", 'target': array([0, 1, 2, ..., 4, 4, 0])}
本案例只提取从数字0到数字5的图片进行降维,我们挑选图片数据集中的前六个照片进行展示,实现代码如下所示:
- # plt.gray()
- fig, axes = plt.subplots(nrows=1, ncols=6, figsize=(8, 8))
- for i,ax in zip(range(6),axes.flatten()):
- ax.imshow(digits.images[i], cmap=plt.cm.gray_r)
- plt.show()
效果如下所示:

为了能够方便的展示手写数字图片,使用返回Bunch对象的导入方式,实现代码如下所示:
- digits = datasets.load_digits(n_class=6)
- X = digits.data
- y = digits.target
- n_samples, n_features = X.shape
- n_neighbors = 30
2、数据集可视化
将数据集部分数据图片可视化显示,实现代码如下所示:
- n_img_per_row = 30 # 每行显示30个图片
-
- # 整个图形占 300*300,由于一张图片为8*8,所以每张图片周围包了一层白框,防止图片之间互相影响
- img = np.zeros((10 * n_img_per_row, 10 * n_img_per_row))
-
- for i in range(n_img_per_row):
- ix = 10 * i + 1
- for j in range(n_img_per_row):
- iy = 10 * j + 1
- img[ix:ix + 8, iy:iy + 8] = X[i * n_img_per_row + j].reshape((8, 8))
- plt.figure(figsize=(6,6))
- plt.imshow(img, cmap=plt.cm.binary)
- plt.xticks([])
- plt.yticks([])
- plt.title('A selection from the 64-dimensional digits dataset')
效果如下所示:

3、降维及可视化
图片数据是一种高维数据(从几十到上百万的维度),如果把每个图片看成是高维空间的点,要把这些点在高维空间展示出来是极其困难的,所以我们需要将这些数据进行降维,在二维或者三维空间中看出整个数据集的内嵌结构。
本案例要展示的降维方法及所在sklearn的模块如下表所示:
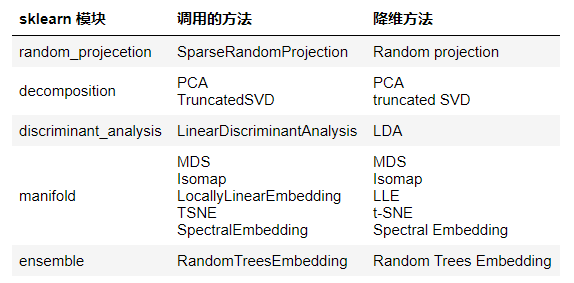
调用以上方法进行降维的流程都是类似的:
- 首先根据具体方法创建实例:
实例名 = sklearn模块.调用的方法(一些参数的设置) - 然后对数据进行转换:
转换后的数据变量名 = 实例名.fit_transform(X),在某些方法如LDA降维中还需要提供标签y - 最后将转换后的数据进行可视化:输入转换后的数据以及标题,画出二维空间的图。
