

 个人中心
个人中心 退出
退出




java进程的内存分析 OOM
java项目内存溢出(OOM)的排查方法及原因分析
线上的项目崩了,第一步就是重启服务图片,然后排查下项目日志,没发现异常,继续排查代码,也没找到问题所在,我们真的是太菜了图片,
重启后,几分钟有崩了,瑟瑟发抖图片。
然后开始进程信息排查
先top命令查看了下资源消耗情况,发现异常的java服务cpu使用率达200%,内存占用也极高,所以又通过jstat -gc xx命令查看了下java堆的状况
主要观察的是如下几个指标
YGC:新生代垃圾回收次数
YGCT:新生代垃圾回收消耗时间
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
young gc次数多很正常,gc线程耗时很短,且不会影响其他线程。
而full gc次数也很多且耗时较长就很奇怪了,因为老年代不太可能一下就有这么多内存占用
这才重启多久啊!!!
况且full gc的时候,会发生stop-the-world现象。即除了gc线程外,其他线程都会被暂停,正好和服务进程还在,但info日志不再输出的现象对应!!!
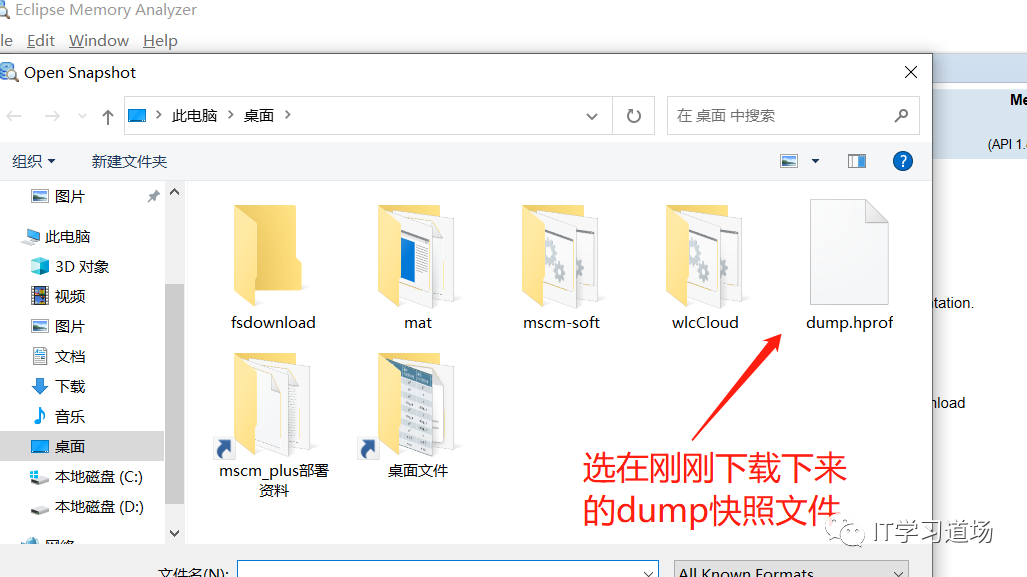
随即通过jmap -dump:format=b,file=dump.txt 进程号 命令,保存了当时的堆快照文件,然后准备进行分析,看看老年代究竟放了些什么对象。
命令:
jmap -dump:format=b,file=dump.hprof 1273315
然后就会保存 进程号 = 1273315 的程序的堆快照文件
然后把这个文件下载下来,用 MemoryAnalyzer 工具进行分析
如何使用MemoryAnalyzer内存分析工具
下载的地址连接在
链接:https://pan.baidu.com/s/1Pi48eZhdEC7rNCKs9QDO_w
提取码:y91z

界面如下


然后内存分析界面如下 
详细使用方法完毕
下面是上述提供的生产级别的排除分析图
点击红框处可查看调用方法栈
在当时的分析结果里,图1中堆占用率前三的点击“see stacktrace”都指向同一处业务代码:
调用了mybatis mapper去select,说明有三个线程运行到那处代码时都产生了大对象,直接耗尽了内存,持续引发full gc。
后面分析了那段代码逻辑,是根据用户的某个查询参数去关联表查出商编号,再去商户表里查出对应商户,再遍历组装下数据,再返回给前端。
但是写这段代码的同事,直接把关联表查出的商编号作为参数去商户表查,没有判空,而查商户表时对商编号有如下判断
所以导致如果关联表查出数据为空,这里不会根据customer_no去查,基本等同于全表查询,而商户表有300多万条数据,一次查询会返回一个300多万条数据的list!!!
事故原因复盘
当第一次触发bug时,jvm会把产生的大对象A1分配在新生代(如果此时新生代gc后内存足够的话)。
第二次触发时,新生代gc后内存可能不够放大对象A2了(比如第一次的请求还未结束,A1没有被回收),jvm会直接把A2放在老年代。
第三,第四次触发时,产生的大对象A3,A4也放在了老年代。
可能第五次触发时,老年代内存也不够了,就会触发full gc,一次full gc释放的内存不够,就会继续full gc。
而full gc时,之前还未处理完的请求线程被暂停,大对象还在被引用,无法回收,就会像类似死循环一样,一直full gc了
你学废了。。。。。。
作者:老王
欢迎关注微信公众号 : IT学习道场

 分类导航
分类导航