

 个人中心
个人中心 退出
退出




指标体系:指标的设计方法!附pdf
01 为什么要设计指标?
因为我们知道的太少。
不仅是Jon Snow,“我们真的知道的,比我们认为自己知道的,知道的少。”是一个对于大多数人而言都普遍存在的现象。

牵强附会加张 图
而设计指标的目的就在于:让我们了解更多。
具体而言,通过指标数值,可以在可接受的成本下,传递足够多的信息。
设想一下:
中年危机老贾去医院体检,咨询身体状况如何;医生说:“还行。有点问题。问题不大。”而不是告诉他血压如何、体脂如何、血糖如何。
法外狂徒小艺被查酒驾,交警质问他喝了多少;小艺说:“没醉。喝了一点。喝的不多。”交警却没有一个血液酒精含量的指标,去判断他是否醉驾,应该作何处罚。
霸道总裁阿饼例行月会询问业绩,负责销售的副总说:“很棒。业绩很好,卖了不少。”只字不提销售总额、人均产能、业绩趋势。
“唉~”
倘若没有指标这个工具,我们能获得的信息,就会变得是非常有限的;或是获取信息的成本变得极高。为了更好的使用这个工具,我们首先要了解“指标”的定义是什么。
02 什么是指标?
让我们简单的回忆一下:我们日常最常接触到的指标,像身高、体重、温度、GDP。
它们的共性是什么?
——共性在于它们的载体都是数值。例如,身高180,体重154,温度26,GDP14.7万亿。
它们的差别是什么?
——差别在于它们的含义各不相同。比方说,身高180(cm)和体重180(斤)的含义是截然不同的。
所以,指标是一个被定义的数值,用来对事实进行量化抽象。这个抽象过程可以是一次的,也可以是多次:
当一个事实比较简单的时候,例如某个物品的轻重,我们用通过质量这一个指标就可以衡量清楚。
但当一个事实更复杂一些的时候,例如一个人的胖瘦,也许仅仅是用质量(体重)就不足以说明这个事实。这个时候我们可能会用BMI、体脂率等经过了两次抽象的指标。
当这个事实变得更加复杂,例如一个国家的经济状况,我们会用GDP,这个一个进行了很多层复杂抽象、涉及到大量数据[1]的指标。甚至是仅仅一个指标也完全不足以描述出这个事实的重要特征;这时候就要设计一整套的指标体系,来量化这个复杂的事实。
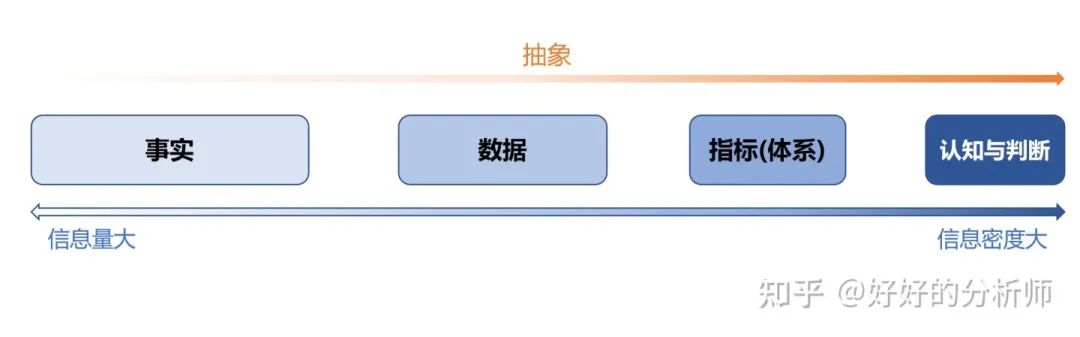
事实、数据、指标之间的关系
综上所述,一个应该至少包含4个要素:
名称:指标名称要清晰明确,避免歧义,降低沟通成本。
责任人:责任人要保证指标可维护、可运营。
含义:指标含义要描述的是“被量化的事实”;例如——这个指标是在什么场景下?为了什么目的?刻画了什么事实?
