

 个人中心
个人中心 退出
退出




DBOutputFormat把MapReduce结果输出到mysql中
DBOutputFormat把MapReduce结果输出到mysql中
马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
现在有一个需求:就是如何使用DBOutputFormat把MapReduce产生的结果输出到mysql中。
package com;
import java.io.File;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class mysqlTest {
public static class MytableWritable implements DBWritable {
String name;
int age;
public MytableWritable() {
}
public MytableWritable(String name, int age) {
this.name = name;
this.age = age;
}
public void write(PreparedStatement statement) throws SQLException {
System.out.println("here a flag");
/*DBOutputFormat.setOutput(job, "hadoop", "name", "age"); 下面的 1 和2都是参照以上的代码来的*/
statement.setString(1, this.name);
statement.setInt(2, this.age);
}
public void readFields(ResultSet resultSet) throws SQLException {
/*因为不用从数据库中读,所以可以这里屏蔽代码, 因为上面是接口,所以必须实现这个方法*/
// System.out.println("readFields ResultSet");
// this.name = resultSet.getString(1);
// this.age = resultSet.getInt(2);
}
/*下一段代码在此程序中没用到。 */
public String toString() {
return new String(this.name + " " + this.age);
}
}
public static class TokenizerMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
/* 输入数据
o1abc 45
o2kkk 77
*/
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
public static class IntSumReducer extends Reducer<LongWritable, Text, MytableWritable, MytableWritable> {
String name1;
protected void reduce(LongWritable key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
/*这是第一次见到key是map中原封不动的传到这里来,还是文件中的位置。*/
StringBuilder value = new StringBuilder();
for(Text text : values){
System.out.println("text is "+text);
value.append(text);
System.out.println("value is "+value);
}
System.out.println("for 外面了");
String[] fieldArr = value.toString().split("\t");
String name = fieldArr[0].trim();
int age = 0;
try{
age = Integer.parseInt(fieldArr[1].trim());
}catch(NumberFormatException e){
}
context.write(new MytableWritable(name, age), null);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/test", "root", "1234");
conf.set("name", "马克-to-win");
Job job = new Job(conf, "word count");
job.setJarByClass(mysqlTest.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
/*
void org.apache.hadoop.mapreduce.Job.setOutputFormatClass(Class<? extends OutputFormat> cls)
Set the OutputFormat for the job.
Parameters:cls the OutputFormat to use
*/
job.setOutputFormatClass(DBOutputFormat.class);
/*
void org.apache.hadoop.mapreduce.lib.db.DBOutputFormat.setOutput(Job job, String tableName, String... fieldNames) throws IOException
Parameters:job
The jobtableName
The table to insert data into
fieldNames The field names in the table.*/
DBOutputFormat.setOutput(job, "hadoop", "name", "age");
File file = new File("e:/temp/output");
if (file.exists() && file.isDirectory()) {
deleteFile(file);
}
FileInputFormat.setInputPaths(job, new Path("e:/temp/input/mysql.txt"));
System.out.println("mytest hadoop successful");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static boolean deleteFile(File dirFile) {
if (!dirFile.exists()) {
return false;
}
if (dirFile.isFile()) {
return dirFile.delete();
} else { /* 空目录就不进入for循环了, 进入到下一句dirFile.delete(); */
for (File file : dirFile.listFiles()) {
deleteFile(file);
}
}
return dirFile.delete();
}
}
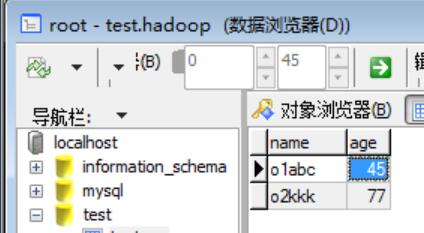
输入文件:
o1abc 45
o2kkk 77
输出到数据库是:
 分类导航
分类导航