为了绘图方便并统一画图的风格,首先定义plot_embedding函数用于画出低维嵌入的图形。
配色方案如下所示:
- 绿色 #5dbe80
- 蓝色 #2d9ed8
- 紫色 #a290c4
- 橙色 #efab40
- 红色 #eb4e4f
- 灰色 #929591
实现代码如下所示:
- # 首先定义函数画出二维空间中的样本点,输入参数:1.降维后的数据;2.图片标题
-
- def plot_embedding(X, title=None):
- x_min, x_max = np.min(X, 0), np.max(X, 0)
- X = (X - x_min) / (x_max - x_min) # 对每一个维度进行0-1归一化,注意此时X只有两个维度
-
- plt.figure(figsize= (6,6)) # 设置整个图形大小
- ax = plt.subplot(111)
- colors = ['#5dbe80','#2d9ed8','#a290c4','#efab40','#eb4e4f','#929591']
-
- # 画出样本点
- for i in range(X.shape[0]): # 每一行代表一个样本
- plt.text(X[i, 0], X[i, 1], str(digits.target[i]),
- #color=plt.cm.Set1(y[i] / 10.),
- color=colors[y[i]],
- fontdict={'weight': 'bold', 'size': 9}) # 在样本点所在位置画出样本点
- 的数字标签
-
- # 在样本点上画出缩略图,并保证缩略图够稀疏不至于相互覆盖
- # 只有matplotlib 1.0版本以上,offsetbox才有'AnnotationBbox',所以需要先判断是否有这个
- 功能
- if hasattr(offsetbox, 'AnnotationBbox'):
- shown_images = np.array([[1., 1.]]) # 假设最开始出现的缩略图在(1,1)位置上
- for i in range(digits.data.shape[0]):
- dist = np.sum((X[i] - shown_images) ** 2, 1) # 算出样本点与所有展示过的图片
- (shown_images)的距离
- if np.min(dist) < 4e-3: # 若最小的距离小于4e-3,即存在有两个样本点靠的很近的
- 情况,则通过continue跳过展示该数字图片缩略图
- continue
- shown_images = np.r_[shown_images, [X[i]]] # 展示缩略图的样本点通过纵向
- 拼接加入到shown_images矩阵中
-
- imagebox = offsetbox.AnnotationBbox(
- offsetbox.OffsetImage(digits.images[i], cmap=plt.cm.gray_r),
- X[i])