口径:指标口径要保证我们能及时地、准确地取到所需的“数值”;例如——这个指标是如何计算的?所需的数据从哪获取?获取的时效如何?
当然仅仅知道什么是指标是远远不够的,还要知道怎么去生成一个指标。
03 如何设计一个指标?
1、指标设计的过程与分类
结合统计与数据治理视角,我们可以将指标的设计过程分为三个步骤:抽象、加工、限定。
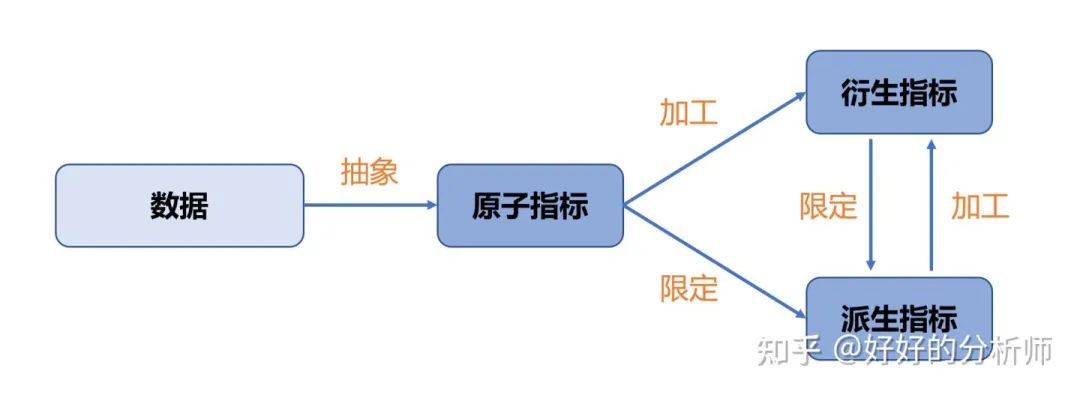
指标的生成过程
数据经过初步抽象,形成原子指标,即绝对数指标。例如:保费、客户数、用户量。
原子指标经过三种加工方式,形成衍生指标。例如:升学率、平均客单价、沪深300。这3种加工方式分别为:进行对比、计算统计量、指数设计(结合对比和统计计算)。
当我们对原子指标和衍生指标,进行维度限定的时候,就形成了派生指标。

指标类型
这里对原子指标、相对指标以及统计量指标的使用做一个简单的介绍:
原子指标记录事实:根据指标的定义,指标是一个被定义的数值,用来对事实进行量化抽象。这个量化过程的起点是传感器、数字化等;然后是日志、记录、标签等;进入指标汇总层面的第一步就是原子指标。我们通过原子指标来记录事实,例如访问的次数、出行的距离、消费的金额等等。所以当我们需要记录一些基本事实的时候,我们设计一个原子指标来量化它们。
相对指标用于评价:我们通过原子指标,记录下了一堆的事实。紧接着,我们要做的就是对这些事实进行评价。常说“没有比较就没有伤害。”为什么没有伤害呢?因为没有比较,就很难做评价,进而我们也不知道自己是好是坏。所以当我们需要评价一些事实的时候,我们设计一个相对指标来量化它们。
当我们要评价一件事对整体的影响的时候,我们可以用比例相对数;例如:市场占有率。
当我们要评价同一个事物在不同维度下的差异程度的时候,我们可以用比较相对数;例如:TGI、男女比例。
当我们要评价两个不同事物之间的关联的时候,我们可以用强度相对数;例如:投诉发起强度、退款发起强度。
当我们要评价计划的完成情况的时候,我们可以用完成相对数,例如:销售额完成进度。
统计数指标提炼信息:有时候,我们会有非常多的记录或指标。它们蕴含着非常多的信息,但是价值的密度却很有限。这个时候就可用通过一些统计的方式,提炼其中的信息价值。例如我们有数以千万记的用户的月均消费金额,这时候可以通过统计分位置的方式对我们客户整体的消费能力做一个刻画。
2、指标的尺度特性
不同的指标,还会具有不同的尺度特性。根据可比程度的不同,我们可以将指标划分为4个测量尺度:定比尺度、定距离尺度、定序尺度和名义尺度。
名义尺度 定序尺度 定距尺度 定比尺度
类别区别 √ √ √ √
次序区别 √ √ √
距离区别 √ √
比例区别 √
指标尺度的特性是我们必须要了解清楚的,因为低尺度的指标不能使用高尺度的数据运算进行处理。这里举2个反例说明以下,如果没有弄清楚指标的尺度特性会导致什么问题:
