

 个人中心
个人中心 退出
退出




MapReduce当中自定义输出:多文件输出MultipleOutputs
自定义输出:多文件输出MultipleOutputs
马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
马克-to-win @ 马克java社区:对于刚才的单独订单topN的问题,如果需要把单独的订单id的记录放在自己的一个文件中,并以订单id命名。怎么办?multipleOutputs可以帮我们解决这个问题。注意:和我们本章开始讲的多文件输出不一样的是,这里的多文件输出还可以跟程序的业务逻辑绑定在一起,比如文件的名字和订单有关系且把此个订单的最大值放在文件当中。
multipleOutputs的用法可以见底下的程序。
package com;
import java.io.File;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class MultipleOutputsTest {
public static class TokenizerMapper extends Mapper<Object, Text, Text, DoubleWritable> {
/*
o1abc,p2,250.0
o2kkk,p3,500.0
o2kkk,p4,100.0
o2kkk,p5,700.0
o3mmm,p1,150.0
o1abc,p1,200.0
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("key is " + key.toString() + " value is " + value.toString());
String line = value.toString();
String[] fields = line.split(",");
String orderId = fields[0];
double amount = Double.parseDouble(fields[2]);
DoubleWritable amountDouble = new DoubleWritable(amount);
context.write(new Text(orderId), amountDouble);
}
}
public static class IntSumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
DoubleWritable resultDouble = new DoubleWritable(0.0);
private MultipleOutputs<Text, DoubleWritable> multipleOutputs;
protected void setup(Context context) throws IOException, InterruptedException {
multipleOutputs = new MultipleOutputs<Text, DoubleWritable>(context);
}
public void reduce(Text key, Iterable<DoubleWritable> values, Context context)
throws IOException, InterruptedException {
System.out.println("reduce key is " + key.toString());
double max = Double.MIN_VALUE;
for (DoubleWritable v2 : values) {
if (v2.get() > max) {
max = v2.get();
}
}
resultDouble.set(max);
String fileName = key.toString().substring(0, 4);
System.out.println("fileName is "+ fileName);
/* multipleOutputs用于map输出时采用:name-m-nnnnn 形式的文件名,用于reduce输出时采用name-r-nnnnn 形式的文件名,其中 name 是由程序设定的任意名字, nnnnn 是一个指明块号的整数(从 0 开始)。块号保证在相同名字name情况下不会冲突
void MultipleOutputs.write(Text key, DoubleWritable value, String baseOutputPath)
Write key 和 value to an output file name.
Parameters:key:the key。value: the value。 baseOutputPath: base-output path to write the record to. */
multipleOutputs.write(key, resultDouble, fileName);
// context.write(key, resultDouble);
}
protected void cleanup(Context context) throws IOException ,InterruptedException{
multipleOutputs.close();
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(MultipleOutputsTest.class);
job.setMapperClass(TokenizerMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
File file = new File("e:/temp/output");
if (file.exists() && file.isDirectory()) {
deleteFile(file);
}
FileInputFormat.setInputPaths(job, new Path("e:/temp/input/multipleOutput.txt"));
FileOutputFormat.setOutputPath(job, new Path("e:/temp/output"));
System.out.println("mytest hadoop successful");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static boolean deleteFile(File dirFile) {
if (!dirFile.exists()) {
return false;
}
if (dirFile.isFile()) {
return dirFile.delete();
} else { /* 空目录就不进入for循环了, 进入到下一句dirFile.delete(); */
for (File file : dirFile.listFiles()) {
deleteFile(file);
}
}
return dirFile.delete();
}
}
输入文件是:
o1abc,p2,250.0
o2kkk,p3,500.0
o2kkk,p4,100.0
o2kkk,p5,700.0
o3mmm,p1,150.0
o1abc,p1,200.0
输出文件是:
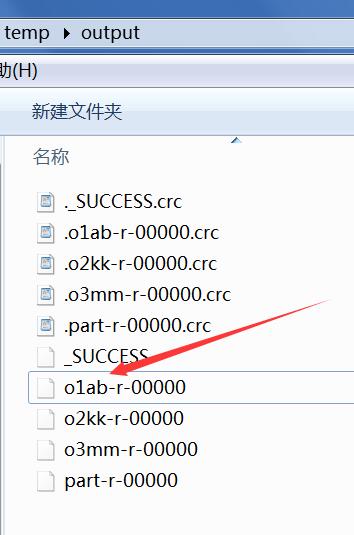
console的输出是:
reduce key is 马克-to-win @ 马克java社区:o1abc
name is o1ab
INFO - File Output Committer Algorithm version is 1
reduce key is 马克-to-win @ 马克java社区:o2kkk
name is o2kk
INFO - File Output Committer Algorithm version is 1
reduce key is 马克-to-win @ 马克java社区:o3mmm
name is o3mm
o1ab-r-00000这个文件的输出是:
o1abc 250.0
 分类导航
分类导航