- ax.add_artist(imagebox)
-
- plt.xticks([]), plt.yticks([]) # 不显示横纵坐标刻度
- if title is not None:
- plt.title(title)
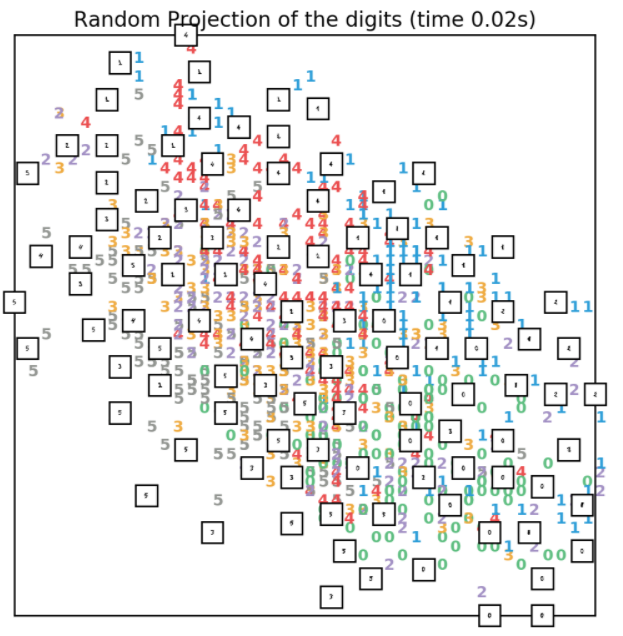
3.1、Random projection降维
Random projection(随机投影)是最简单的一种降维方法。这种方法只能在很小的程度上展示出整个数据的空间结构,会丢失大部分的结构信息,所以这种降维方法很少会用到,实现代码如下所示:
- t0 = time()
- rp = random_projection.SparseRandomProjection(n_components=2, random_state=66)
- X_projected = rp.fit_transform(X)
- plot_embedding(X_projected,
- "Random Projection of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
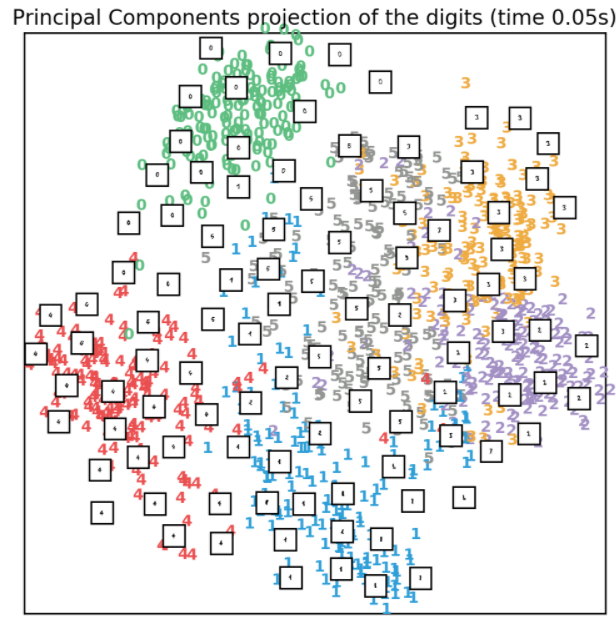
3.2、PCA降维
PCA降维是最常用的一种线性的无监督的降维方法。PCA降维实际是对协方差矩阵进行SVD分解来进行降维的线性降维方法,实现代码如下所示:
- t0 = time()
- pca = decomposition.PCA(n_components=2)
- X_pca = pca.fit_transform(X)
- plot_embedding(X_pca,
- "Principal Components projection of the digits (time %.2fs)" %
- (time() - t0))
- print pca.explained_variance_ratio_ # 每一个成分对原数据的方差解释了百分之多少
效果如下所示:
3.3、truncated SVD降维
truncated SVD方法即利用截断SVD分解方法对数据进行线性降维。与PCA不同,该方法在进行SVD分解之前不会对数据进行中心化,这意味着该方法可以有效地处理稀疏矩阵如scipy.sparse定义的稀疏矩阵,而PCA方法不支持scipy.sparse稀疏矩阵的输入。在文本分析领域,该方法可以对稀疏的词频/tf-idf矩阵进行SVD分解,即LSA(隐语义分析),实现代码如下所示:
- t0 = time()
- svd = decomposition.TruncatedSVD(n_components=2)
- X_svd = svd.fit_transform(X)
- plot_embedding(X_svd,
- "Principal Components projection of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:

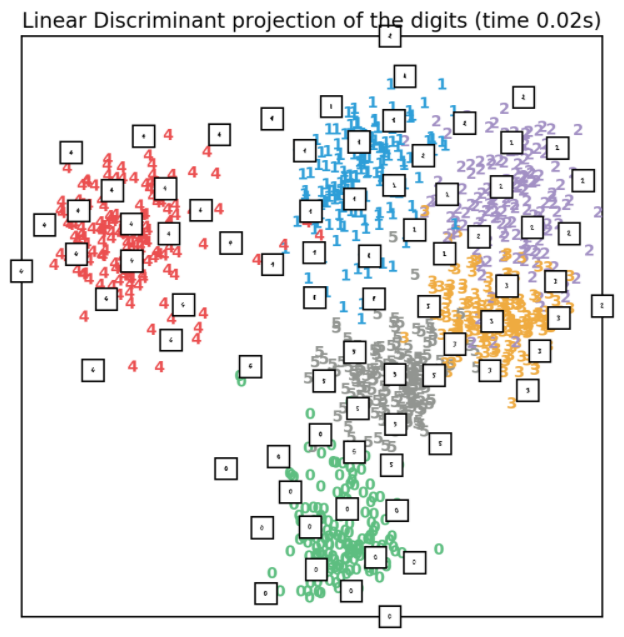
