

 个人中心
个人中心 退出
退出




架构:第七章:基于Dubbo+Zookeeper项目架构
Dubbo:
简单的介绍一下Dubbo?(Dubbo是什么)
dubbo就是个服务调用的东东。
为什么怎么说呢?
因为Dubbo是由阿里开源的一个RPC分布式框架
那么RPC是什么呢?
就是不同的应用部署到不同的服务器上,应用之间想要调用没有办法直接调用,因为不在一个内存空间,需要通过网络通讯来调用,或者传达调用的数据。而且RPC会将远程调用的细节隐藏起来,让调用远程服务像调用本地服务一样简单。
dubbo的架构有哪些?
主要有五个角色/核心组件,分为是Container(容器)、Provider(服务的提供方)、Registry(注册中心)、Consumer(服务的消费方)、Monitor(监控中心)。
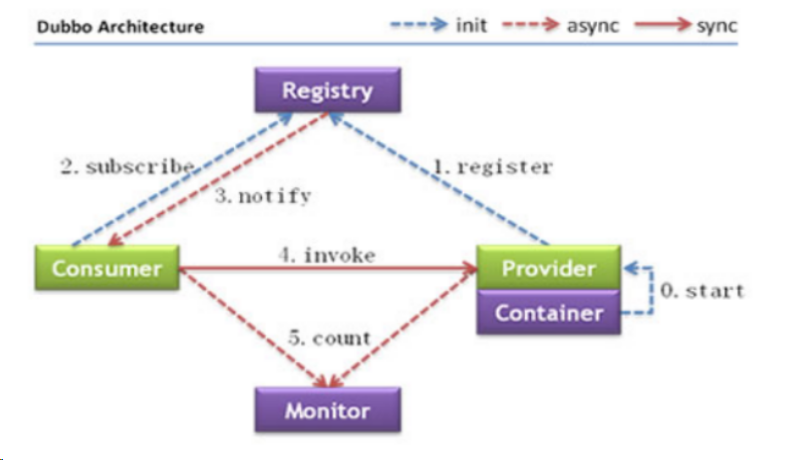
容器:
主要负责启动、加载、运行服务提供者;
1.服务提供者在启动时:向注册中心注册自己提供的服务;服务消费者向注册中心订阅自己的服务;
2.注册中心返回服务提供者列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者;
3.对于服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另外一台调用;
4.服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心;
注册中心:
注册中心只负责地址的注册和查找,相当于我们的目录服务,只有在容器启动时,服务提供者和调用者与注册中心交互,整个过程,注册中心不参与数据传输,不转发请求,压力较小 (“两不一小”);
注册中心宕机问题:
注册中心会部署集群
1.如果集群中的任意一台宕机之后,将自动切换到另外一台,不会影响已运行的提供者和消费者;
2.如果集群中所有注册中心全部宕机之后,服务提供者和服务消费者仍能通过本地缓存通讯;
3.数据库宕机后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务;
监控中心:
监控中心负责统计各服务调用次数、调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
监控中心宕机不影响使用,只是丢失部分的采样数据;
dubbo-admin可以通过监控中心的可视化界面,进行禁止服务和截止消费者(大量恶意访问的ip);
服务提供者:
1.服务提供者出现宕机,如果任意一台宕机,由于服务提供者没有状态,不影响使用;
2.如果所有的服务提供者全部宕机之后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复;
3.服务提供者出现变更,比如增加新的机器部署,注册中心基于长连接将推送服务提供者信息给消费者;
Dubbo在项目中怎么用的?
1.dubbo在项目中主要用来实现不同系统之间的服务调用。
2.由于项目是按照不同的功能分了不同的系统,按照三层架构又分了不同的服务,其中
3.三层架构中的控制层作为服务的消费方,业务层和持久层共同作为服务的发布方。
这样的架构实现了系统的服务化,提高了开发效率,实现了业务的解耦。
3.Dubbo都支持什么协议?这些协议有什么不同点?项目使用的是什么协议?
Dubbo支持Dubbo协议、RMI协议、hessian协议、Http协议等
Dubbo协议:缺省协议、采用了单一长连接和NIO异步通讯、使用线程池并发处理请求,能减少握手和加大并发效率、采用的是Hession二进制序列化、性能较好,推荐使用。
主要应用于传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,由于是单一连接,因为尽量不要传输大文件。
RMI协议:采用JDK标准的RMI协议(基于TCP协议)、堵塞式短连接、JDK标准序列化方式、同步通讯。适用于消费者和提供者个数差不多的,可传文件。测试发现偶尔会连接失败,需要重建Stub。
Hessian协议:采用http通讯,采用Servlet暴露服务,多连接短连接的同步传输方式,采用hessian的二进制序列化,适合提供者比消费者多。
项目中使用的是默认Dubbo协议(其他两种简单的知道就行),因为项目的特点主要是并发大、消费者要比提供者多。
Zookeeper:
简单介绍一下zookeeper?
1.Zookeeper是Apache Hadoop的一个子项目,作为分布式协调作用(类似于我们的大脑),树形的目录结构,支持变更操作,同时也是Dubbo官方推荐的注册中心。
2.Zookeeper之所以能用来作为dubbo的注册中心来使用,主要是应用到dubbo的命名功能。3.在SOA架构、集群和分布式环境下,子项目之间的调用关系会变得越来越复杂,因为需要一个服务器专门给我们管理服务的信息和调节、管理这些服务,让我们的侧重点放在项目中的业务上,因为zookeeper的命名功能就可以充当这样一个服务器。
项目中主要用zookeeper作为Dubbo的注册中心,集中管理所有服务的URL;同时集中的管理集群的配置。
Zookeeper的实现原理?(工作原理)
Zookeeper会维护一个类似于标准的文件系统的具有层次关系的数据结构。这个文件系统中每个子目录项都被称为znode节点,这个znode节点也可以有子节点,每个节点都可以存储数据,客户端也可以对这些node节点进行getChildren,getData,exists方法,同时也可以在znode tree路径上设置watch(类似于监听),当watch路径上发生节点create、delete、update的时候,会通知到client。client可以得到通知后,再获取数据,执行业务逻辑操作。Zookeeper 的作用主要是用来维护和监控存储的node节点上这些数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理。
为什么要用zookeeper作为dubbo的注册中心?能选择其他的吗?
Zookeeper的数据模型是由一系列的Znode数据节点组成,和文件系统类似。
zookeeper的数据全部存储在内存中,性能高;
zookeeper也支持集群,实现了高可用;
同时基于zookeeper的特性,也支持事件监听(服务的暴露方发生变化,可以进行推送),所以zookeeper适合作为dubbo的注册中心区使用。
redis、Simple也可以作为dubbo的注册中心来使用。
Redis:
用key-value(Hash)来存储数据
主key:服务器名和类型
Map中的key:url地址
Map中的value:过期时间,判断脏数据,脏数据由监控中心删除(要求服务器时间必须相同)
利用redis中的Publish/Subscribe事件通知数据变更
总之,redis作为注册中心来使用的话,支持集群,性能高,但是要求所有服务器的时间必须同步,要求较高。(redis作为注册中心来使用,有的公司也在采用)
Simple:
本身就是一个普通的dubbo服务,能减少第三方依赖,不支持集群,不适合生产环境。
项目中主要用zookeeper做了什么?(作用)
作为注册中心用;
主要是在服务器上搭建zookeeper,其次在spring管理的dubbo的配置文件中配置(暴露方和消费方都需要配置)
 分类导航
分类导航