

 个人中心
个人中心 退出
退出




GitHub开源:17M超轻量级中文OCR模型、支持NCNN推理
目录
1、项目简介
近期GitHub上一位大神开源了一个叫做chineseocr_lite的OCR的项目,这是一个超轻量级中文OCR,支持竖排文字识别、NCNN推理,识别模型型仅17M(Psenet (8.5M) + crnn (6.3M) + anglenet (1.5M))。

以下为可实现的功能:
- 提供轻量的 backone 检测模型 psenet(8.5M),crnn_lstm_lite (9.5M) 和行文本方向分类网络(1.5M);
- 任意方向文字检测,识别时判断行文本方向;
- crnn\crnn_lite lstm\dense识别(ocr-dense和ocr-lstm是搬运chineseocr 的);
- 支持竖排文本识别;
- ncnn实现psenet(未实现核扩展);
- ncnn实现crnn_dense(改变了全连接为conv1x1);
- ncnn实现shuuflenev2角度分类网络;
- ncnn实现ocr整个流程。
2、项目配置
该作者已经将所需的第三方库归纳到requirements.txt文件中,可以直接输入以下指令批量安装:
pip install -r requirements.txt安装成功效果如下所示:
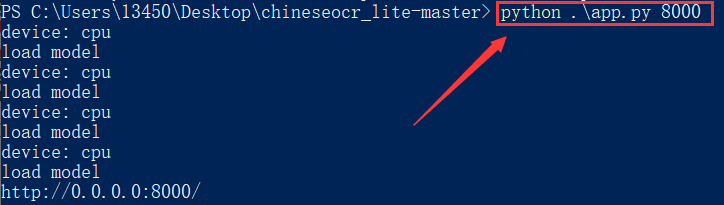
使用作者的图片上传验证,测试无误。

3、问题解决
最最最重要的问题来了,这个项目配置环境是真的艰难啊!Window系统下配置环境过程中可能会遇到的问题归纳如下所示:
问题1:Python模块问题:ImportError: cannot import name 'PILLOW_VERSION' from 'PIL'
解决方法:使用from PIL import Image, ImageOps, ImageEnhance, __version__ 替换文件中from PIL import Image, ImageOps, ImageEnhance,PILLOW_VERSION这句,就是用__version__ 替换原来的PILLOW_VERSION。
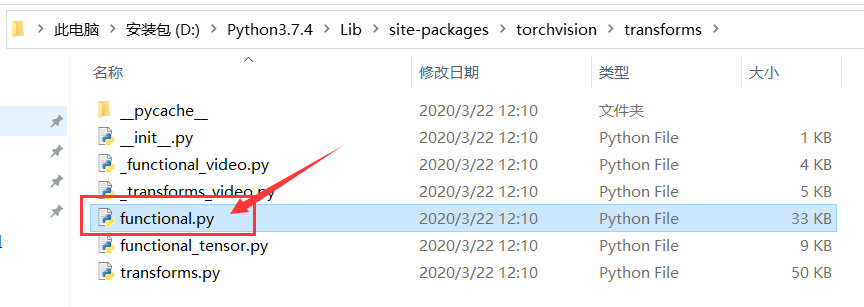

问题2:File "D:\Python3.7.4\lib\subprocess.py", line 1178, in _execute_child startupinfo) FileNotFoundError: [WinError 2] 系统找不到指定的文件。
解决方法:到该文件路径下将shell配置为True。
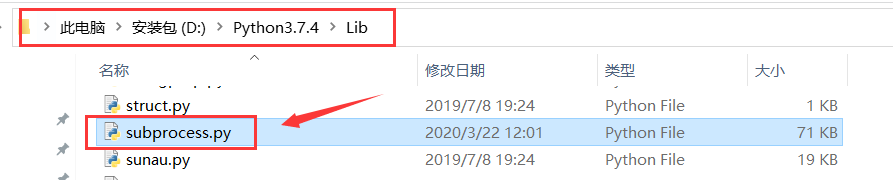

问题3:RuntimeError: Cannot compile pse: C:\Users\13450\Desktop\chineseocr_lite-master\psenet\pse
解决方法:到该文件路径下屏蔽以下两句Linux语句。


问题4:File "D:\Python3.7.4\lib\site-packages\torch\nn\modules\rnn.py", line 123, in flatten_parameters self.batch_first, bool(self.bidirectional)) RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
解决方法:进入PyTorch官网,选择合适自己的版本,这里我是用的是CPU编译。

问题5:UnicodeDecodeError: 'gbk' codec can't decode byte 0xab in position 551: illegal multibyte sequence
解决方法:添加编码, encoding='UTF-8'。
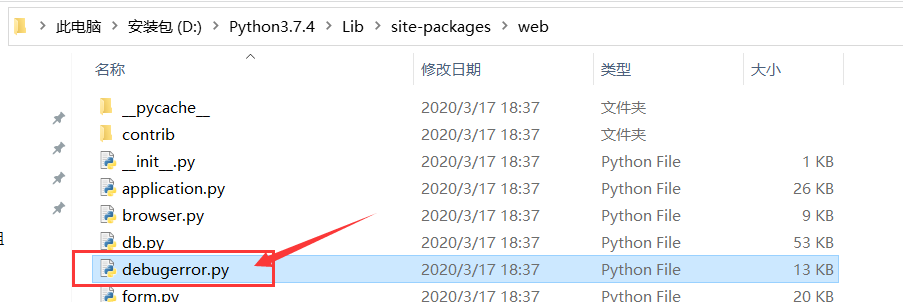

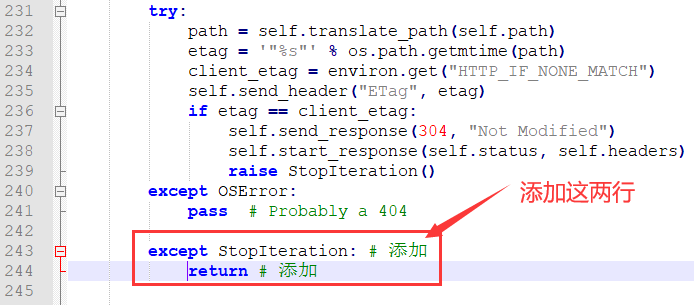
问题6:File "D:\Python3.7.4\lib\site-packages\cheroot\wsgi.py", line 145, in respond for chunk in filter(None, response): RuntimeError: generator raised StopIteration
解决方法:添加以下两行异常处理。
这里将自己配置好的项目分享给大家,可以关注我的微信公众号,回复关键字:中文OCR,获取项目。
关注公众号,发送关键字:Java车牌识别,获取项目源码。
 分类导航
分类导航