

 个人中心
个人中心 退出
退出




Windows Eclipse Scala编写WordCount程序
马克-to-win @ 马克java社区:无需启动hadoop,因为我们用的是本地文件。先像原来一样,做一个普通的scala项目和Scala Object。
马克- to-win:马克 java社区:防盗版实名手机尾号: 73203。
但这里一定注意版本是2.10.6,因为缺省的不好使。改的方法是:右击项目/properties/Scala Compiler.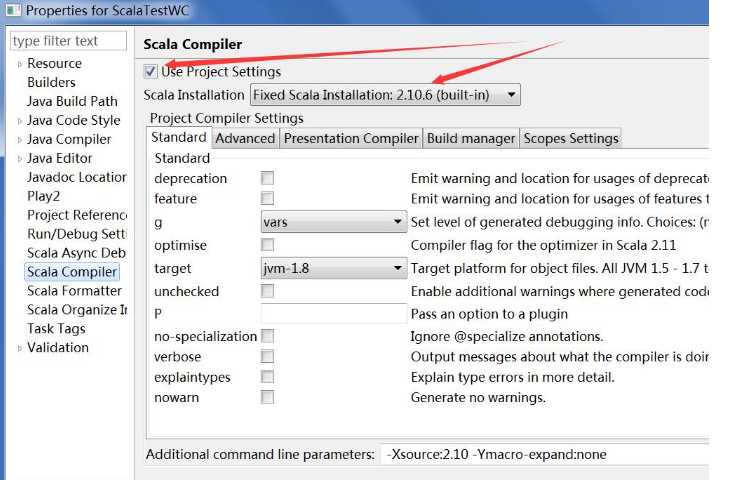
2)像spark的java版WordCount项目一模一样导包,什么都一样。(导包的方法和原来普通的java项目一样)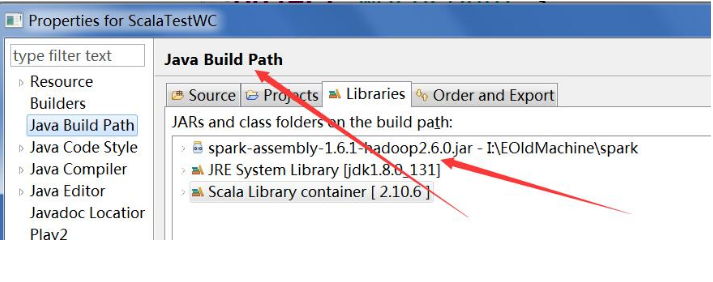
例:5.1
package com
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf();
conf.setAppName("First Spark scala App马克-to-win @ 马克java社区:!");
conf.setMaster("local");
val sc = new SparkContext(conf);
val lines = sc.textFile("E://temp//input//friend.txt", 1);
val words = lines.flatMap { lines => lines.split(" ") };
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))
}
}
输入文件:(friend)
o1abc 45
o2kkk 77
输出结果:(console当中)
o1abc:1
45:1
o2kkk:1
77:1
以上程序,只需运行通。分析在下面。
例:5.2
package com
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount {
def main(args: Array[String]) {
val conf = new SparkConf();
conf.setAppName("Hello Mark-to-win Spark scala!");
conf.setMaster("local");
val sc = new SparkContext(conf);
/*原文件是:o1abc 45
o1abc 77
o1abc o1abc */
val lines = sc.textFile("E://temp//input//friend.txt");
/*打印出下一句: lines o1abc 45,o1abc 77,o1abc o1abc*/
println("lines "+lines.collect().mkString(","))
val words = lines.flatMap { linesqq => linesqq.split(" ") };
/*下一步打印出:words o1abc,45,o1abc,77,o1abc,o1abc*/
println("words "+words.collect().mkString(","))
/*下一步打印出:pairs (o1abc,1),(45,1),(o1abc,1),(77,1),(o1abc,1),(o1abc,1)
(wordqq, 1) 必须加括号, 否则有语法错误。*/
val pairs = words.map { wordqq => (wordqq, 1) }
println("pairs "+pairs.collect().mkString(","))
val wordCounts = pairs.reduceByKey(_+_)
/*wordCounts (o1abc,4),(45,1),(77,1)*/
println("wordCounts 马克-to-win @ 马克java社区:防盗版实名手机尾号:73203"+wordCounts.collect().mkString(","))
/*o1abc:4
45:1
77:1*/
wordCounts.foreach(wordNumberPairqqq => println(wordNumberPairqqq._1 + ":" + wordNumberPairqqq._2))
}
}
/*
想做15行lines.collect(),先干13行sc.textFile。
想做18行words.collect(),先干16行lines.flatMap。(做16时,调用谁, 就不用管了。)
想做29行foreach,先干23行pairs.reduceByKey。
19/05/02 09:29:07 INFO SparkContext: Starting job: collect at WordCount.scala:15
19/05/02 09:29:07 INFO DAGScheduler: Got job 0 (collect at WordCount.scala:15) with 1 output partitions
19/05/02 09:29:07 INFO DAGScheduler: Submitting ResultStage 0 (E://temp//input//friend.txt MapPartitionsRDD[1] at textFile at WordCount.scala:13), which has no missing parents
19/05/02 09:29:08 INFO HadoopRDD: Input split: file:/E:/temp/input/friend.txt:0+31
19/05/02 09:29:08 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2080 bytes result sent to driver
19/05/02 09:29:08 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:15, took 0.808093 s
lines o1abc 45,o1abc 77,o1abc o1abc
19/05/02 09:29:08 INFO SparkContext: Starting job: collect at WordCount.scala:18
