

 个人中心
个人中心 退出
退出




性能测试项目实战:应用加载慢该怎么办?
背景
app收到留学push、课堂、资讯,用户点击push消息,进入app,应用加载很慢,容易出现应用假死、app崩溃或提示网络异常等信息。
给用户体验十分不友好,监控阿里云资源tcp连接数飙高,cpu打满,自愈能力(系统恢复能力)低。
分析
push频率过高(这本身没有问题),从而导致收到push的用户过多,如果按10000的push到达,20%的用户同时点击,那么将造成大于等于200的用户并发量。
从服务器看资源:cpu、内存、磁盘I/O一切显示正常,但是业务处理存在漏洞,即离线app收到推送,打开push时,接口请求过多,一度达到30+接口,又或者可能出现服务器出现短暂网络波动,即带宽过大(大于设定值5Mbit/s),服务器自动恢复,影响范围约2min甚至更久,同时监控阿里云tcp连接数在短暂时间里达到4-6k的连接数,超出平均水平一大截<需要压测得出一个极限值>。
小知识:理论1个tcp连接数对应1个http请求,1个push进入app,触发了3个或多个http请求,但是http2.0是支持并行请求tcp连接,那么1个用户请求的多个http请求创建的也是1个tcp连接,http1.1默认带connection参数,保持持久连接。
但是该版本不能并行请求,出现的是多对多的关系,然后nginx可以配置http的协议版本?
结果
大致可以判断出,前面用户批量请求服务器,创建tcp连接过多,用户持续继续访问,那么tcp连接不能及时释放<处理更多htttp请求>,那么造成服务器tcp连接数过高,app没有接收到后端响应故而服务器响应出现请求超时。
这时候需要性能测试,得出系统、应用程序瓶颈进行调优。
准备性能测试环境
包括用户(业务)数据、接口信息、开发测试脚本等。
设计性能测试用例
前提是了解业务流程,建立业务模型,即有可能出现性能问题的点,那么在开发脚本时也会对此进行单接口、组合场景的设计。
如背景现象描述,用户收到push,从此进入app应用请求其他资源,那么需要获取这几个请求的接口,作为一个整体事务请求,业务分析、iOS离线推送将每个tab首页都加载了,请求接口过多,需要拆分添加子事务进行监控。
即推送app、发起push、点击push整体作为一个事务请求,其中首页、上课、考试、留学等根据需求拆分子事务。
场景设计
假设没有缓存,先关闭redis服务,进行压测,逐步加压,例如1、10、20、50、100、200、300、500进行5分钟持续并发压测,收集性能结果。
现象还原
通过不断加压并发,得出服务器所承受最大并发数,系统出现瓶颈,根据监控的结果分析,开始优化:加缓存、代码优化、sql建立索引,再重复压测,以出现现象的并发数进行压测,结果是否较调优前有优化(标准:tps、响应时间、app现象等)。
性能指标计算公式:tps=通过事务总数/运行脚本总时长。
首页代入一个性能概念:Vuser、TPS、RT,随着用户数递增请求,响应时间随之递增、通过事务数也会增加。
a、随着用户数增加,持续并发一段时间,RT、TPS也会随之平稳逐步增加,即上下波动略小,正常现象,但是需要分析rt、tps是否达到预期;
b、随着用户数增加,持续并发一段时间,RT猝然上涨、服务器可能出现cpu被打满,应用程序无法响应;
c、随着用户数增加,通过事务数递增,响应时间递增<终究达不到预期>,tps上不去,表示服务器处理能力低,需要分析原因。
收集性能测试结果
进行结果分析
1、tps上不去的原因:由简入繁排第一位的首先检查网络带宽--连接池<服务器>--垃圾回收机制--数据库配置<如果需要写库>--通讯机制--硬件资源--负载机资源不足--脚本设计问题<需要从场景设计方向入手>--系统架构--并发数设置问题;解决的第一个问题就是检查宽带只有3M,流量无法进来<请求服务>,被挡在外面。
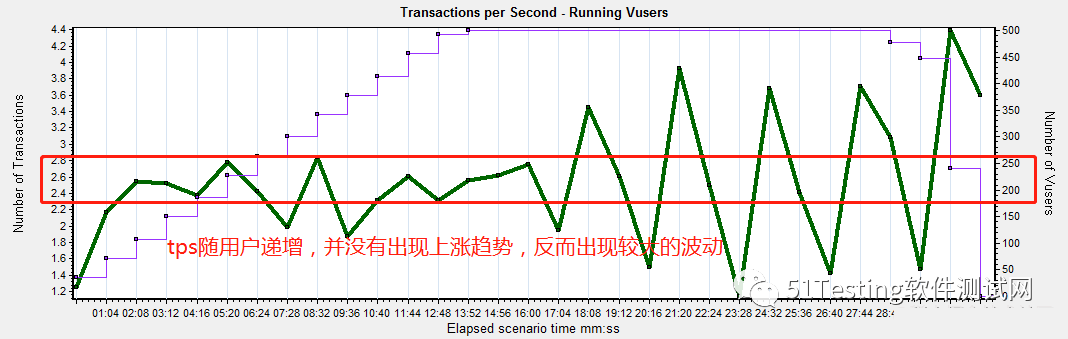
2、正常现象是可以看到tps随着用户的递增而递增。

3、响应时间也是随着并发用户数递增而递增。

4、在脚本运行之前初始化Vuser虚拟用户,随着并发用户的递增,响应时间也随之递增,在期望响应时间对应的纵坐标用户数,即为最优并发用户数<不要看响应时间上的纵坐标标识的用户数>。
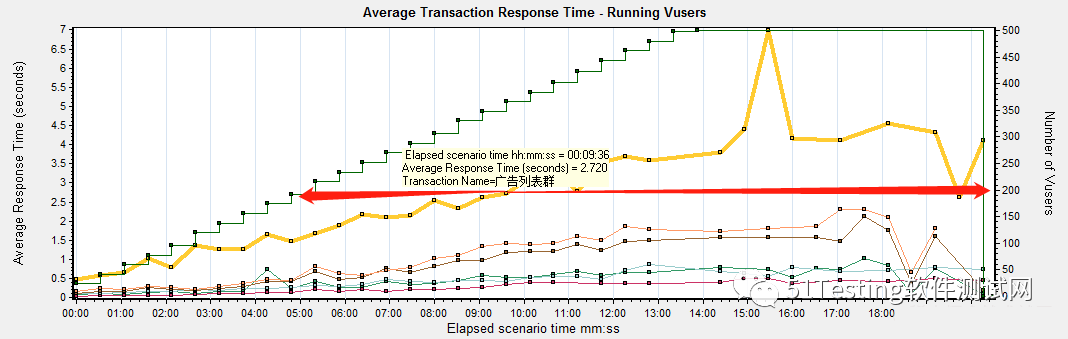
5、单机目前负载生成的用户,无论何种压测策略,都无法将服务器压垮或者app出现无法正常响应事件,需要分布式压测。
6、在uat环境压测,当并发用户数上去之后,服务器资源cpu暴涨,出现服务假死状态,jvm排查线程,发现是底层框架导致。
作者:我先测了
欢迎关注微信公众号 :Python测试社区
 分类导航
分类导航