

 个人中心
个人中心 退出
退出




大数据架构平台搭建指南及数据仓库演进
一、大数据架构平台搭建指南
虽然大数据平台组件很多,但是对于没有参与建设过大数据平台的朋友来说,当前众多的大数据组件和平台架构容易让人眼花缭乱。
本文首先介绍了大数据架构平台的组件架构,便于了解大数据平台的全貌,然后分别介绍数据集成、存储与计算、分布式调度、查询分析等方面的观点。
01. 大数据平台架构
从图上可以看出,大数据架构平台分为:数据集成、存储与计算、分布式调度、查询分析等核心模块。我们就沿着这个架构图,来剖析大数据平台的核心技术。
02.数据集成
1. 日志同步
开源日志收集系统有 Sqoop、Flume、Logstash、Filebeat、Vector 等,其中 Flume 在云原生场景用的多,Vector 是一个很高效的日志同步工具,刚开源不久。
专家观点:
日志同步系统虽然本身比较成熟,但在平时工作中也属于重点,一是因为需要同步的数据量比较大,二是要保证日志输出的持续性,有缓存机制最大限度保障不丢日志,始终保持平稳的运行状态。
2. 数据抽取工具
大数据分析不能直接在原始的业务数据库上直接操作,所以需要抽取想要的数据到分析数据库或者分布式存储系统(例如 HDFS),常见数据抽取工具包括:DataX、BitSail 等。DataxundefinedDataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。BitSail 项目是头条刚开源的,基于 Flink 开发,在自己内部业务应用广泛。BitSail 支持多种异构数据源间的数据同步,并提供离线、实时、全量、增量场景下的全域数据集成解决方案。
专家观点:
数据集成非常重要,因为跟业务方相关的第一个环节就是数据集成,数据集成如果出现问题比如速度慢、丢数据等,都会影响到业务方数据的使用,也会影响业务方对大数据平台的信任度。
3. 数据传输队列
数据传输有三种:
Kafka:流式传输
RabbitMQ:队列传输
Pulsar:流式传输+队列传输
专家观点:
Kafka是Hadoop组件全家桶,名气更大,但是易用性还是差一点。
Pulsar 跟Kafka很像,不过架构比Kafka更先进,属于后起之秀。
03. 数据处理:数据存储、计算
1. 数据存储:HDFS
HDFS 特点:横向扩展,数据容错性高。
专家观点:
对于 HDFS 来说,优化是一个很重要的事情,因为 HDFS 的集群规模比较大,又要稳定,又要持续不断的应对业务挑战,优化这一块还是很重要的。如果集群负载大时,访问延迟,会影响集群整体使用效率。
HDFS 的优化趋势包括:架构改进、读写分离、读写优化等。
虽然 HDFS 是分布式文件系统,但在实际场景中,由于 NameNode 的单点和小文件过多导致的压力过大问题,其管理的数据节点是有限的。分布式文件系统的新趋势类似 JuiceFS 的架构,采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计,利用元数据缓存极大提升整体文件系统的性能,同时兼容大数据和云原生场景的应用。
2. 数据计算
(1)离线计算引擎
在众多的计算引擎中,MapReduce、Hive、Spark 等通常用于离线处理,即批计算。Storm、Spark Steaming 等处理实时计算的场景较多,即流计算。不得不说的是,Flink 既可以用于流计算,也可以用于批计算。
其中 Hive 的用途很广,也很可靠,底层基于 MapReduce 的封装,属于 Hadoop 全家桶组件之一,缺点是只能实现离线批处理。
Spark 是非常高效的批处理工具,成熟,稳定,比 Hive 快很多,并且还能实现近实时的数据处理能力。Spark 功能全,架构新,基于 RDD,计算过程中优先利用内存,并优化中间的计算步骤。