19/05/02 09:29:08 INFO DAGScheduler: Got job 1 (collect at WordCount.scala:18) with 1 output partitions
19/05/02 09:29:08 INFO DAGScheduler: Final stage: ResultStage 1 (collect at WordCount.scala:18)
19/05/02 09:29:08 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[2] at flatMap at WordCount.scala:16), which has no missing parents
19/05/02 09:29:08 INFO HadoopRDD: Input split: file:/E:/temp/input/friend.txt:0+31
19/05/02 09:29:08 INFO DAGScheduler: Job 1 finished: collect at WordCount.scala:18, took 0.083017 s
words o1abc,45,o1abc,77,o1abc,o1abc
19/05/02 09:29:08 INFO SparkContext: Starting job: collect at WordCount.scala:22
19/05/02 09:29:08 INFO DAGScheduler: Got job 2 (collect at WordCount.scala:22) with 1 output partitions
19/05/02 09:29:08 INFO DAGScheduler: Final stage: ResultStage 2 (collect at WordCount.scala:22)
19/05/02 09:29:08 INFO DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[3] at map at WordCount.scala:21), which has no missing parents
19/05/02 09:29:08 INFO HadoopRDD: Input split: file:/E:/temp/input/friend.txt:0+31
19/05/02 09:29:08 INFO DAGScheduler: Job 2 finished: collect at WordCount.scala:22, took 0.047819 s
pairs (o1abc,1),(45,1),(o1abc,1),(77,1),(o1abc,1),(o1abc,1)
19/05/02 09:29:08 INFO SparkContext: Starting job: collect at WordCount.scala:25
19/05/02 09:29:08 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:21)
19/05/02 09:29:08 INFO DAGScheduler: Got job 3 (collect at WordCount.scala:25) with 1 output partitions
19/05/02 09:29:08 INFO DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[3] at map at WordCount.scala:21), which has no missing parents
19/05/02 09:29:08 INFO HadoopRDD: Input split: file:/E:/temp/input/friend.txt:0+31
19/05/02 09:29:09 INFO Executor: Finished task 0.0 in stage 3.0 (TID 3). 2253 bytes result sent to driver
19/05/02 09:29:09 INFO DAGScheduler: ShuffleMapStage 3 (map at WordCount.scala:21) finished in 0.156 s
19/05/02 09:29:09 INFO DAGScheduler: Submitting ResultStage 4 (ShuffledRDD[4] at reduceByKey at WordCount.scala:23), which has no missing parents
19/05/02 09:29:09 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
19/05/02 09:29:09 INFO DAGScheduler: Job 3 finished: collect at WordCount.scala:25, took 0.395978 s
wordCounts 马克-to-win @ 马克java社区:(o1abc,4),(45,1),(77,1)
19/05/02 09:29:09 INFO SparkContext: Starting job: foreach at WordCount.scala:29
19/05/02 09:29:09 INFO DAGScheduler: Got job 4 (foreach at WordCount.scala:29) with 1 output partitions
19/05/02 09:29:09 INFO DAGScheduler: Submitting ResultStage 6 (ShuffledRDD[4] at reduceByKey at WordCount.scala:23), which has no missing parents
19/05/02 09:29:09 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
o1abc:4
45:1
77:1
19/05/02 09:29:09 INFO Executor: Finished task 0.0 in stage 6.0 (TID 5). 1165 bytes result sent to driver
19/05/02 09:29:09 INFO DAGScheduler: ResultStage 6 (foreach at WordCount.scala:29) finished in 0.047 s
*/
例:5.3