定距尺度不能直接做乘除:
例如温度就是一个典型定距尺度,“20度有10度的2倍那么热,是一个非常令人困惑的表述。”
定比尺度具有绝对起点“0点”;而定距尺度没有绝对起点,定距尺度的“0点”是人工计算出来的。换言之,定比尺度的指标,本身和零点的差是有意义的。但,定距尺度,之间的差才是有意义的。这就导致了,定比尺度可以直接和自然数做乘除法,但定距尺度不可以。
定序尺度不能直接做加减:
满意度评分就是一个典型的定序尺度。如果消费者给A酒店的评分是5分,B酒店的评分是3分,C酒店的评分是1分。很可能这并不意味着,A比B酒店好的程度与B酒店比A酒店好的程度相等。实际情况可能是 ,大多数的酒店都在4分左右,而5分是非常棒的;1、2、3分的酒店都乏善可陈,甚至体验很差。
因为定距尺度之间的距离是精确定义了的,而定序尺度没有。所以定序尺度只能比较大小,而不能够进行直接的加减。
虽然很多场景下,我们都会用平均满意度来衡量客户的满意情况。但我们会发现这样的使用方法,存在一些问题,例如说没有区分度等。这些问题中,有一部分就是由于“定序尺度”的特性带来的。
3、指标的时间特征
在指标设计的过程中,时间是一个非常重要的因素。由于多个事实的发生时间之间的异步性,以及事实发生时间与指标计算时间之间的异步性,导致不同的时间统计口径会对指标产生重大的影响。
多个事实发生时间之间的异步性:
一个件事通常在一件事发生后一段时间,才会发生,或者才会被观测到。例如订单退款必须在下单支付之后才能发生;退房必须在入住酒店之后才能发生,且存在着一定的时间差。
事实发生与指标计算之间的异步性:
一个事实发生与这个事实被计算(为指标)之间通常存在着时间差。
例如,一个消费者1分钟内在APP上(生产环境下)下了20笔订单。但可能在1个小时后,才能在后台数据库中查询到这20笔增量的订单记录。这种情况的发生可能是由于任务调度的设置导致的,也可能是由于技术能力的限制导致的。
再举个例子,应该几个月前,知乎在创作中心中统计的阅读量还是日频刷新的。现在也仅仅做到了小时刷新。
这样的刷新频次可能在“创作中心”的业务场景下是可接受的,但在很多其他的业务场景下(例如短视频推荐),是不可接受的。为了解决以上业务场景的问题,我们就需要采取流计算的技术,来提高数据生产的时效性。
事实间的“异步性”和事实与计算间的“异步性”,会影响指标反馈信息的“及时性”与对事实抽象的“准确性”。
总的来说,我们希望指标在保证一定准确性的前提下,越及时越好。为了达成这个目标,我们需要慎重的考虑两个时间特征:“T+n”和“时间切片 v.s. 关联绑定”

“T+n”与“时间切片统计”、“关联绑定统计”的示意说明
"T+n":
T+n中的n应该设置为什么更为合适,是1天、3天还是5天;1小时、2小时还是5分钟。
举个例子,保险公司要衡量保单的品质,即有没有卖给消费者他们所需要的产品。那么用什么指标来衡量更为合适呢?