专家观点:
● Spark+数据湖是未来的发展方向。
● 离线的场景很丰富,但是缺乏处理的非常好的统一的计算引擎,hive和spark都无法做到,所以这一块未来还有很大的发挥空间。
(2)实时计算引擎优缺点及适用场景
实时计算引擎大体经过了三代,依次是:storm、spark streaming、Flink。其中storm和spark streaming现在用的很少,大部分公司都在用Flink。
专家观点:
● Flink的优点是:可以实时的进行计算,在处理流计算这个方向上是最好的组件,而且几乎可以替代近实时的业务场景。
● 缺点是对离线处理会略显不足,不太适合处理大批量的离线数据集。
● Flink的优化方向很多:a. Flink在流处理稳定性上,虽然已经做到极细粒度,但是遇到阻塞时,会存在丢失数据的问题。需要加强稳定性。b. 实时性的提升:实时的优化是无底洞,业务需求能到秒级别、毫秒级别,怎么能让Flink在业务场景用的好,提升速度的同时,保持数据一致性,是Flink面临的挑战。
04. 数据调度
1. 常用任务调度系统
提到常用的任务调度系统,大家都会想到非常多,包括但不限于:Crontab、Apache Airflow、Oozie、Azkaban、Kettle、XXL-JOB、Apache DolphinScheduler、SeaTunnel 等,五花八门。
专家观点:
● Apache DolphinScheduler(海豚调度)更专注于大数据场景,调度功能不复杂,但是足够把任务管理起来。并且它是中文的,这一点对于中文用户较友好。
● Apache Airflow 国外用的多。
2. 资源调度系统
资源调度系统主要包括 Yarn 和 Azkaban。Yarn 用的广泛,上层很多组件都要支持,所以很受欢迎,对其优化很多。
Azkaban 是资源调度的小众分支,用的人不多。
05. 大数据查询
1. 大数据查询引擎
常用的OLAP引擎对比:
专家观点: 专家之一曾经用 Presto 和 StarRocks 做过对比 Impala 的性能测试,结论如下:
● 结果上看 StarRocks 的性能确实很强大,速度最快,但三者对比提升相同量级的性能需要更多的 CPU、内存资源等;
● Impala 在开启各项优化之后,效果是可以接近 StarRocks 的;
● Presto 性能一般,而且发现跑部分 TPC-DS 测试时,调用 HMS API 的频率偶尔很高,曾经把 HMS 搞挂过。但是 Presto 的易用性感觉最好,差不多就是开箱即用,配置很简单。支持多源数据(多Catalog)的接入,但是随着数据湖对底层数仓存储层的统一加上各个。其他高效分析引擎对数据湖的支持,这块的优势也会被逐步抹平。
专家对查询引擎优化的观点:
查询引擎优化在大数据平台架构只算一环,不算难点,但确实很重要。整个大数据生态的上下游优化应该是逐步协同进行的,查询引擎上游的数据是需要下功夫治理的,不然 Impala 遇到比如小文件问题是很拖累性能的;查询引擎下游需要一个合适的平台作为数据的展示窗口,比如 BI 工具,或用协议比较通用的客户端,像支持 MySQL 协议的 SR 和 Doris 这些,如果下游没法做比较好的数据展示,查询引擎再牛也没法让大家用起来。
2. 大数据查询优化工具
大数据查询优化工具包括 Alluxio、JuiceFS 和 JindoFS。
专家观点:
Alluxio:
数据编排最为强大,市面上常见的存储系统、云存储服务均可以直接接入,也可以自行实现相关 api 以接入其他自研存储系统,可以说 Alluxio 最为通用,既可用于云存储服务的缓存接入或数据编排,也可作为传统 HDFS 的多集群数据编排。
JuiceFS:
● 提供了和 Alluxio 非常相似的功能,如元数据与数据分离的存储、数据编排、与 Hadoop API 兼容、Fuse 等特性;
● JuiceFS 也有不错的数据编排特性,元数据存储的方式比 Alluxio 更多元,主要用于云存储场景。
JindoFS:
● 局限于阿里云 oss 场景的分布式存储系统;
● 支持与 Alluxio 非常相似的功能,也能提供内存级的缓存加速;
● 但场景局限于 oss 内。
二、数据仓库演进
01. 标准化
1. 数据治理
数据仓库的标准化主要指的是数据治理。数据治理是数仓落地应用的核心问题,在近年受到越来越多的关注,其根本上是为了解决数据仓库烟囱式开发带来的资源浪费等问题。
例如上图所示,企业发展初期,因为业务模式不稳定,多个业务线都有独立研发的技术栈,到后期就会出现标准不统一、重复计算、模型依赖关系混乱的问题。
而经过标准统一、底层逻辑屏蔽和不同粒度的汇总,各个业务线的技术栈得以统一,就能大大简化模型计算链路、降低成本、提高速度。
也可以从数据建模的角度来理解这个问题。数据建模是数仓建设的核心环节之一,包括自上而下(范式建模,Inmon模式)和自下而上(维度建模,Kimball模式)两种建模方式。
范式建模主要在电信、金融、政务、工业等传统行业用的比较多,而互联网由于业务变化很快,初期需要更加灵活的分布式决策结构,因此维度建模会更加合适,但也因此基于Kimball模式建模的后期会出现数据孤岛问题和治理需求。不过,专家表示,维度建模在前期若有指导思想或方法论的话,或许能提前避免这个问题。
在业界,数仓治理最核心的工作是改善数据质量,数据的完整性、一致性等指标都会影响最终的数据决策的好坏,这对于整个行业都是一个挑战。因为数据质量仅仅通过简单的唯一性校验、波动性校验等手段是很难排查出业务波动的根本原因的。
而除了人为制定规则以外,如今也有不少企业正在尝试引入AI算法对质量监控进行预测,目前技术上尚未成熟,但AI的潜力值得期待。
DataOPs是近期比较热的概念,很大程度上也是围绕数据质量的工作,但其本质和数据治理相差不远,关注数据生产的标准化、流程化、自动化、智能化,也就是将越来越多大数据技术环节中的人工工作自动化,也会开始结合AI技术,涉及开发和运维过程。
上图展示了一个数仓开发的工作流程,包括模型检索、模型创建、ETL开发、作业发布、监控报警等全流程的标准化、自动化都是DataOPs关心的问题。
提到标准化和数据治理,又不得不提到数据中台。目前业界对于数据中台都有不同的解释,有专家对DataFun表示,数据仓库和数据中台其实是相对的概念。
实际上,中小企业通常只限于搭建数据仓库,很多中小企业声称的数据中台其实也是局限于某个业务的数据仓库,不是真正的数据中台。
真正的数据中台主要在大企业,其中每个部门都拥有一个数仓体系,那么每个部门相当于一个小型公司。而在业务发展中后期会出现数据一致性、数据标准等方面的困难,因而就产生数据治理和建设中台的需求。这也意味着,数据治理通常只在大企业中有足够的需求。
2. 流批一体
数据治理在标准化方面的一大特点是将并行的业务线进行合并。实际上,这种合并统一的趋势不仅存在于业务逻辑和数据层面,其根本上还存在于存储、计算、处理等底层逻辑中。存储、计算、处理的两种基本的开发模式是离线计算和实时计算,因此数仓标准化的另一个方向是流批一体。
流批一体除了解决多条技术栈之间的标准不统一之外,还有一大好处就在于成本层面。在发展到一定阶段的时候,离线数仓通常已经无法满足业务需求了。而实时数仓对于下游的成本比较高,普惠性不足。
根据一些分析结果,批计算的成本和数据体量大致呈线性关系,而流计算的成本却随着数据体量的增长而呈指数级增长,背后原因包括随机IO、存算不分离、写放大等。因而实时计算一般不直接面向业务,更多面向算法或数据工具。