package com
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount1 {
def main(args: Array[String]) {
val conf = new SparkConf();
conf.setAppName("First Spark scala App!马克-to-win @ 马克java社区:");
conf.setMaster("local");
val sc = new SparkContext(conf);
/*原文件是:o1abc 45
o1abc 77
o1abc o1abc*/
val lines = sc.textFile("E://temp//input//friend.txt", 1);
/*打印出下一句: lines o1abc 45,o1abc 77,o1abc o1abc*/
// println("lines "+lines.collect().mkString(","))
val words = lines.flatMap { linesqq => linesqq.split(" ") };
/*下一步打印出:words o1abc,45,o1abc,77,o1abc,o1abc*/
// println("words "+words.collect().mkString(","))
/*下一步打印出:pairs (o1abc,1),(45,1),(o1abc,1),(77,1),(o1abc,1),(o1abc,1)
(wordqq, 1) 必须加括号, 否则有语法错误。*/
val pairs = words.map { wordqq => (wordqq, 1) }
// println("pairs "+pairs.collect().mkString(","))
val wordCounts = pairs.reduceByKey(_+_)
/*wordCounts (o1abc,4),(45,1),(77,1)*/
// println("wordCounts "+wordCounts.collect().mkString(","))
/*o1abc:4
45:1
77:1*/
wordCounts.foreach(wordNumberPairqqq => println(wordNumberPairqqq._1 + ":" + wordNumberPairqqq._2))
}
}
/*
过程:想干29行foreach, 先干21行words.map,在干23行pairs.reduceByKey。
SparkContext: Starting job: foreach at WordCount1.scala:29
DAGScheduler: Registering RDD 3 (map at WordCount1.scala:21)
DAGScheduler: Got job 0 (foreach at WordCount1.scala:29) with 1 output partitions
DAGScheduler: Final stage: ResultStage 1 (foreach at WordCount1.scala:29)
DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount1.scala:21), which has no missing parents
DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount1.scala:21)
TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2121 bytes)
Executor: Running task 0.0 in stage 0.0 (TID 0)
HadoopRDD: Input split: file:/E:/temp/input/friend.txt:0+31
Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver
TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 265 ms on localhost (1/1)
DAGScheduler: ShuffleMapStage 0 (map at WordCount1.scala:21) finished in 0.297 s
DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount1.scala:23), which has no missing parents
DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount1.scala:23)
TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, partition 0,NODE_LOCAL, 1894 bytes)
Executor: Running task 0.0 in stage 1.0 (TID 1)
ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
o1abc:4
45:1
77:1
Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver
TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 78 ms on localhost (1/1)
DAGScheduler: ResultStage 1 (foreach at WordCount1.scala:29) finished in 0.078 s
DAGScheduler: Job 0 finished: foreach at WordCount1.scala:29, took 0.664844 s
*/
例:5.4
package com
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount2 {
def main(args: Array[String]) {
val conf = new SparkConf();
conf.setAppName("First Spark scala App!马克-to-win @ 马克java社区:");
conf.setMaster("local");
