

 个人中心
个人中心 退出
退出




hadoop在eclipse当中如何添加源码
/*org.apache.hadoop.mapreduce.Mapper.Context,java.lang.InterruptedException, 想看map的源代码,按control,点击,出现Attach Source Code,点击External Location/External File,找到源代码,就在Source目录下,,D:\hadoop-2.7.4\src
其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
(购买完整教程)
*/马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("key is 马克-to-win @ 马克java社区 "+key.toString()+" value is "+value.toString());
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
System.out.println("reduce key is 马克-to-win @ 马克java社区 "+key.toString());
int sum = 0;
for (IntWritable val : values) {
int valValue=val.get();
System.out.println("valValue is"+valValue);
sum += valValue ;
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
/*非 0 的状态码表示异常终止。 */
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在src目录下,创建log4j.properties文件(这样可以看到输出反应)
#log4j.rootLogger=debug,stdout,R
log4j.rootLogger=info,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%
log4j.logger.com.codefutures=DEBUG
紧接着,配置运行参数
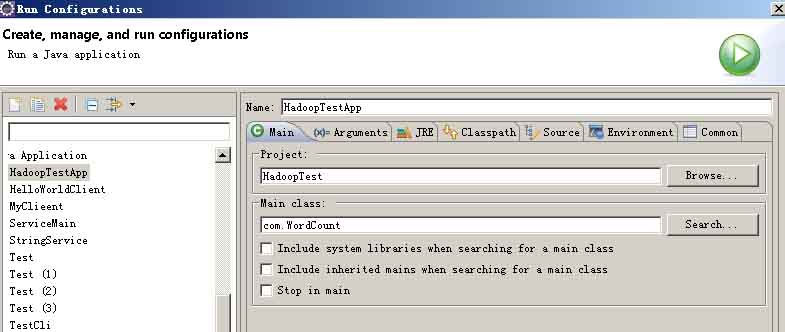
右击项目名称,选择“run as”-“run configurations”,在main中browse和search成为如下图。在“Arguments”里加入两个参数(其中第二个参数hdfs://localhost:9000/output2必须不存在)
hdfs://localhost:9000/README.txt
hdfs://localhost:9000/output2
注意:马克-to-win @ 马克java社区:通常来讲,mapreduce输入输出都需要在一个hdfs分布式文件系统,当然也可以是其他的文件系统。这样运行作业的输入文件必须首先上传到hdfs,输出文件自然也在hdfs上。mapreduce作业在开始时会对输入文件进行切分,目的是方便多个map任务同时进行处理,提高处理效率,实现分布式计算。所以,我们编的程序逻辑对hadoop集群也适用。
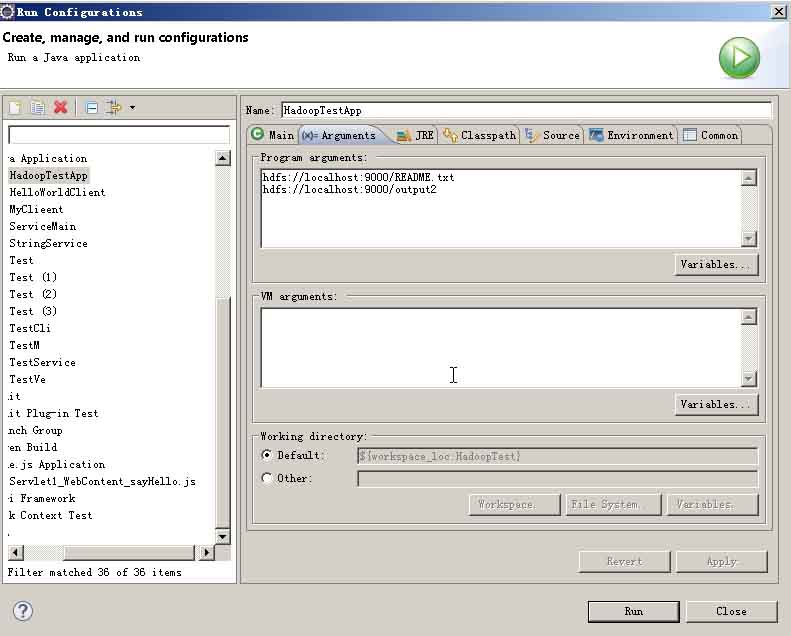
然后点击“Run”即可运行。
6)结果查看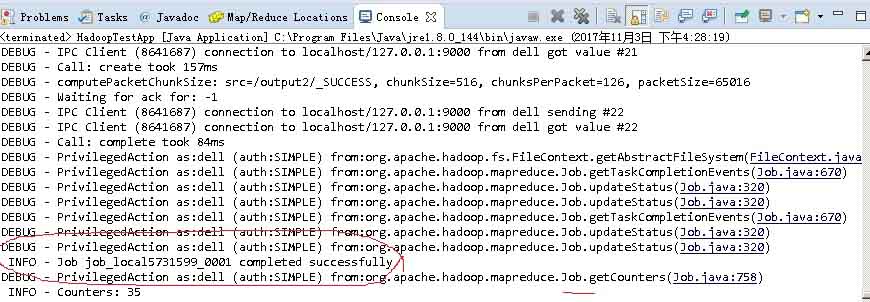
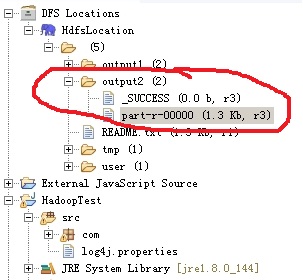
打开新生成的part-r-00000文件:
a 2
hello 4
mark 1
to 1
win 1
里面给出了第一个参数中README.txt文件中每个字的出现次数。这正是WordCount要做的事情。只不过这里用的是MapReduce的并行开发方法。这正是我们想要的结果。
源文件:
hello a hello win
hello a to
hello mark
执行结果是:
INFO - Initializing JVM Metrics with processName=JobTracker, sessionId=
INFO - Total input paths to process : 1
INFO - number of splits:1
INFO - Submitting tokens for job: job_local936781335_0001
INFO - Running job: job_local936781335_0001
INFO - Waiting for map tasks
INFO - Starting task: attempt_local936781335_0001_m_000000_0
INFO - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1d5f80b
INFO - Processing split: hdfs://localhost:9000/README.txt:0+31
INFO - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
key is 马克-to-win @ 马克java社区 0 value is hello a hello win
key is 马克-to-win @ 马克java社区 19 value is hello a to
key is 马克-to-win @ 马克java社区 31 value is hello mark
INFO - Starting flush of map output
INFO - Spilling map output
INFO - Finished spill 0
INFO - Task:attempt_local936781335_0001_m_000000_0 is done. And is in the process of committing
INFO - map
INFO - Task 'attempt_local936781335_0001_m_000000_0' done.
INFO - Finishing task: attempt_local936781335_0001_m_000000_0
