

 个人中心
个人中心 退出
退出




hadoop基本文件配置:
马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
马克-to-win @ 马克java社区:hadoop配置文件位于:/etc/hadoop下(etc即:“etcetera”(附加物))
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
注意:以上说的就是缺省的文件系统是端口是9000,协议是hdfs,所以在浏览器中是看不到效果的。而后面配置eclipse
的hdfsLocation 时,端口也是9000(必须一致)。虽然浏览器看不到,但是程序和eclipse当中可以看到hdfsLocation,即根目录下的东西。所以可以说:这里的值指的是默认的HDFS路径。浏览器中可以用http://localhost:50070 来观看。(当然根据我们所讲的namenode和datanode的知识,可知道一个hdfs的文件可能拆成很多block,分布在集群的不同机器上)当start-dfs时,会读这里的信息。如果不启动start-dfs,eclipse中读hdfsLocation时,是读不出东西的。原因:hdfs服务器在start-dfs时听9000端口。eclipse必须配成9000,才能要向hdfs服务器要数据,展示根目录下的东西。
hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Users/dell/Downloads/hadoop-2.7.4/hadoop-2.7.4/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> <value>file:/Users/dell/Downloads/hadoop-2.7.4/hadoop-2.7.4/data/dfs/datanode</value>
</property>
</configuration>
备注:第二次在d盘做时,用的是如下的配置(注意要先创建相应的空文件夹data/namenode等):
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop-2.7.4/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop-2.7.4/data/datanode</value>
</property>
</configuration>
注意:以上对namenode和datanode两个属性必须得设置,否则的话,后面的start-dfs启动不了。当然eclipse里的hdfsLocation也不能正常使用。
注意:马克-to-win @ 马克java社区:防盗版实名手机尾号:73203。一个HDFS集群包含一个NameNode和若干的DataNode(start-dfs命令就启动了NameNode和DataNode), NameNode是管理者,主要负责管理hdfs文件系统,具体包括namespace命名空间管理(即目录结构)和block管理。DataNode主 要用来存储数据文件,因为文件可能巨大无比(大数据),HDFS将一个文件分割成一个个的block,这些block可能存储在一个DataNode上或 者多个DataNode上。DataNode负责实际的底层的文件的读写。举个例子:如果客户端client程序发起了读hdfs上的某个文件的指令, NameNode首先将找到这个文件对应的block,然后NameNode告知client,这些block数据在哪些DataNode上,之后, client将直接和DataNode交互。
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
注意:以上的配置文件,只用在集群模式下。在local的模式下,当以jar包运行,比如:hadoop jar WordCount.jar /README.txt /output4时,必须配置为空。即:<configuration></configuration>,因为空的,缺省的模式就是local模式。而在local的模式下,如果配成yarn,不能成功执行。在local的模式下,当在eclipse里面运行时,那里的 MapReduce Master要配置成local就能运行,和这里的配置文件配不配成yarn无关。
6)格式化系统文件:
hadoop/bin下执行: hdfs namenode -format
如不报错的话,会在namenode文件里自动生成一个current文件夹,则格式化成功。
7)启动hadoop
到hadoop/sbin下执行: start-dfs
这样会出现两个窗口,一个是namenode,一个是datanode.
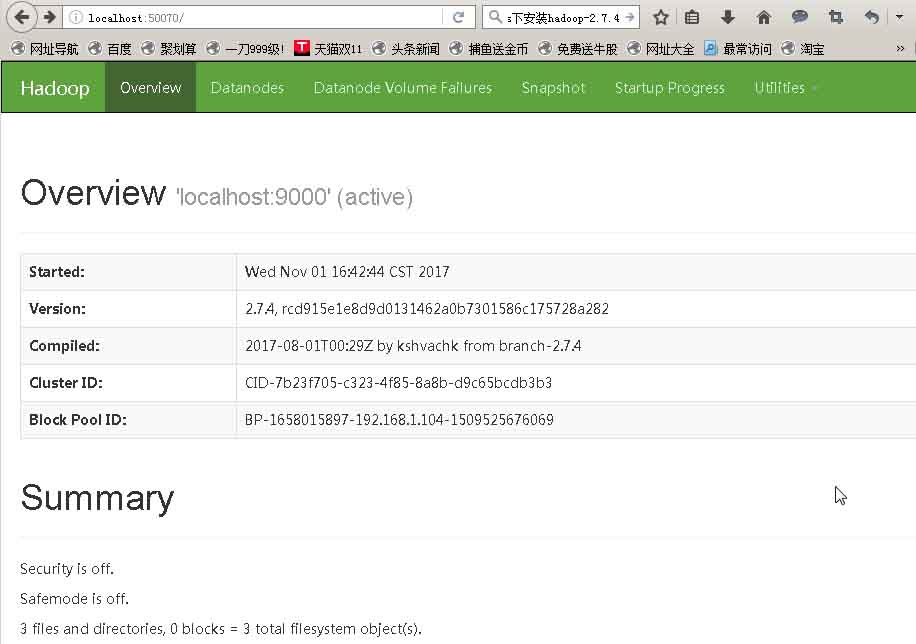
测试:http://localhost:50070
 分类导航
分类导航