val sc = new SparkContext(conf);
/*原文件是:o1abc 45
o1abc 77
o1abc o1abc*/
val lines = sc.textFile("E://temp//input//friend.txt", 1);
/*打印出下一句: lines o1abc 45,o1abc 77,o1abc o1abc*/
// println("lines "+lines.collect().mkString(","))
val words = lines.flatMap { linesqq => linesqq.split(" ") };
/*下一步打印出:words o1abc,45,o1abc,77,o1abc,o1abc*/
// println("words "+words.collect().mkString(","))
/*下一步打印出:pairs (o1abc,1),(45,1),(o1abc,1),(77,1),(o1abc,1),(o1abc,1)
(wordqq, 1) 必须加括号, 否则有语法错误。*/
val pairs = words.map { wordqq => (wordqq, 1) }
println("pairs "+pairs.collect().mkString(","))
val wordCounts = pairs.reduceByKey(_+_)
/*wordCounts (o1abc,4),(45,1),(77,1)*/
// println("wordCounts "+wordCounts.collect().mkString(","))
/*o1abc:4
45:1
77:1*/
wordCounts.foreach(wordNumberPairqqq => println(wordNumberPairqqq._1 + ":" + wordNumberPairqqq._2))
}
}
/*
过程:想干22行pairs.collect(), 先干21行words.map。 至于21前面怎么样, 不用管了。
19/05/04 18:54:37 INFO SparkContext: Starting job: collect at WordCount2.scala:22
DAGScheduler: Got job 0 (collect at WordCount2.scala:22) with 1 output partitions
DAGScheduler: Final stage: ResultStage 0 (collect at WordCount2.scala:22)
DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at map at WordCount2.scala:21), which has no missing parents
DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at map at WordCount2.scala:21)
*/
例:5.5
package com
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount3 {
def main(args: Array[String]) {
val conf = new SparkConf();
conf.setAppName("First Spark scala App!马克-to-win @ 马克java社区:");
conf.setMaster("local");
val sc = new SparkContext(conf);
/*原文件是:o1abc 45
o1abc 77
o1abc o1abc*/
val lines = sc.textFile("E://temp//input//friend.txt", 1);
/*打印出下一句: lines o1abc 45,o1abc 77,o1abc o1abc*/
// println("lines "+lines.collect().mkString(","))
val words = lines.flatMap { linesqq => linesqq.split(" ") };
/*下一步打印出:words o1abc,45,o1abc,77,o1abc,o1abc*/
println("words "+words.collect().mkString(","))
/*下一步打印出:pairs (o1abc,1),(45,1),(o1abc,1),(77,1),(o1abc,1),(o1abc,1)
(wordqq, 1) 必须加括号, 否则有语法错误。*/
val pairs = words.map { wordqq => (wordqq, 1) }
// println("pairs "+pairs.collect().mkString(","))
val wordCounts = pairs.reduceByKey(_+_)
/*wordCounts (o1abc,4),(45,1),(77,1)*/
// println("wordCounts "+wordCounts.collect().mkString(","))
/*o1abc:4
45:1
77:1*/
wordCounts.foreach(wordNumberPairqqq => println(wordNumberPairqqq._1 + ":" + wordNumberPairqqq._2))
}
}
/*
过程:想干18行words.collect(), 先干16行lines.flatMap。至于16前面怎么样,不用管了。
想干15行, 先干13行
19/05/04 19:10:23 INFO DAGScheduler: Final stage: ResultStage 0 (collect at WordCount3.scala:18)
19/05/04 19:10:23 INFO DAGScheduler: Parents of final stage: List()
19/05/04 19:10:23 INFO DAGScheduler: Missing parents: List()
19/05/04 19:10:23 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[2] at flatMap at WordCount3.scala:16), which has no missing parents
*/
 分类导航
分类导航