INFO - map task executor complete.
INFO - Waiting for reduce tasks
INFO - Starting task: attempt_local936781335_0001_r_000000_0
INFO - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@490476
INFO - org.apache.hadoop.mapreduce.task.reduce.Shuffle@e7707f
INFO - MergerManager: memoryLimit=181665792, maxSingleShuffleLimit=45416448, mergeThreshold=119899424, ioSortFactor=10, memToMemMergeOutputsThreshold=10
INFO - attempt_local936781335_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
INFO - localfetcher#1 about to shuffle output of map attempt_local936781335_0001_m_000000_0 decomp: 68 len: 72 to MEMORY
INFO - Read 68 bytes from map-output for attempt_local936781335_0001_m_000000_0
INFO - closeInMemoryFile -> map-output of size: 68, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->68
INFO - EventFetcher is interrupted.. Returning
INFO - 1 / 1 copied.
INFO - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
INFO - Merging 1 sorted segments
INFO - Down to the last merge-pass, with 1 segments left of total size: 60 bytes
INFO - Merged 1 segments, 68 bytes to disk to satisfy reduce memory limit
INFO - Merging 1 files, 72 bytes from disk
INFO - Merging 1 sorted segments
INFO - 1 / 1 copied.
reduce key is 马克-to-win @ 马克java社区 a
valValue is1
valValue is1
reduce key is 马克-to-win @ 马克java社区 hello
valValue is1
valValue is1
valValue is1
valValue is1
reduce key is 马克-to-win @ 马克java社区 mark
valValue is1
reduce key is 马克-to-win @ 马克java社区 to
valValue is1
reduce key is 马克-to-win @ 马克java社区 win
valValue is1
INFO - map 100% reduce 0%
INFO - Task:attempt_local936781335_0001_r_000000_0 is done. And is in the process of committing
INFO - 1 / 1 copied.
INFO - Task attempt_local936781335_0001_r_000000_0 is allowed to commit now
INFO - Saved output of task 'attempt_local936781335_0001_r_000000_0' to hdfs://localhost:9000/output9/_temporary/0/task_local936781335_0001_r_000000
INFO - reduce > reduce
INFO - Task 'attempt_local936781335_0001_r_000000_0' done.
INFO - Finishing task: attempt_local936781335_0001_r_000000_0
INFO - reduce task executor complete.
INFO - map 100% reduce 100%
INFO - Job job_local936781335_0001 completed successfully
INFO - Counters: 35
File System Counters
FILE: Number of bytes read=486
FILE: Number of bytes written=599966
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=62
HDFS: Number of bytes written=26
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=54
Input split bytes=97
Combine input records=0
Combine output records=0
Reduce input groups=4
Reduce shuffle bytes=72
Reduce input records=6
Reduce output records=4
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=46
Total committed heap usage (bytes)=243499008
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=31
File Output Format Counters
Bytes Written=26
 分类导航
分类导航