

 个人中心
个人中心 退出
退出




面试官:您能说说序列化和反序列化吗?是怎么实现的?什么场景下需要它?
作者:xcbeyond
疯狂源自梦想,技术成就辉煌!微信公众号:《程序猿技术大咖》号主,专注后端开发多年,拥有丰富的研发经验,乐于技术输出、分享,现阶段从事微服务架构项目的研发工作,涉及架构设计、技术选型、业务研发等工作。对于Java、微服务、数据库、Docker有深入了解,并有大量的调优经验。
序列化和反序列化是Java中最基础的知识点,也是很容易被大家遗忘的,虽然天天使用它,但并不一定都能清楚的说明白。我相信很多小伙伴们掌握的也就几句概念、关键字(Serializable)而已,如果深究问一下序列化和反序列化是如何实现、使用场景等,就可能不知所措了。在每次我作为面试官,考察Java基础时,通常都会问到序列化、反序列化的知识点,用以衡量其Java基础如何。当被问及Java序列化是什么?反序列化是什么?什么场景下会用到?如果不用它,会出现什么问题等,一般大家回答也就是几句简单的概念而已,有的工作好几年的应聘者甚至连概念都说不清楚,一脸闷逼。
本文就序列化和反序列化展开深入的探讨,当被别人问及时,不至于一脸闷逼、尴尬,或许会为你以后的求职面试中增加一点点筹码。
一、基本概念
1、什么是序列化和反序列化
序列化是指将Java对象转换为字节序列的过程,而反序列化则是将字节序列转换为Java对象的过程。
Java对象序列化是将实现了Serializable接口的对象转换成一个字节序列,能够通过网络传输、文件存储等方式传输 ,传输过程中却不必担心数据在不同机器、不同环境下发生改变,也不必关心字节的顺序或其他任何细节,并能够在以后将这个字节序列完全恢复为原来的对象(恢复这一过程称之为反序列化)。
对象的序列化是非常有趣的,因为利用它可以实现轻量级持久性,“持久性”意味着一个对象的生存周期不单单取决于程序是否正在运行,它可以生存于程序的调用之间。通过将一个序列化对象写入磁盘,然后在重新调用程序时恢复该对象,从而达到实现对象的持久性的效果。
本质上讲,序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态。
2、为什么需要使用序列化和反序列化
我们知道,不同进程/程序间进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等,而这些数据都会以二进制序列的形式在网络上传送。
那么当两个Java进程进行通信时,能否实现进程间的对象传送呢?当然是可以的!如何做到呢?这就需要使用Java序列化与反序列化了。发送方需要把这个Java对象转换为字节序列,然后在网络上传输,接收方则需要将字节序列中恢复出Java对象。
我们清楚了为什么需要使用Java序列化和反序列化后,我们很自然地会想到Java序列化有哪些好处:
实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(如:存储在文件里),实现永久保存对象。
利用序列化实现远程通信,即:能够在网络上传输对象。
二、如何实现Java序列化和反序列化
只要对象实现了Serializable、Externalizable接口(该接口仅仅是一个标记接口,并不包含任何方法),则该对象就实现了序列化。
- 1
1、具体是如何实现的呢?
序列化,首先要创建某些OutputStream对象,然后将其封装在一个ObjectOutputStream对象内,这时调用writeObject()方法,即可将对象序列化,并将其发送给OutputStream(对象序列化是基于字节的,因此使用的InputStream和OutputStream继承的类)。

反序列化,即反向进行序列化的过程,需要将一个InputStream封装在ObjectInputStream对象内,然后调用readObject()方法,获得一个对象引用(它是指向一个向上转型的Object),然后进行类型强制转换来得到该对象。
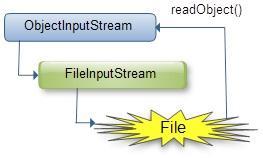
假定一个User类,它的对象需要序列化,可以有如下三种方法:
(1)若User类仅仅实现了Serializable接口,则可以按照以下方式进行序列化和反序列化。
ObjectOutputStream采用默认的序列化方式,对User对象的非transient的实例变量进行序列化。
ObjcetInputStream采用默认的反序列化方式,对对User对象的非transient的实例变量进行反序列化。
(2)若User类仅仅实现了Serializable接口,并且还定义了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out),则采用以下方式进行序列化与反序列化。
ObjectOutputStream调用User对象的writeObject(ObjectOutputStream out)的方法进行序列化。
ObjectInputStream会调用User对象的readObject(ObjectInputStream in)的方法进行反序列化。
(3)若User类实现了Externalnalizable接口,且User类必须实现readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法,则按照以下方式进行序列化与反序列化。
ObjectOutputStream调用User对象的writeExternal(ObjectOutput out))的方法进行序列化。
ObjectInputStream会调用User对象的readExternal(ObjectInput in)的方法进行反序列化。
java.io.ObjectOutputStream:对象输出流,它的writeObject(Object obj)方法可以对指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream:对象输入流,它的readObject()方法可以将从输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
2、序列化和反序列化示例
为了更好的理解序列化和反序列化的过程,举例如下:
public class SerialDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 序列化对象User
FileOutputStream fos = new FileOutputStream("object.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user1 = new User("xcbeyond", "123456789");
oos.writeObject(user1);
oos.flush();
oos.close();
// 反序列化
FileInputStream fis = new FileInputStream("object.txt");
ObjectInputStream ois = new ObjectInputStream(fis);
User user2 = (User) ois.readObject();
System.out.println(user2.getUsername()+ "," + user2.getPassword());
}
}
// 对象User,对其实现了Serializable接口
public class User implements Serializable {
private String username;
private String password;
……
}
3、什么场景下需要序列化
当你想把的内存中的对象状态保存到一个文件中或者数据库中时候。
当你想用套接字在网络上传送对象的时候。
当你想通过RMI传输对象的时候。
三、注意事项
1、当一个父类实现序列化,子类就会自动实现序列化,不需要显式实现Serializable接口。
2、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化。
3、并非所有的对象都可以进行序列化,比如:
安全方面的原因,比如一个对象拥有private,public等成员变量,对于一个要传输的对象,比如写到文件,或者进行RMI传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的;
资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现。
4、声明为static和transient类型的成员变量不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
5、序列化运行时会使用一个称为 serialVersionUID 的版本号,并与每个可序列化的类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。可序列化类可以通过声明名为 “serialVersionUID” 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID。
如果序列化的类未显式的声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 -- serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
- 1
6、Java有很多基础类已经实现了serializable接口,比如String,Vector等。但是也有一些没有实现serializable接口的。
7、如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存!这是能用序列化解决深拷贝的重要原因。
有了上面关于序列化和反序列化的详细介绍,现在你对平时所用的序列化和反序列化是如何实现的,什么场景下会使用它,是不是更加深刻了吧
- 1
参考:
(美) Bruce Eckel 著 陈昊鹏 译 《Java编程思想》
https://blog.csdn.net/xlgen157387/article/details/79840134
https://blog.csdn.net/Mr_EvanChen/article/details/79724426 分类导航
分类导航