

 个人中心
个人中心 退出
退出




MyBatis 学习笔记(六)---源码分析篇---映射文件的解析过程(一)
概述
前面几篇我们介绍了MyBatis中配置文件的解析过程。今天我们接着来看看MyBatis的另外一个核心知识点—映射文件的解析。本文将重点介绍<cache>节点和<cache-ref>的解析。
前置说明
Mapper 映射文件的解析是从XMLConfigBuilder类的对mappers 节点解析开始。mappers节点的配置有很多形式,如下图所示:
<!-- 映射器 10.1使用类路径-->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
<!-- 10.2使用绝对url路径-->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
<!-- 10.3使用java类名-->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
<!-- 10.4自动扫描包下所有映射器 -->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
mappers的解析入口方法
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
//10.4自动扫描包下所有映射器
String mapperPackage = child.getStringAttribute("name");
// 从指定的包中查找mapper接口,并根据mapper接口解析映射配置
configuration.addMappers(mapperPackage);
} else {
// 获取resource/url/class等属性
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
//resource 不为空,且其他两者为空,则从指定路径中加载配置
if (resource != null && url == null && mapperClass == null) {
//10.1使用类路径
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
//映射器比较复杂,调用XMLMapperBuilder
//注意在for循环里每个mapper都重新new一个XMLMapperBuilder,来解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
//10.2使用绝对url路径
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
//映射器比较复杂,调用XMLMapperBuilder
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
//10.3使用java类名
Class<?> mapperInterface = Resources.classForName(mapperClass);
//直接把这个映射加入配置
configuration.addMapper(mapperInterface);
} else {
// 以上条件都不满足,则抛出异常
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
上述解析方法的主要流程如下流程图所示:
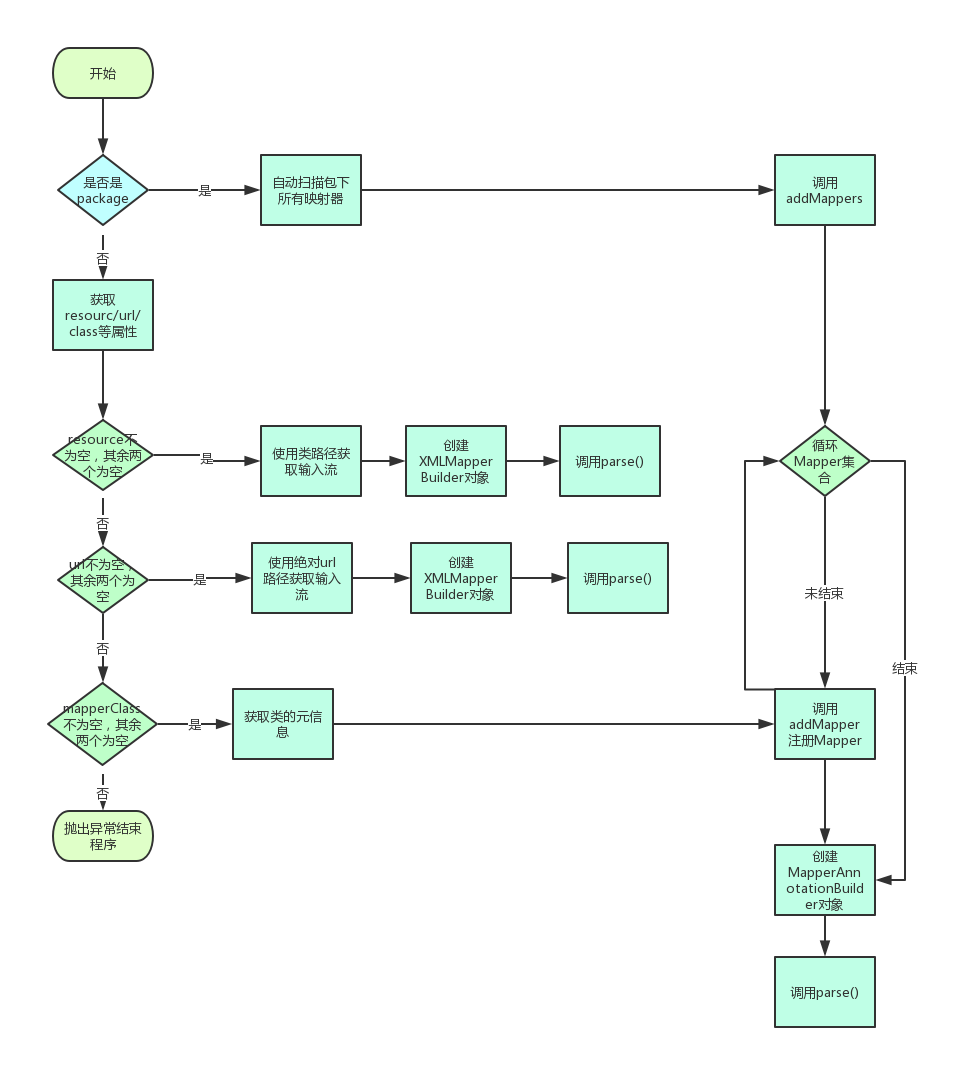
如上流程图,mappers节点的解析还是比较复杂的,这里我挑几个部分说下。其中
configuration.addMappers(mapperPackage)还是利用ResolverUtil找出包下所有的类,然后循环调用MapperRegistry类的addMapper方法。待会我们在分析这个方法- 配置resource或者url的都需要先创建一个XMLMapperBuilder对象。然后调用XMLMapperBuilder的parse方法。
首先我们来分析第一部分。
注册Mapper
//* MapperRegistry 添加映射的方法
public <T> void addMapper(Class<T> type) {
//mapper必须是接口!才会添加
if (type.isInterface()) {
if (hasMapper(type)) {
//如果重复添加了,报错
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 将映射器的class对象,以及其代理类设置到集合中,采用的是JDK代理
knownMappers.put(type, new MapperProxyFactory<T>(type));
//在运行解析器之前添加类型是很重要的,否则,可能会自动尝试绑定映射器解析器。如果类型已经知道,则不会尝试。
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
//如果加载过程中出现异常需要再将这个mapper从mybatis中删除,
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
//* MapperProxyFactory
protected T newInstance(MapperProxy<T> mapperProxy) {
//用JDK自带的动态代理生成映射器
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
如上,addMapper方法主要有如下流程:
- 判断mapper是否是接口,是否已经添加,如果不满足条件则直接抛出异常
- 将mapper接口的class对象及其代理类添加到集合汇总
- 创建
MapperAnnotationBuilder对象,主要是添加一些元数据,如Select.class - 调用MapperAnnotationBuilder类的parse方法进行最终的解析
其中第4步骤相对而言比较复杂,待会我在分析。接着我们来分析第二部分