大家可能会想到“退保率”。但是退保率该如何计算呢?严格来说,一笔保单在其合同约定的期限内的任意一天都是可以退保的。所以,从完全准确的角度出发,如果某个保险产品的合同期为20年,那么应该统计20年零1天前所有保单的退款率,即T+20y。
但是,这显然是不现实的。因为“及时性”太差了,完全不可运营。
因此,我们要设计一个更恰当的时间特征n。假设,现在我们知道保险的犹豫期大约是10~15天,也许在平衡“及时性”与“准确性”之后,退款率的设计就会是“T+15d”计算。
“时间切片 v.s. 关联绑定”:
我们在计算相对指标的时候,应该以什么样的方式进行对比?举个例子,运营常用的流程分析,AAARR(获取、激活、留存、收益、传播)。
通常使用这套方法去做运营分析,就要计算激活率、留存率、消费转化率等等一系列的指标。如果我们要计算这类指标就存在一个选择,是使用时间切片的方式去计算激活率吗?即:今日的激活率 = 今天获取的用户量 / 今天激活的用户量。
但是思考一下:今天激活的用户中,有没有昨天获取的用户呢?有没有前天获取的用户呢?有没有去年获取的用户呢?显然是有的。
而我们在使用切片数据时,就可能导致一个现象,今天的激活率高,可能仅仅是因为今天获取的用户数少,而今天激活的用户都是之前积累下来的。也就是说,有可能转化率高,是件坏事。
那么,是不是为了准确性,就用关联绑定的方式去设计指标呢?即,计算激活率的时候,应该圈定某天获取的那些用户,看这些用户中有多少激活了。
例如,今天计算“T+7d ”前获取的用户中的激活率是多少。如果采取这样的方式,我们就回到了问题1:“n”应该如何选择。
综上所述,当我们遇到一个量化的问题,就从上述的指标类型中选取一种设计方法,完成指标的设计工作。接下来我们要做的,就是去衡量这个设计的好坏。
04 什么样的指标算一个好的指标?
我们可以从4个维度去评价一个指标的优劣:
1. 有效性:这个指标能不反映我们量化的事实?
例如,我们想要去衡量某个APP的用户量有多少,应该用DAU,还是MAU?不同类型的APP可能有不同的选择,对于外卖而言,每天的DAU可能都非常关键。而对于一个旅行类的APP而言,因为类目本身消费频次的不同,可能MAU才是一个更能真实反映用户数量的指标。
2. 可信性:反映事实的指标是不是稳定的?
例如,人力部门设计了一套题库去衡量应聘者的数据能力,希望通过测试题的分数,去做出是否招聘某位同学的决定。那么对于同一个面试的同学而言,第一次参加数据能力测试,和第二次参加数据能力测试的分数应该是相近的。
3. 敏感性:事实的变化,能否被指标敏感的捕捉到,并反映出来?
例如,对于酒店住宿预订而言,到酒店前台却没有空房可以入住,是一种非常糟糕的用户体验。但也是一个非常低频发生的情况。那么是否应该用“到店无房发生率”来追踪这个问题就是一个值得思考的问题。同理,对于舆情监控,是应该用绝对数指标来监控,还是比例指标来监控更好呢?
4. 可运营:这个指标能否被用于日常的运营,及时的帮助我们谋求改善?
例如,越来越多的公司因为对客户忠诚度的重视,开始用NPS(客户净推荐值)来衡量客户的感受。但是如果仅仅有这个主观指标,当NPS降低了10%的时候,公司应该如何去提升用户的忠诚度呢?
最后:小结一下
使用指标的原因:指标可以帮助我们低成本的获取更多信息。
指标的定义:指标是一个被定义的数值,用来对事实进行量化抽象。
指标设计的4个要素:名称、责任人、含义、口径。
指标设计的3个过程:通过抽象、加工、限定,我们可以将数据转化为原子指标、衍生指标和派生指标。衍生指标是原子指标经过运算的结果,派生指标是原子指标和衍生指标经过维度限定的结果。
衡量指标设计好坏的4个标准:有效性、可信性、敏感性、是否可运营。
作者:薛秋艳
欢迎关注微信公众号 :大数据球球
 分类导航
分类导航