3.4、LDA降维
LDA降维方法利用了原始数据的标签信息,所以在降维之后,低维空间的相同类的样本点聚在一起,不同类的点分隔比较开,实现代码如下所示:
- X2 = X.copy()
- X2.flat[::X.shape[1] + 1] += 0.01 # 使得X可逆
- t0 = time()
- lda = discriminant_analysis.LinearDiscriminantAnalysis(n_components=2)
- X_lda = lda.fit_transform(X2, y)
- plot_embedding(X_lda,
- "Linear Discriminant projection of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
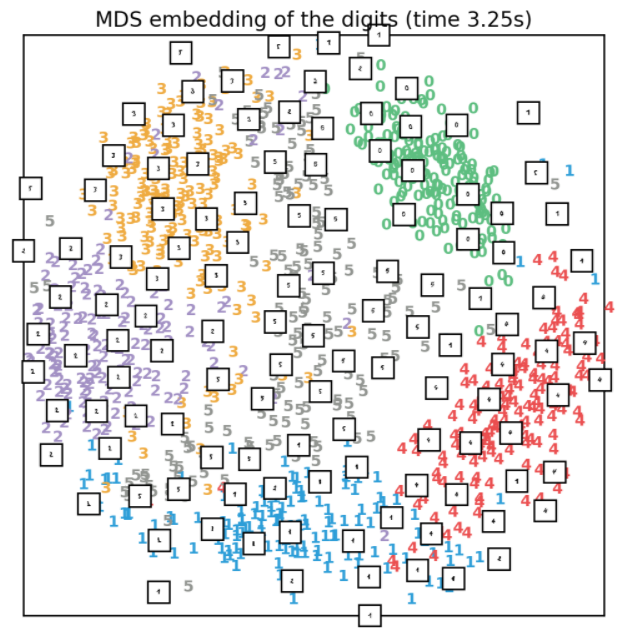
3.5、MDS降维
如果样本点之间本身存在距离上的某种类似城市之间地理位置的关系,那么可以使用MDS降维在低维空间保持这种距离关系,实现代码如下所示:
- clf = manifold.MDS(n_components=2, n_init=1, max_iter=100)
- t0 = time()
- X_mds = clf.fit_transform(X)
- plot_embedding(X_mds,
- "MDS embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
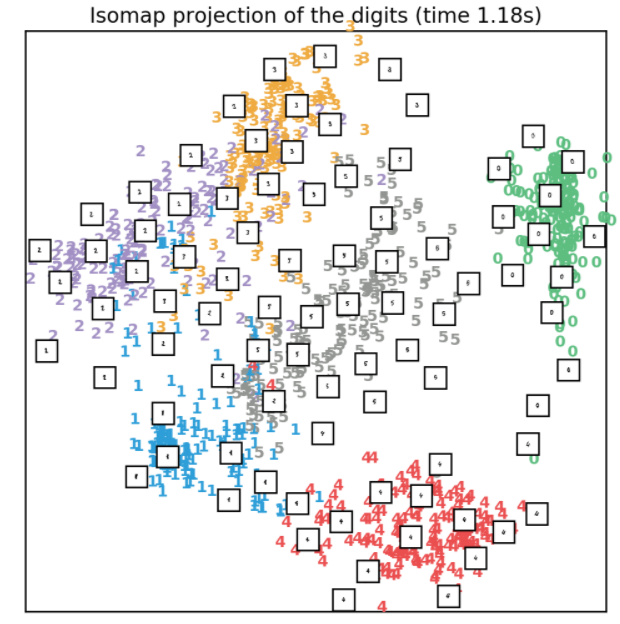
3.6、Isomap降维
Isomap是流形学习方法的一种,是等度量映射(Isometric mapping)的简写。该方法可以看做是MDS方法的延伸。不同于MDS的是,该方法在降维前后保持的是所有数据点之间的测地距离(geodesic distances)的关系。
Isomap需要指定领域的最近邻点的个数,我们在提取图片数据时就已经指定为30了。由于需要计算样本点的测地距离,该方法在时间消耗上比较大,实现代码如下所示:
- t0 = time()
- iso = manifold.Isomap(n_neighbors, n_components=2)
- X_iso = iso.fit_transform(X)
- plot_embedding(X_iso,
- "Isomap projection of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
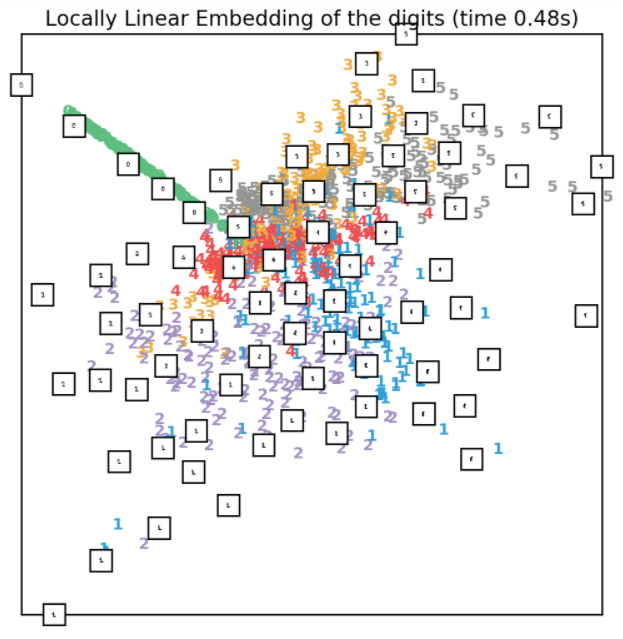
3.7、LLE降维
LLE降维同样需要指定领域样本点个数n_neighbors,LLE降维保持了邻域内的样本点之间的距离关系,它可以理解为一系列的局域PCA操作,但是它在全局上很好的保持了数据的非结构信息。LLE降维主要包括四种方法standard,modified,hessian和ltsa,下面进行一一展示,并且输出它们的重构误差(从低维空间的数据重构原始空间的数据时的误差)。
