

 个人中心
个人中心 退出
退出




全文检索工具solr:第二章:安装配置
linux安装Solr:可以参考全文检索工具elasticsearch:第二章:安装配置配置类似
点击下载solr
windows中Solr安装
1:安装 Tomcat,解压缩即可。
2:解压 solr。
3:把 solr 下的dist目录solr-4.10.3.war部署到 Tomcat\webapps下(去掉版本号)。
4:启动 Tomcat解压缩 war 包
5:把solr下example/lib/ext 目录下的所有的 jar 包,添加到 solr 的工程中(\WEB-INF\lib目录下)。
6:创建一个 solrhome 。solr 下的/example/solr 目录就是一个 solrhome。复制此目录到C盘改名为solrhome
7:关联 solr 及 solrhome。需要修改 solr 工程的 web.xml 文件。
- <env-entry>
-
- <env-entry-name>solr/home</env-entry-name>
-
- <env-entry-value>c:\solrhome</env-entry-value>
-
- <env-entry-type>java.lang.String</env-entry-type>
-
- </env-entry>
8:启动 Tomcat
http://IP:8080/solr/
localhost:8080
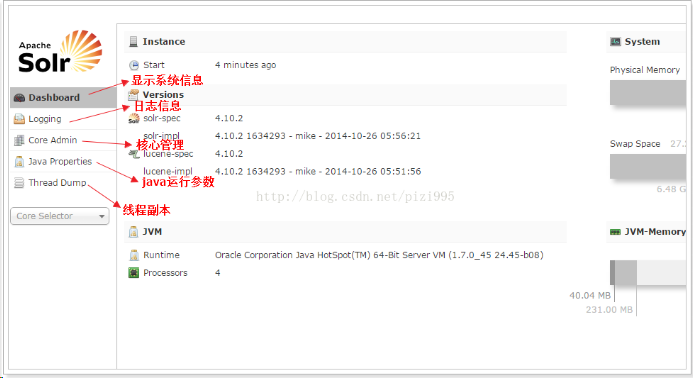
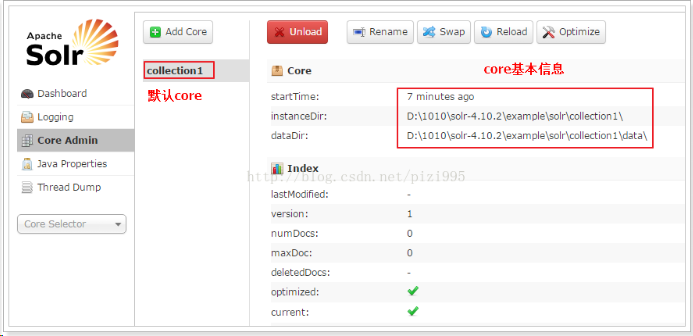
solr页面

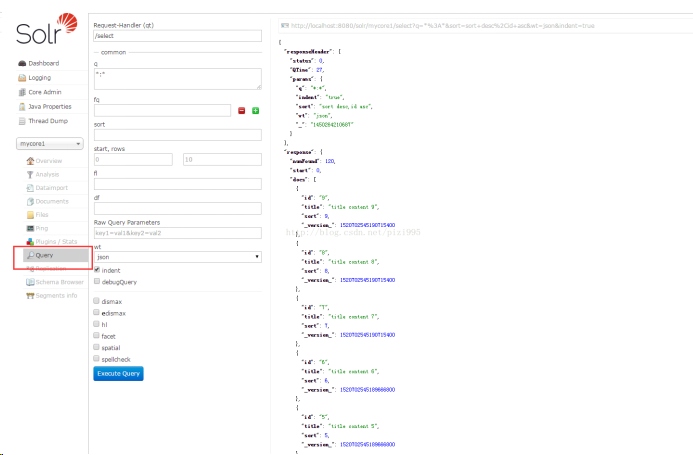
基本查询
q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=*:*,
fl 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
start 返回结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
sort 排序方式,例如id desc 表示按照 “id” 降序
wt (writer type)指定输出格式,有 xml, json, php等
fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
df 默认的查询字段,一般默认指定。
qt (query type)指定那个类型来处理查询请求,一般不用指定,默认是standard。
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version 查询语法的版本,建议不使用它,由服务器指定默认值。
检索运算符
“:” 指定字段查指定值,如返回所有值*:*
“?” 表示单个任意字符的通配
“*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
“~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
AND、|| 布尔操作符
OR、&& 布尔操作符
NOT、!、-(排除操作符不能单独与项使用构成查询)
“+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在²
( ) 用于构成子查询
[] 包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510]
{} 不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510}
IK Analyzer配置
步骤:
1、把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
2、创建WEB-INF/classes文件夹 把扩展词典、停用词词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下。
3、修改 Solrhome 的 schema.xml 文件(C:\solrhome\collection1\conf),配置一个 FieldType,使用 IKAnalyzer
- <fieldType name=" text_ik_javawxid" class="solr.TextField">
-
- <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
-
- </fieldType
FIle可以理解为数据库中的字段,相当于列
配置业务域
域
要想让solr能够存储信息,我们还得定义列,也叫域,相当于数据库中的字段
修改solrhome的schema.xml 文件 设置业务系统 Field
<field name="sku_name" type="string" indexed="true" stored="true"/>
<field name="sku_price" type="double" indexed="true" stored="true"/>
<field name="sku_desc" type=" text_ik_javawxid" indexed="true" stored="true"/>
<field name="sku_default_img" type="string" stored="true"/>
name:指定域的名称
type:指定域的类型
indexed:是否索引,可以按照该列进行搜索
stored:是否存储
required:是否必须
multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。
复制域
可以把一些列复制到一个域中, 是一个逻辑上的概念,不是物理上的概念不是把值真正的复制到域中,这样会浪费内存空间
多个域组合在一起进行检索
Stored = false 必须为false 因为是逻辑上的域对象
<field name="sku_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!—指定是从哪些域中拷贝的-->
<copyField source="sku_name" dest=" sku_keywords "/>
<copyField source="sku_price" dest=" sku_keywords "/>
<copyField source="sku_desc" dest=" sku_keywords "/>
注意:空格要去掉
动态域(这个不常用,可以不用配置)
当我们需要动态扩充字段时,我们需要使用动态域。比如规格的值是不确定的,所以我们需要使用动态域来实现。需要实现的效果如下:
配置:
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
 分类导航
分类导航