

 个人中心
个人中心 退出
退出




机器学习算法中数据集的输入输出、训练测试集是什么关系?
首先,数据集中包含多个样本,每个样本都有同样的输入输出
输入就是判断的依据,可以理解为特征,特征可以是多个,根据不同的情形自行选择,输出就是根据特征判断的结果,也是我们构建机器学习模型的目的(为了预测或者分类某些指标),这个结果也可以有多个
训练集:多个样本的集合,用来构建收敛机器学习模型,一般选择数据集中的大多数样本
测试集:多个样本的集合,不能和训练集中的样本重合,用来对构建好的机器学习模型进行泛化性测试,一般选择数据集中的少数样本,并且这些样本要和训练集中的样本在数值类型上、数值范围上、以及特征的相互关系上类似,否则效果可能会比较差!
试想,如果这个机器都没有学习过类似的同类型的数据,你拿一个新的陌生数据给他,他会认识么?
预测集:多个样本的集合(这些样本没有输出),使用他们的目的就是通过已经测试好的、泛化性良好的机器学习模型根据输入来预测输出,该数据集只有输入特征。
训练集、测试集、预测集的关系可以打一个很形象的比喻:
今天,老师给我们讲了一道数学题,我们都听懂了,这个数学题相当于训练集
晚上,老师给我们布置了作业,也是一道数学题,和白天讲的那道类似,看看我们学习的如何(老师有答案、对作业进行了批改),这个作业就相当于测试集
第二天,老师组织了一场考试,这个考试没有答案,只有题目,这个题目就相当于预测集。
为了让大家更好的从数据结果上理解上述概念的关系,可以查看下图: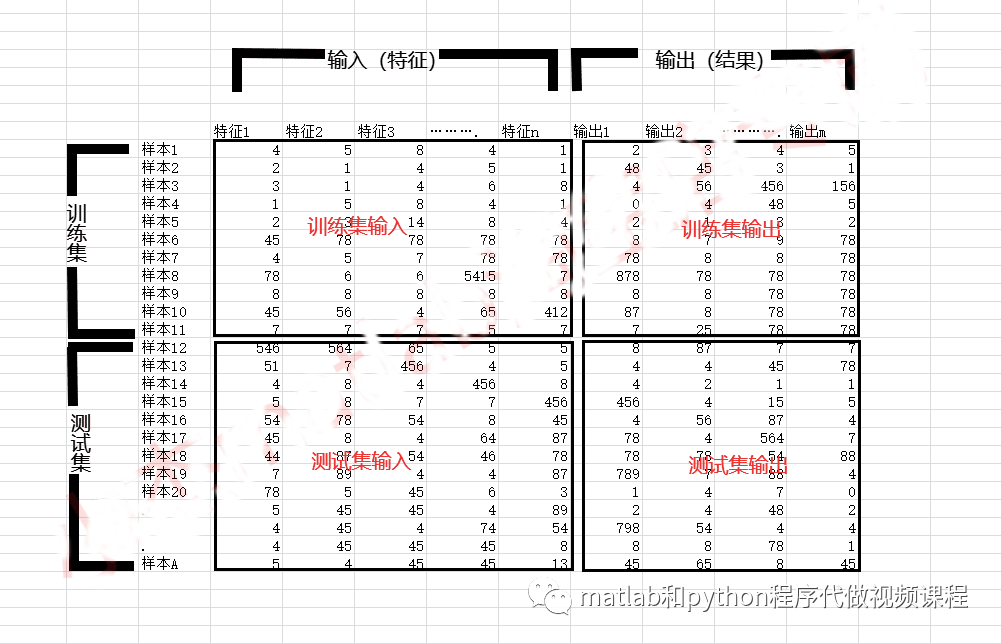
请前往:http://www.mark-to-win.com/TeacherV2.html?id=269
 分类导航
分类导航