解析mapper
就像刚刚我们提到的解析mapper的parse方法有两个,一个是XMLMapperBuilder的parse方法,一个是MapperAnnotationBuilder的parse方法。接下来我分别分析下。
//* XMLMapperBuilder
public void parse() {
//如果没有加载过再加载,防止重复加载
if (!configuration.isResourceLoaded(resource)) {
//配置mapper
configurationElement(parser.evalNode("/mapper"));
//添加资源路径到"已解析资源集合"中
configuration.addLoadedResource(resource);
//绑定映射器到namespace
bindMapperForNamespace();
}
//处理未完成解析的节点
parsePendingResultMaps();
parsePendingChacheRefs();
parsePendingStatements();
}
如上,解析的流程主要有以下四个:
- 配置mapper
- 添加资源路径到"已解析资源集合"中
- 绑定映射器到namespace
- 处理未完成解析的节点。
其中第一步配置mapper中又包含了cache,resultMap等节点的解析,是我们重点分析的部分。第二,第三步比较简单,在此就不分析了。第四步一会做简要分析。
接下来我们在看看MapperAnnotationBuilder的parse方法,该类主要是以注解的方式构建mapper。有的比较少。
public void parse() {
String resource = type.toString();
//如果没有加载过再加载,防止重复加载
if (!configuration.isResourceLoaded(resource)) {
//加载映射文件,内部逻辑有创建XMLMapperBuilder对象,并调用parse方法。
loadXmlResource();
//添加资源路径到"已解析资源集合"中
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
//解析cache
parseCache();
//解析cacheRef
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
//解析sql,ResultMap
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
如上,MapperAnnotationBuilder的parse方法与XMLMapperBuilder的parse方法逻辑上略有不同,主要体现在对节点的解析上。接下来我们再来看看cache的配置以及节点的解析。
配置cache
如下,一个简单的cache配置,说明,默认情况下,MyBatis只启用了本地的会话缓存,它仅仅针对一个绘画中的数据进行缓存,要启动全局的二级缓存只需要在你的sql映射文件中添加一行:
<cache/>
或者设置手动设置一些值,如下:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
如上配置的意思是:
- 按先进先出的策略淘汰缓存项
- 缓存的容量为512个对象引用
- 缓存每隔60秒刷新一次
- 缓存返回的对象是写安全的,即在外部修改对象不会影响到缓存内部存储对象
这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
cache 节点的解析
cache节点的解析入口是XMLMapperBuilder类的configurationElement方法。我们直接来看看具体解析cache的方法。
//* XMLMapperBuilder
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
//读入额外的配置信息,易于第三方的缓存扩展,例:
// <cache type="com.domain.something.MyCustomCache">
// <property name="cacheFile" value="/tmp/my-custom-cache.tmp"/>
// </cache>
Properties props = context.getChildrenAsProperties();
//调用builderAssistant.useNewCache
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
如上,前面主要是一些设置,没啥好说的, 我们主要看看调用builderAssistant.useNewCache 设置缓存信息的方法。MapperBuilderAssistant是一个映射构建器助手。
设置缓存信息useNewCache
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
//这里面又判断了一下是否为null就用默认值,有点和XMLMapperBuilder.cacheElement逻辑重复了
typeClass = valueOrDefault(typeClass, PerpetualCache.class);
evictionClass = valueOrDefault(evictionClass, LruCache.class);
//调用CacheBuilder构建cache,id=currentNamespace(使用建造者模式构建缓存实例)
Cache cache = new CacheBuilder(currentNamespace)
.implementation(typeClass)
.addDecorator(evictionClass)
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
//添加缓存到Configuration对象中
configuration.addCache(cache);
//设置currentCache遍历,即当前使用的缓存
