

 个人中心
个人中心 退出
退出




我的数据带入神经网络或者支持向量机里面,为什么效果很差呢?为什么别人论文里的就效果很好呢?
大家常常把机器学习算法(如神经网络、支持向量机等)应用到自己的学科领域内,用来拟合一些关系式不确定但是有千丝万缕联系的特征量。有的同学辛辛苦苦搜集了很久的数据,带入了神经网络中发现构建的模型效果并不好,不管怎么调节参数效果都很差,泛化性都难以名状。很多同学第一反应就是肯定是程序写错了,或者就是数据没有预处理,但是查了很久之后,发现并没有什么问题。那么效果这么差,问题到底出在哪里呢?为什么参考的别人的论文里的效果都那么好呢?小猪老师来为大家一一解答:
1、搜集的数据有错误或者说测量误差较大
测量误差大家都很好理解,也许是仪器的精度导致的,也许是测量的方法导致的(可能夹杂噪声),大家可以追根溯源去发现问题的所在;
数据错误大概有两种情形:
数据中有异常值,和其他数据差异过大。如图中的红点与其他的点差异过大,那么可能是记录错误或者是测量错误
b.两组同样的的输入,对应的输出却不同。在给定的训练好的模型的前提下,输入确定了后,输出是唯一的。因此出现不同的输出值一定会使得训练后的模型精度下降
2、选取的特征与输出之间没有关系
这个很好理解,举个例子,比如我们现在要区分足球和篮球两个事物,我们该从哪些角度去识别才能实现精准区分呢?这里的角度实际上就是我们选取的特征。
如果从形状这个特征来说,足球是圆的,篮球也是圆的,光看形状仿佛无法区分这是一个足球还是篮球..........
如果从颜色来说,篮球一般是棕褐色,足球大部分为黑白的或者彩色的(不排除也有棕褐色),从这个角度可以很大程度的去区分两个球
如果从重量来说,篮球一般都较重,足球一般都较轻,这也可以很好的区分。
可见,选择合适的特征是相当重要的,所以很无脑的把一堆实验数据丢进去训练也是得不偿失的。在训练模型之前,可以先用其他方法计算一下特征和输出之间的关联性(如灰色关联度、层次分析、熵权法等)
3、模型出现了过拟合,泛化性太差
过拟合的直接表现就是模型训练好之后,重新带入训练数据的输入,得出的拟合输出的精度非常的高;一旦带入没有训练过的测试数据,可以发现输出的结果与真实结果相差的非常大。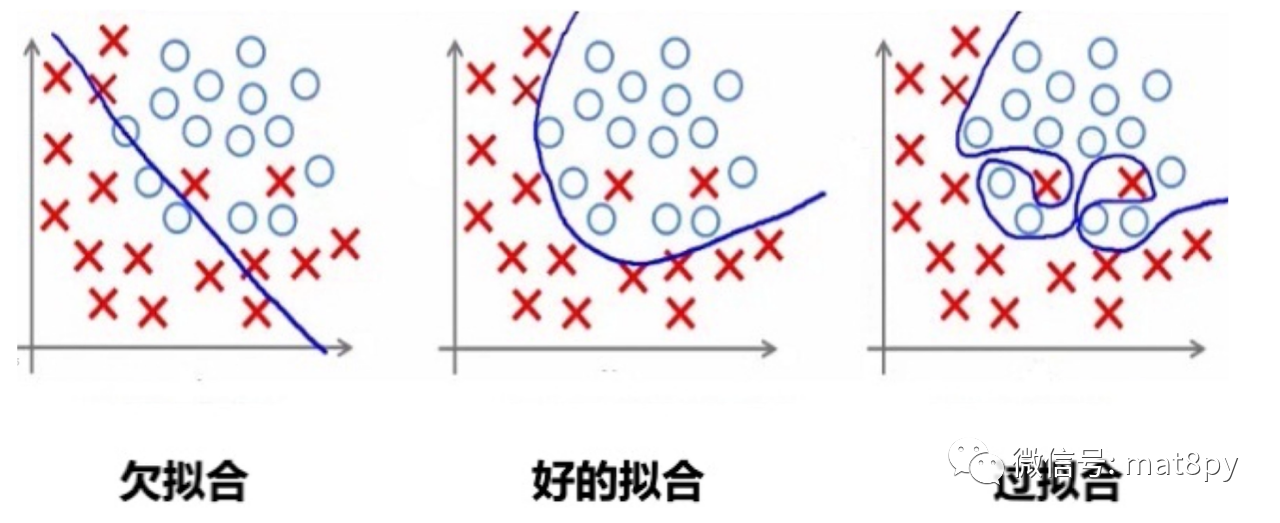
导致这种现象的情况一般也有两个原因:
训练集、测试集没有合理的选择划分:训练集的选择要尽大可能的包含数据的数据类型和范围,避免出现测试集中的数据和训练集中的数据有很大差异的情形,如果不知道怎么选择的话可以用交叉验证法选择。
过拟合是神经网络、支持向量机等模型的固有缺点,这个缺点没法去根除,只能通过改进算法来改善这一情况。
4、选择的数据量太少或者选择的算法模型不适合此数据
神经网络往往需要很多的数据,支持向量机相对来说需求量较小,这是由每个算法的自身的特点导致的。
算法模型有很多,包括各种神经网络、决策树、贝叶斯、随机森林等,大家可以多选择几个模型来训练,选一个效果最好的出来使用。
5、为什么差不多的数据,别人论文的里的效果特别好,我的就很差呢?
当然回答这个问题,大家首先要查看一下是否有前面1-4点中描述的问题,如果有的话要及时改成。这里假设排除前面4点问题以及程序的错误的问题,如果效果还是很差,那么大概有两种可能:
模型中训练的数据有造假(或者编造)的嫌疑,因为在论文中由于样本数据往往很多,因此不会把全部数据放进文章里(也可能只放一部分),所以我们无法去验证其数据的真伪。
由于论文的发表具有功利性,如果预测的效果不好,那么论文是发表不了的,所以大家为了论文能顺利的通过,可能会直接在文章中伪造效果图或者直接编一些数据直接画图(这里指最终的结果数据不是模型算出来的,而是人为直接输入进去绘图)。所以大家在看论文的时候,要保持参考的心态,要对这种造假行为习以为常,不要过分相信已发表的文章。
 分类导航
分类导航