3.7.1、standard LLE
standard LLE降维实现代码如下所示:
- clf = manifold.LocallyLinearEmbedding(n_neighbors, n_components=2, method='standard')
- t0 = time()
- X_lle = clf.fit_transform(X)
- plot_embedding(X_lle,
- "Locally Linear Embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下图所示:
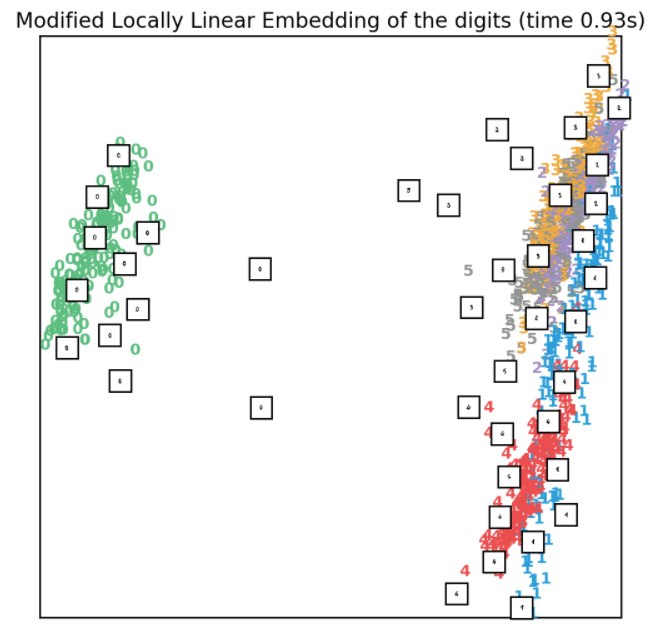
3.7.2、modified LLE
standard LLE存在正则化的问题:当n_neighbors大于输入数据的维度时,局部邻域矩阵将出现rank-deficient(秩亏)的问题。为了解决这个问题,在standard LLE基础上引入了一个正则化参数𝑟r。通过设置参数methond='modified',可以实现modified LLE降维,实现代码如下所示:
- clf = manifold.LocallyLinearEmbedding(n_neighbors, n_components=2, method='modified')
- t0 = time()
- X_mlle = clf.fit_transform(X)
- plot_embedding(X_mlle,
- "Modified Locally Linear Embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
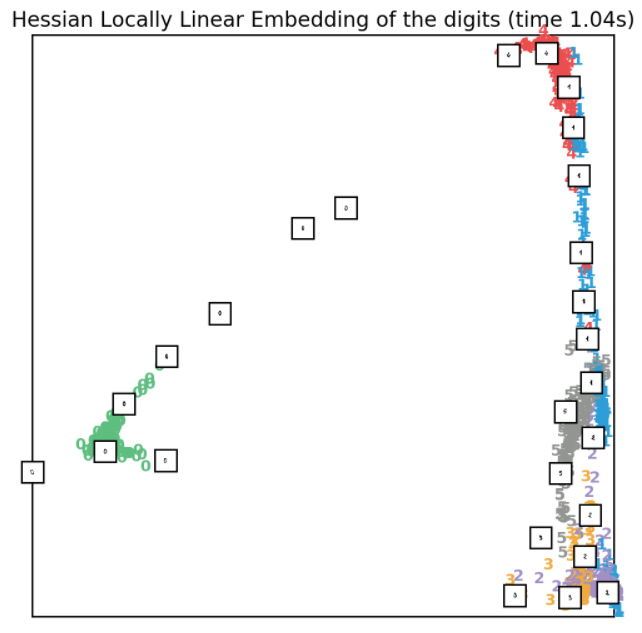
3.7.3、hessian LLE
hessian LLE,也叫Hessian Eigenmapping,是另外一种解决LLE正则化问题的方法。该方法使用的前提是满足n_neighbors > n_components * (n_components + 3) / 2,实现代码如下所示:
- clf = manifold.LocallyLinearEmbedding(n_neighbors, n_components=2, method='hessian')
- t0 = time()
- X_hlle = clf.fit_transform(X)
- plot_embedding(X_hlle,
- "Hessian Locally Linear Embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
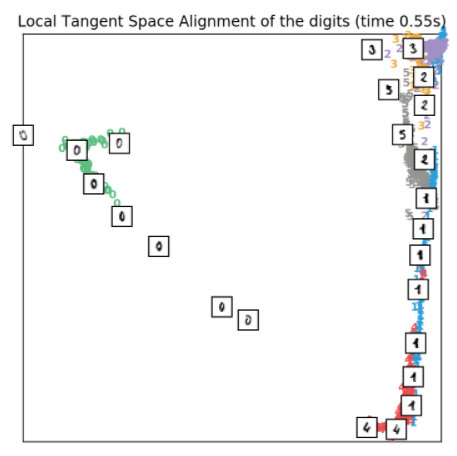
3.7.4、LTSA
LTSA(Local tangent space alignment)方法实际上并不是LLE的变体,只是由于它与LLE算法相似所以被分在了LocallyLinearEmbedding中。与LLE降维前后保持邻近点之间的距离关系不同,LTSA通过将数据放在tangent空间以刻画邻域内样本点之间的地理性质,实现代码如下所示:
- clf = manifold.LocallyLinearEmbedding(n_neighbors, n_components=2, method='ltsa')
- t0 = time()
- X_ltsa = clf.fit_transform(X)
- plot_embedding(X_ltsa,
- "Local Tangent Space Alignment of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
3.8、t-SNE降维
本示例使用PCA生成的嵌入来初始化t-SNE,而不是t-SNE的默认设置(即init='pca')。 它确保嵌入的全局稳定性,即嵌入不依赖于随机初始化。
t-SNE方法对于数据的局部结构信息很敏感,而且有许多的优点:
- 揭示了属于不同的流形或者簇中的样本
- 减少了样本聚集在
当然,它也有许多缺点:
- 计算代价高,在百万级别的图片数据上需要花费好几小时,而对于同样的任务,PCA只需要花费几分钟或者几秒;
- 该算法具有随机性,不同的随机种子会产生不同的降维结果。当然通过选择不同的随机种子,选取重构误差最小的那个随机种子作为最终的执行降维的参数是可行的;
- 全局结构保持较差,不过这个问题可以通过使用PCA初始样本点来缓解(
init='pca')。
实现代码如下所示:
- tsne = manifold.TSNE(n_components=2, init='pca', random_state=10) # 生成tsne实例
- t0 = time() # 执行降维之前的时刻
- X_tsne = tsne.fit_transform(X) # 降维得到二维空间中的数据
- plot_embedding(X_tsne, "t-SNE embedding of the digits (time %.2fs)" % (time() - t0))
- # 画出降维后的嵌入图形
- plt.show()
效果如下所示:

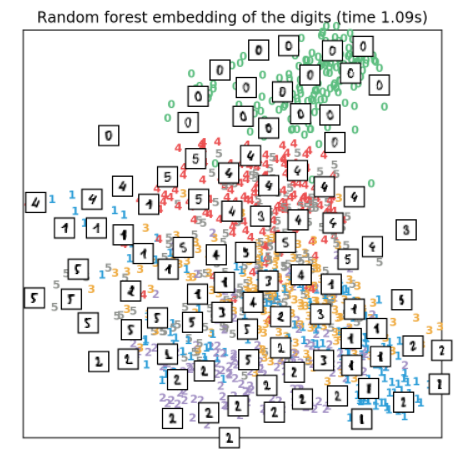
3.9、RandomTrees降维
来自sklearn.ensemble模块的RandomTreesEmbedding在技术层面看并不是一种多维嵌入方法,但是它学习了一种数据的高维表示可以用于数据降维方法中。可以先使用RandomTreesEmbedding对数据进行高维表示,然后再使用PCA或者truncated SVD进行降维,实现代码如下所示:
- hasher = ensemble.RandomTreesEmbedding(n_estimators=200, random_state=0, max_depth=5)
- t0 = time()
- X_transformed = hasher.fit_transform(X)
- pca = decomposition.TruncatedSVD(n_components=2)