另外,流批一体能够实现状态复用,很多时候这是有必要的,因为离线计算在取数的时候,经常会遇到数据有效期不足的问题,而复用实时计算的结果就能很好地解决这个问题。
总体而言,流批一体架构的好处是解决流批不统一带来的数据不一致、开发成本、使用成本、运维成本问题。
人们一般默认流批一体的解决方案是Kappa架构,采用Kafka和Flink也就是消息队列和实时计算引擎的组合。
但Kappa架构严重依赖消息队列的顺序处理,而在顺序存储上进行OLAP分析是比较困难的。
因此在业界,许多企业开始探索通过数据湖方案实现流批一体,比如Iceberg支持读写分离,又支持并发读、增量读、小文件合并,还可以支持秒级到分钟级的延迟,因此可以实现近实时数据接入。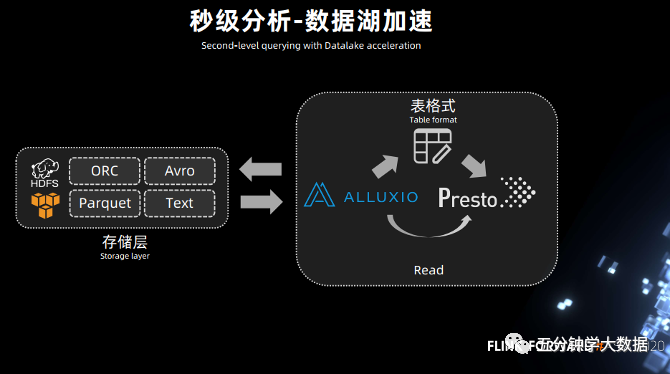
同时,Iceberg底层依赖列式存储,用于替换Kafka后就可以对OLAP分析进行基本的优化,在中间层直接用Flink执行批式计算或流式计算。最后,再结合Alluxio的缓存能力,就可以对近实时的数据湖架构进一步加速。
尽管如此,目前在业界,无论是流批一体还是数据湖,其技术发展都还存在很大挑战。据专家反馈,业界的方案基本都局限于部分场景,距离通用方案还很遥远。
流批一体的含义包含了多个层次,首先是存储流批一体,其次是计算流批一体,最后是处理结果的流批一体,也就是让同一段代码在分别做批处理和流处理时,得到的结果是一致的,而这通常也是最难的。
02. 实时处理
1. 实时查询
流批一体技术的需求自然来源于实时计算的发展。如今越来越多的服务面向ToC用户,实时性需求越来越强,这些业务包括了风控事件处理,搜广推的实时特征计算,以及指标监控等等,实时数仓的开发也愈发受到企业的重视和投入。
目前而言,业界最关心的数据仓库核心性能指标是查询的实时性。性能指标设置对于业务成长非常重要,背后的考虑因素有两个,一个是性能本身会导致数据产出的延迟,另一个是性能差一般也代表着资源消耗大。
提高数据处理实时性的解决方案类型主要有两种,包括:数据和业务逻辑优化(主要指数据治理)、底层计算引擎优化。
其中,底层计算引擎的优化也是大企业比较常用的方法,常用的选型包括Spark、Flink、Blink等。
但严格来说,对于大企业而言,一般不存在选型的概念。专家表示,因为大企业一般都有成熟的大数据平台,里面包括了采集、模型设计等模块,经过优化和协同,这些组件都已经封装成了一套完整的体系。
但对于中小企业来说,他们一般很难抉择如何做具体的选型,一般都是考虑模仿大企业的架构,或者直接购买大企业的平台产品。
2. 流式ETL
除了查询以外,数仓中另一个消耗资源较大的流程是ETL。在业界,数仓比较常用的ETL模式是增量ETL和全量ETL。
数仓ETL通常面临的核心挑战是高效实施,也就是如何用最低资源产出最多成果,另一个是数据质量。
除了增量ETL、全量ETL之外,还有一种ETL的模式是流式ETL,自然也是源于实时计算的业务需求,据专家介绍,目前在业界的成熟度还比较低。
03. 整体衡量
专家表示,对数据模型的优劣判断(比如数据的业务覆盖率、数据的业务使用率等),目前行业内还缺乏统一的、成熟的衡量指标。而数据模型是数仓的核心,其优劣判断关系到数仓整体能力的判断,重要性很高。
04. 总结
通过以上分析可知,除了标准化、模块化、实时处理、整体衡量等发展特点以外,数据仓库也还面临许多整体层面的挑战,包括解决方案通用性、整体衡量标准等。
目前业界正在投入数据编织、DataOPs等方向,使得数据仓库在标准化、模块化等方面走的更远,并实现更强的通用性,从而实至名归地演化成数据中台、数据湖等架构,适应数据智能业务不断增长的规模化、多样化、产品化需求。
作者: 大数据球球
欢迎关注微信公众号 :大数据球球
 分类导航
分类导航