

 个人中心
个人中心 退出
退出




分类(有监督学习)和聚类(无监督学习)有什么区别呢?
首先分类算法是一种有监督的学习算法,比如:bp神经网络、支持向量机svm、决策树等等,这样的算法有很多,那么什么是有监督学习算法呢?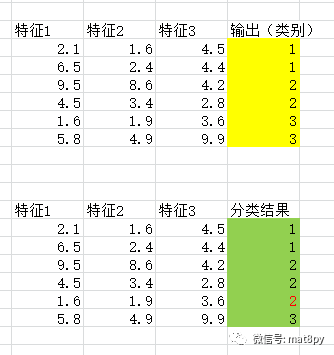
上图中的第一组数据是一个训练样本集,可以看到该样本集有3个特征(输出),一个输出(类别),每一个样本都对应一个类别标签。1、2、3三个标签对应3种不同的类别,这个对应关系是在算法学习之前就对应好了的,也就是说这个标签是已经告知我们了。这种在学习前已经告知样本标签的数据学习就是有监督学习,这里的监督就是指告知结果、告知类别的含义。第二组数据则是根据第一组数据学习训练后,利用机器学习算法带入特征分类得到的结果。
再来看看聚类,它是一种无监督的学习算法,最经典的就是Kmeans聚类算法。和上面的有监督对应的,无监督就是算法在学习前用到的数据是没有标签、没有告知类别的。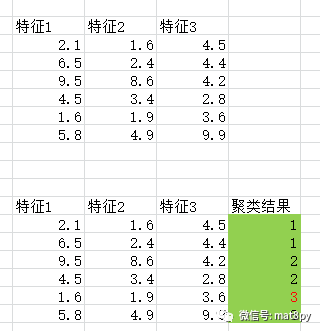
上图第一组数据即为学习数据,这里只有特征,没有标签没有类别。下面的第二组数据则为聚类算法聚类得到的结果。
注意:
聚类结果里的1、2、3与分类结果里的1、2、3含义是大不相同的。
聚类结果里的数字只表示一种类别,但是这个类别表示什么含义,光从聚类结果来看是不清楚的,需要通过其他专业知识根据数据去判别,聚类里的数字主要是用来区分是否是同一类,不同的数字表示不同的类别,同样的数字表示的是同样的类别。
分类结果里的数字的含义与分类用的训练数据里的标签含义一致,比如在训练数据里1表示高、2表示中、3表示矮,那么在分类结果里分为1也表示高,3也表示矮,这里数字的含义是一一对应的。
这是分类算法和聚类算法的最大的区别.................
请前往:http://www.mark-to-win.com/TeacherV2.html?id=269
 分类导航
分类导航