- X_reduced = pca.fit_transform(X_transformed)
- plot_embedding(X_reduced,
- "Random forest embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
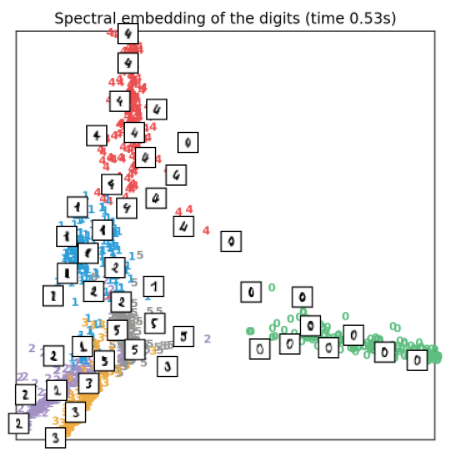
3.10、Spectral embedding降维
Spectral embedding,也叫Laplacian Eigenmaps(拉普拉斯特征映射)。它利用拉普拉斯图的谱分解找到数据在低维空间中的表示,实现代码如下所示:
- embedder = manifold.SpectralEmbedding(n_components=2, random_state=0,
- eigen_solver="arpack")
- t0 = time()
- X_se = embedder.fit_transform(X)
- plot_embedding(X_se,
- "Spectral embedding of the digits (time %.2fs)" %
- (time() - t0))
效果如下所示:
4、总结
本案例使用多种降维方法对手写数字图片数据进行降维及可视化展示,包括PCA、LDA和基于流形学习的降维方法等。
线性降维方法包括PCA、LDA时间消耗较少,但是这种线性降维方法会丢失高维空间中的非线性结构信息。相比较而言,非线性降维方法(这里没有提到KPCA和KLDA,有兴趣的可以试一试这两类非线性降维方法)中的流形学习方法可以很好的保留高维空间中的非线性结构信息。虽然典型的流形学习是非监督的方法,但是也存在一些有监督方法的变体。
在进行数据降维时,我们一定要弄清楚我们降维的目的,是为了进行特征提取,使得之后的模型解释性更强或效果提升,还是仅仅为了可视化高维数据。在降维的方法的选择上,我们也要尽量平衡时间成本和降维效果。
另外,在降维时需要注意以下几点:
- 降维之前,所有特征的尺度是一致的;
- 重构误差可以用于寻找最优的输出维度𝑑d(此时降维不只是为了可视化),随着维度𝑑d的增加,重构误差将会减小,直到达到实现设定的阈值;
- 噪音点可能会导致流形出现“短路”,即原本在流形之中很容易分开的两部分被噪音点作为一个“桥梁”连接在了一起;
- 某种类型的输入数据可能导致权重矩阵是奇异的,比如在数据集有超过两个样本点是相同的,或者样本点被分在了不相交的组内。在这种情况下,特征值分解的实现
solver='arpack'将找不到零空间。解决此问题的最简单的办法是使用solver='dense'实现特征值分解,虽然dense可能会比较慢,但是它可以用在奇异矩阵上。除此之外,我们也可以通过理解出现奇异的原因来思考解决的办法:如果是由于不相交集合导致,则可以尝试n_neighbors增大;如果是由于数据集中存在相同的样本点,那么可以尝试去掉这些重复的样本点,只保留其中一个。
关注公众号,发送关键字:Java车牌识别,获取项目源码。
 分类导航
分类导航