currentCache = cache;
return cache;
}
如上,useNewCache 方法的主要有如下逻辑:
- 调用CacheBuilder构建cache,id=currentNamespace(使用建造者模式构建缓存实例)
- 添加缓存到Configuration对象中
- 设置currentCache遍历,即当前使用的缓存
这里,我们主要介绍下第一步通过CacheBuilder构建cache的过程,该过程运用了建造者模式。
构建cache
public Cache build() {
// 1. 设置默认的缓存类型(PerpetualCache)和缓存装饰器(LruCache)
setDefaultImplementations();
//通过反射创建缓存
Cache cache = newBaseCacheInstance(implementation, id);
//设额外属性,初始化Cache对象
setCacheProperties(cache);
// 2. 仅对内置缓存PerpetualCache应用装饰器
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
//装饰者模式一个个包装cache
cache = newCacheDecoratorInstance(decorator, cache);
//又要来一遍设额外属性
setCacheProperties(cache);
}
//3. 应用标准的装饰者,比如LoggingCache,SynchronizedCache
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
//4.如果是custom缓存,且不是日志,要加日志
cache = new LoggingCache(cache);
}
return cache;
}
如上,该构建缓存的方法主要流程有:
- 设置默认的缓存类型(PerpetualCache)和缓存装饰器(LruCache)
- 通过反射创建缓存
- 设置额外属性,初始化Cache对象
- 装饰者模式一个个包装cache,仅针对内置缓存PerpetualCache应用装饰器
- 应用标准的装饰者,比如LoggingCache,SynchronizedCache
- 如果是custom缓存,且不是日志,要加日志
这里,我将重点介绍第三步和第五步。其余步骤相对比较简单,再次不做过多的分析。
设置额外属性
private void setCacheProperties(Cache cache) {
if (properties != null) {
// 为缓存实例生成一个"元信息"实例,forObject方法调用层次比较深,
// 但最终调用了MetaClass的forClass方法
MetaObject metaCache = SystemMetaObject.forObject(cache);
//用反射设置额外的property属性
for (Map.Entry<Object, Object> entry : properties.entrySet()) {
String name = (String) entry.getKey();
String value = (String) entry.getValue();
//检测cache是否有该属性对应的setter方法
if (metaCache.hasSetter(name)) {
// 获取setter方法的参数类型
Class<?> type = metaCache.getSetterType(name);
//根据参数类型对属性值进行转换,并将转换后的值
// 通过setter方法设置到Cache实例中。
if (String.class == type) {
metaCache.setValue(name, value);
} else if (int.class == type
|| Integer.class == type) {
/*
* 此处及以下分支包含两个步骤:
* 1. 类型装换 ->Integer.valueOf(value)
* 2. 将转换后的值设置到缓存实例中->
* metaCache.setValue(name,value)
*/
metaCache.setValue(name, Integer.valueOf(value));
//省略其余设值代码
} else {
throw new CacheException("Unsupported property type for cache: '" + name + "' of type " + type);
}
}
}
}
}
如上是设置额外属性的方法,方法的注释比较详实,再次不在赘述。下面我们来看看第五步。
应用标准装饰者
private Cache setStandardDecorators(Cache cache) {
try {
// 创建"元信息"对象
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
//刷新缓存间隔,怎么刷新呢,用ScheduledCache来刷,还是装饰者模式,漂亮!
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
//如果readOnly=false,可读写的缓存 会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
cache = new SerializedCache(cache);
}
//日志缓存
cache = new LoggingCache(cache);
//同步缓存, 3.2.6以后这个类已经没用了,考虑到Hazelcast, EhCache已经有锁机制了,所以这个锁就画蛇添足了。
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
总结
本文 按照代码运行的脉络,先是介绍了mappers节点的解析,然后概括了映射文件的解析,最后重点介绍了cache 节点的解析。
源码地址
作者:码农飞哥
微信公众号:码农飞哥
 分类导航
分类导航