

 个人中心
个人中心 退出
退出




MapReduce的shuffle过程详解
马克-to-win @ 马克java社区:思路的精髓:想象一下,你把前面那个文件的三行字儿,分别发给你三个同学,但他们都不知道别人手上的字是什么,他们只能搞清自己手上的字,每个出现多少次?最后你必须得把他们三个人手中的结果统一在一起,结果才会正确,最聪明的办法就是排序和融合,比如hello,在第一个人手里出现两次,第二个人手里出现一次,三个人最后开个会, 一统一信息(对于mapreduce来讲就是一个partition数据集中到一个文件中 ),信息就透明了。对于咱们例子当中,hello,出现了四次。但现在想成这三个人是哑巴,而不是聋子, 可执行命令,但自己不能发命令,这是和机器最贴切的比喻。 机器不能像人一样沟通, 但用排序和融合这样的指令,就逼着结果就出来了。 只有通过排序和融合,才能知道这件事。马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思。当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个map节点,而不是就来自于一号map节点。所以说它们的数据会混合,路线会交叉, 3叉3。想象一下,像不像洗牌? 马克-to-win @ 马克java社区:shuffle在MapReduce中是指map输出后到reduce接收前,按下面的官方shuffle图:具体可以分为map端和reduce端两个部分。在最开始,假设我们就提交一个大文件,MapReduce会对要处理的大文件数据进行分片(split)操作放到多台机器的集群里,(想象一个搬走大山的大活给一个师的人马,是不是要把人,部署一圈,展开,一人干一块儿,一个成语叫蚂蚁搬家,精髓在于拆。现在是一样的道理。现在你要摆弄一个1.5T的文件, 需要先把它切开, 分配到不同机器)为每一个分片分配一个MapTask任务,接下来会对每一个分片中的每一行数据进行处理,得到键值对(key,value),其中key为偏移量,value为一行的内容。准备给咱们的自己的map方法。执行完咱自己的map方法,便进入shuffle阶段。马克-to-win @ 马克java社区:为提高效率,mapreduce会把我们的写出的结果先存储到map节点的“环形内存缓冲区”(不深入探讨),当写入的数据量达到预先设置的阙值后(默认80%)便会启动溢出(spill)线程将缓冲区中的那部分数据溢出写(spill)到磁盘的临时文件中,可能会产生很多,并在写入前根据key进行排序(sort)和合并(combine,本章不讨论)。马克-to-win @ 马克java社区:当我们map任务完成溢出写后,mapreduce会对磁盘中这个map任务产生的所有临时spill文件中的相同partition(本章不讲, 本章只讲一个partition,即一个reducer的情况)合并到一起,并对各个partition中的数据再次排序(sort),生成最终的文件,即生成key和对应的value-list。马克-to-win @ 马克java社区:之后, reduce task在执行我们的reduce方法之前的工作就是不断地拉取所有节点的map task的最终结果,然后不断地做merge,最后合并成相对于一个分区的大文件(如果拉取的所有map数据总量都没有超过内存缓冲区大小,则数据就只存在于内存中),然后按key做sort排序(无论这个过程发生在内存还是磁盘,Reduce shuffle过程会输出一个有序merged的数据块。),排序之后紧接着分组(本章不讲,就是一组),分组完成后才将整个文件交给我们的reduce方法处理。
马克-to-win:上图是shuffle的官方流程图:
我们的实验是在一台机器上做的,即一个节点,但按照一个三台集群来讲, 也是可以的,现在假设三行文字在三台不同的机器上。
节点1:
输入:“hello a hello win”
输出:(hello,1),(a,1),(hello,1),(win,1)
放在下图的1位置的数据为排序且merged:(a,1),<"hello",<1,1>>,(win,1),之后被拉取到2位置。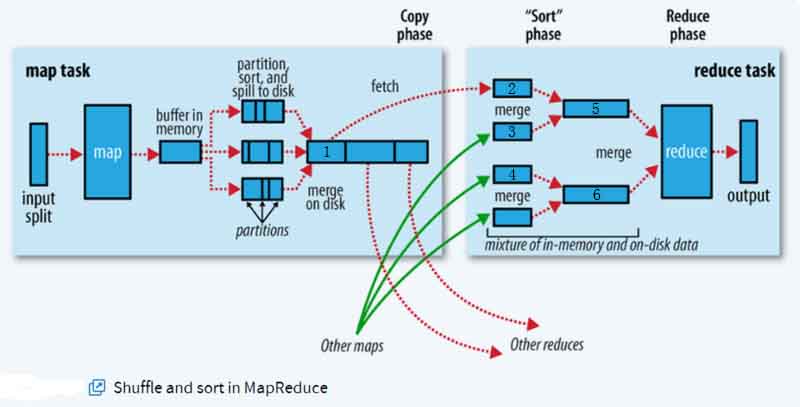
节点2:
输入:“hello a to”
输出:(hello,1),(a,1),(to,1)
放在下图的1位置的数据为排序且merged:(a,1),(hello,1),(to,1),之后被拉取到3位置。
节点3:
输入:“hello mark”
输出:(hello,1),(mark,1)
放在下图的1位置的数据为排序且merged:(hello,1),(mark,1),之后被拉取到4位置。
在2,3,4位置经过marge,最终一种结果可能是:位置5是<"a",<1,1>>,<"hello",<1,1,1,1>>,6是(mark,1),(to,1),(win,1)或者是:位置5是 <"a",<1,1>>,6是:<"hello",<1,1,1,1>>,(mark,1),(to,1),(win,1),或者是其他结果,都无所谓,(为什么无所谓? 因为无论中间过程怎么样?结果都一样) 因为最终还会merge成一个文件,是sorted。<"a",<1,1>>,<"hello",<1,1,1,1>>,(mark,1),(to,1),(win,1)
以下图片来自于hadoop官网。意思很清楚,很有助于大家理解。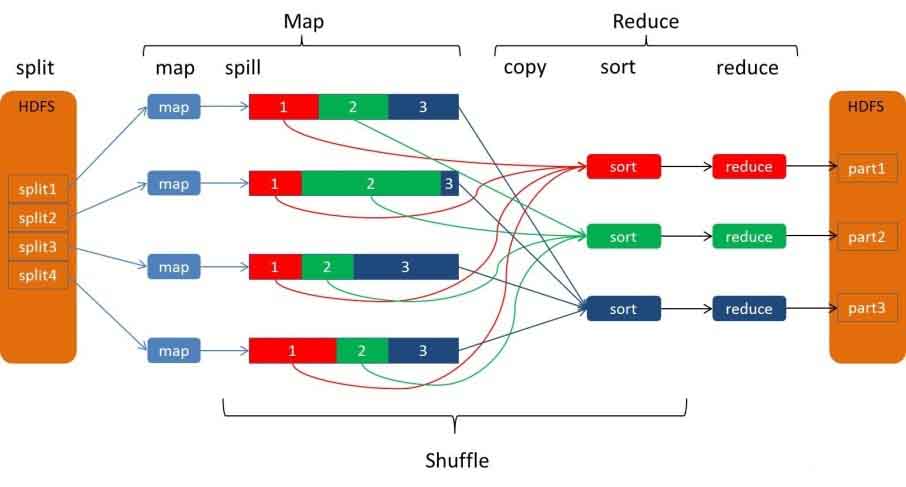
 分类导航
分类导航