

 个人中心
个人中心 退出
退出




轻松入门自然语言处理系列 07 文本表示
一、文本表示基础
对于自然语言处理各类应用,最基础的任务是文本表示。因为一个文本是不能直接作为模型的输入的,所以必须要先把文本转换成向量的形式之后,再导入到模型中训练。所谓的文本表示,其实就是研究如何把文本表示成向量或者矩阵的形式。
1.单词的表示
任何机器学习模型的输入一定是向量或矩阵的形式,所以在进行文本分析时,就需要用向量化的方式来表示单词或句子。文本的最小单元为单词,其次为短语、句子或者段落,要懂得如何将它们表示成向量的形式。其中,单词的表示法是最基础的。另外,对于句子或者更长的文本来说,它们的表示依赖于单词的表示法。
基于词典使用向量表示单词,如下:

这种方式是独热编码(One-hot encoding),每个单词对应的向量大小与词库大小保持一致。同时,单词的表示法不止一种,包括独热编码的表示法、词向量的表示法等。
词库中所包含的单词的先后顺序不会对后续的任务产生不一样的结果,即词库中的单词顺序是无关紧要的,虽然它会影响单词编码的顺序,但由于都是跟词库里的单词1对1对应的,并不会对结果产生影响。
2.句子的表示
知道了如何表示一个单词之后,很自然地就可以得到如何表示一个句子了。类似于单词,句子也可以用向量表示,用1/0分别表示有或者没有这个单词。一个句子由多个单词来组成,那实际上记录一下哪些单词出现,哪些单词没有出现就可以了。当然,很多时候我们也需要记录一个单词所出现的次数,这就对应着句子的两种表示方式。
只记录句子中是否出现了单词,举例如下:

可以看到,最后一个句子中出现了2次“又去”,但是上述的文本表示只记录了一个单词出现与否,而没有包含单词出现的次数信息,同时也没有办法记录一个单词的重要性。这种方式称为Boolean Vector,只记录句子中单词是否出现,不记录出现的次数。
另一种方式考虑句子中单词出现的次数:

可以看到,现在每个位置记录着对应单词在句子中出现的次数,这称为Count Vector。
现在使用sklearn库的CountVectorizer,如下:
# -*- coding: utf-8 -*-
'''
@Author : Corley
@Time : 2022-03-08 12:36
@Project : NLPDevilCamp-setence_count_vector
'''
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'I like this course.',
'I like this game.',
'I like this course, but I also like that game',
]
# 构建count vectorizer object
vectorizer = CountVectorizer()
# 得到每个句子的count向量
X = vectorizer.fit_transform(corpus)
# 打印词典
print(vectorizer.get_feature_names_out(), end='\n\n')
# 打印每个句子的向量
print(X.toarray(), end='\n\n')
print(X)输出:
['also' 'but' 'course' 'game' 'like' 'that' 'this']
[[0 0 1 0 1 0 1]
[0 0 0 1 1 0 1]
[1 1 1 1 2 1 1]]
(0, 4) 1
(0, 6) 1
(0, 2) 1
(1, 4) 1
(1, 6) 1
(1, 3) 1
(2, 4) 2
(2, 6) 1
(2, 2) 1
(2, 3) 1
(2, 1) 1
(2, 0) 1
(2, 5) 1在打印矩阵时,之所以在最后一行使用了toarray()函数,这是由于稀疏性的特点:如果一个文本中没有出现词库里的单词,相应的位置为0,这就导致文本向量中包含的大量的0。实际上,为了节省内存空间没必要把所有的0都保存下来,所以sklearn在X的保存上默认会使用稀疏矩阵的保存方法,只保存对应的位置信息和相应的值,因此在保存矩阵时,只有非0的数才会占用内存空间。当使用toarray()函数的时候,就会打印成完整的矩阵形态。
3.tf-idf向量
先举例,使用Count Vector如下:

可以看到,Count Vector表示法是存在一定的问题的,因为一个句子中有的单词出现的次数很多、有的单词出现的次数很少,因此在Count Vector中数值越大,表明单词出现的次数越多,包含的信息量也就越大。但是从文本的角度考虑,出现次数最多的单词不一定的起的作用也大,例如he的重要性其实并不比denied的重要性更高。所以可以说,单词并不是出现的越多就越重要,也不是出现的越少就越不重要。直观地理解,一个单词出现的比较少,但是实际上可能是更重要的,对于文本分类等需要体现句子间差异性的任务是很有用的;而一个单词出现的次数很多,可能这个单词基本在每个句子中都会出现,说明这个单词对句子间的差异性的影响很小,这样对文本分类等需要体现句子之间差异性的任务起不了太大作用。
所以,如果只记录单词的个数也是不够的,我们还需要考虑单词的权重,也可以认为是质量。这有点类似于,一个人有很多朋友不代表这个人有多厉害,还需要社交的质量,其实是同一个道理。要把这种所谓的“质量”引入到表示中,就需要用到单词的一种重要表示法tf-idf,如下:
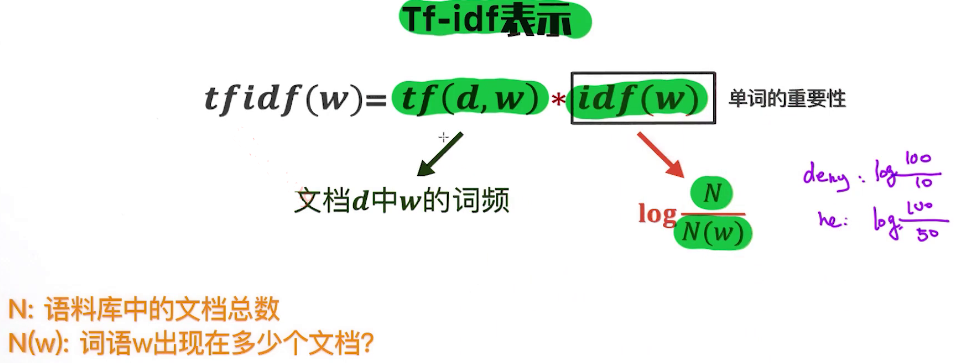
其中,tf相当于前面的Count Vector,而idf是逆文本频率,是单词的重要性指标,两者结合起来可以更好地表示一个词。因此tf-idf一方面衡量了一个词出现的频率,另一方面也衡量了这个词出现的权重。
tf-idf举例如下:

tf-idf的应用非常广泛,即便放在当前,也是表示文本的最核心的技术之一,同时也是文本表示领域的最有效的基准。很多时候,基于深度学习的文本表示也未必要优于tf-idf的表示。
二、文本相似度
语义理解是一个NLP任务的最终目标之一:一种方式针对一个句子分析到底表达的是什么意思;另一种方式是相对的,已经知道一个句子的语义,同时还有一些其他的不知道语义的句子,来分析这些句子的语义,此时就可以进行相似度的比较,将每个句子与已知语义的句子进行比较,相似度较近的句子,语义可能与已知的语义也较相近。因此,基于相似度的计算来理解语义,也是一种非常重要的方式。比如对于当前主流的问答系统,用户通过文本输入提出一个问题之后,去匹配与问题文本相似的一些其他问题,然后返回最匹配的其他问题的答案。所以表示两个文本之间的相似度极为重要。
因为文本可以用向量来表示,因此计算两个文本之间的相似度,实际上可以认为是计算两个向量之间的相似度,也就是通过向量的相似度来表示句子的相似度。同时相似度计算公式适合任何向量化的场景,不仅仅局限于文本之间的相似度。有两种常见的相似度计算方法,分别为基于欧式距离的计算,另外一种方式为基于余弦相似度的计算。
1.欧氏距离
文本相似度的一种计算方式是计算两个文本向量之间的欧式距离,距离越大相似度越小、距离越小相似度越大:

但是需要注意,向量之间的相似度需要考虑到向量的方向,因为向量最重要的特性就是它的方向性。如果两个向量相似,那也需要它们的方向也比较相似。然而,计算欧式距离的过程并没有把方向考虑进去,这是欧式距离最大的问题。
2.余弦相似度
为了弥补欧氏距离计算两个向量的相似度时没有考虑到方向的问题,需要提出另外一种相似度计算方法,即余弦相似度,其在计算相似度时也考虑到了方向的相似性,这也是计算两个向量之间的方向性最常用的方式。如下:

可以看到,在计算余弦相似度时,一方面衡量了两个向量的大小,具体是将向量的大小进行归一化;另一方面衡量了两个向量之间的夹角:两个向量之间的夹角越小,则两个向量的方向上越一致,这两个向量的相似度就越高;反之夹角越大,则方向越相离,相似度越低。两者结合,得到的余弦相似度就可以更好地表征两个向量之间的相似度。计算公式中的分子是两个向量的内积,也可以表示两个向量之间的相似度,分母就是对向量长度进行归一化,消除两个向量大小所带来的影响。同时,计算得到的余弦相似度越大,则两个文本之间的相似度越大,是同方向的。
现在实现给定两个向量,计算两个向量之间的余弦相似度:
# -*- coding: utf-8 -*-
'''
@Author : Corley
@Time : 2022-03-08 15:03
@Project : NLPDevilCamp-cosine_similarity
'''
import numpy as np
def cos_sim(a, b):
"""
给定两个向量,a和b,计算它俩之间的余弦相似度
"""
dot_product = np.dot(a, b)
norm_a = np.linalg.norm(a)
norm_b = np.linalg.norm(b)
return dot_product / (norm_a * norm_b)
if __name__ == '__main__':
sentence_m = np.array([1, 1, 1, 1, 0, 0, 0, 0, 0])
sentence_h = np.array([0, 0, 1, 1, 1, 1, 0, 0, 0])
sentence_w = np.array([0, 0, 0, 1, 0, 0, 1, 1, 1])
print(cos_sim(sentence_m, sentence_h))
print(cos_sim(sentence_m, sentence_w))输出:
0.5
0.25三、词向量基础
1.单词之间的相似度
独热编码的特点:
- 每个单词表示成长度为|V|的向量,|V|是词库的大小
-
除了一个位置1,剩下的全是0,极度稀疏
-
无法比较语义相似度
除了需要得到两个句子间的相似度,单词作为文本的最基本的要素,如何表示单词的含义以及两个单词之间的相似度也极其重要。计算两个单词之间的相似度有助于更好地理解文本,也可以尝试使用欧氏距离和余弦相似度进行计算:
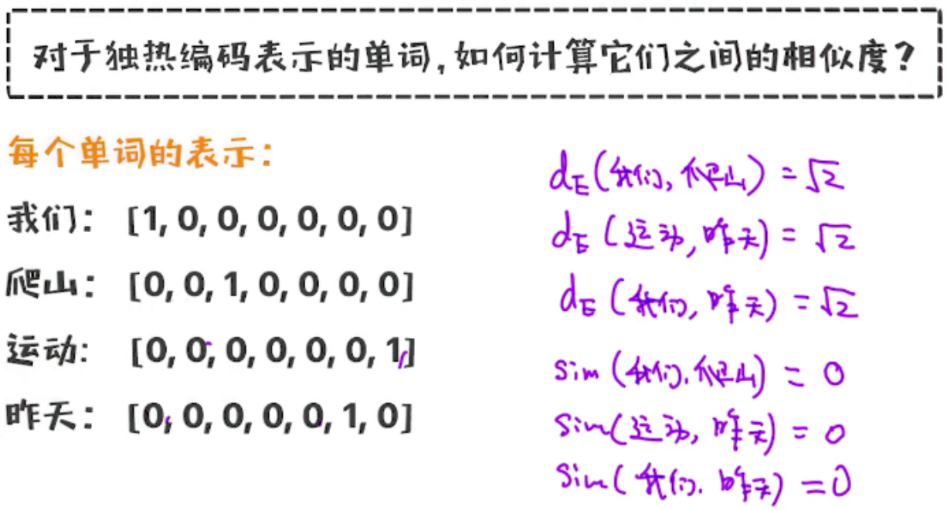
可以看到, 通过欧氏距离计算得到的很多单词之间的相似度都是一样的、没有区分度,因此通过欧氏距离计算两个单词之间的相似度是不够合理的;使用余弦相似度时,得到的余弦相似度也是相同的,也不能用来刻画单词之间的相似度。问题可能存在于两方面:单词的独热编码的表示方式存在一定的问题;计算相似度的两种方式不太合理。同时,计算相似度时,需要保证相关的词的近似度较高,与人的常识保持一致。
对于独热编码,还有一个问题,即稀疏性(Sparsity),即一个向量或矩阵中大部分都为0,只有少部分有意义的值。可以看到,在独热编码方式中,每一个向量都只有一个位置部位0、其余位置都为0。既然独热编码表示不支持计算两个单词之间的相似度,就需要找到另外一种单词的表示法。
2.词向量基础
独热编码的方式存在一些问题,分布式表示法可以解决这个问题,词向量就是分布式表示法的一种形式。举例如下:
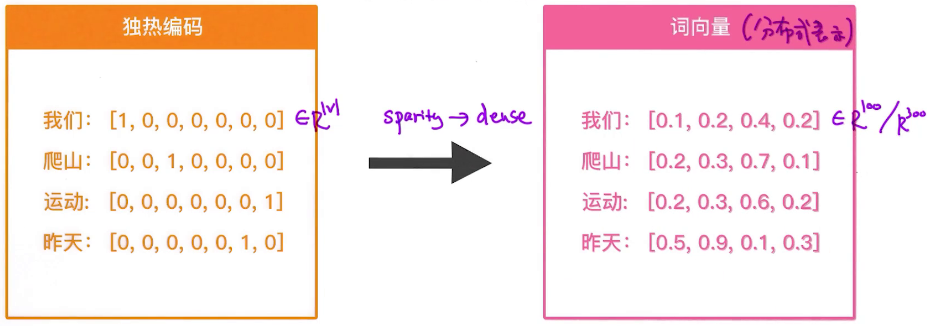
可以看到,词向量表示法中不再具有稀疏性,而是变得很稠密;同时词向量的大小可以通过超参数来控制,而与词库等没有关系。同时需要注意,独热编码和词向量是两套不同的词和句子的表示方法,如果词表示选择独热编码,句子表示也只能选择对应的Count Vector和tf-idf;如果词表示选择词向量,句子表示也应该选择对应的表示方式。
给定了词向量后,可以计算两个词之间的相似度。以欧氏距离方法举例如下:

可以看到,在分布式表示方法下,两个单词之间的相似度是可以算出来的。同时,得到的相似度准确与否取决于词向量的质量。
现在进一步分析词向量的得来:
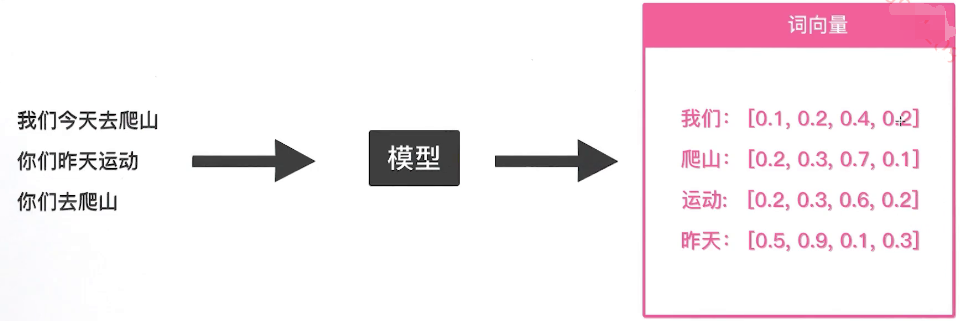
词向量是由模型训练选择出来的,给模型输入大量的数据,覆盖了几乎所有单词,通过训练来得到每个词的词向量。常见的模型包括GloVe、SkipGram、ELMO、BERT等模型。模型越好,词向量的质量也更高;同时不同的模型训练出来的词向量的使用场景也不相同。
现在进一步定义词向量的含义:
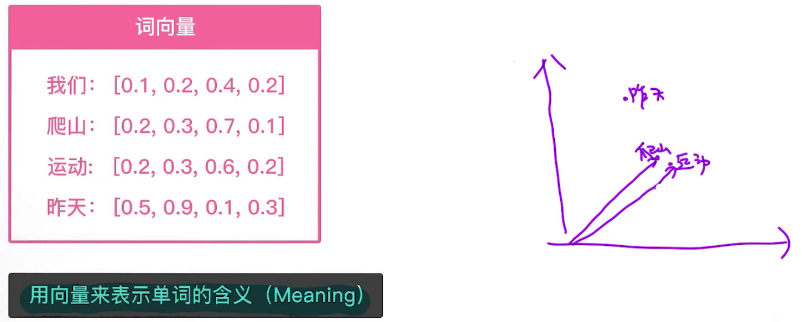
设计词向量的目的是用向量来表示单词的含义,也就是用数字化形式来表示抽象内容。在进行可视化时,一个好的模型得到的词向量的可视化效果也更好,也可以通过可视化的方式来判断得到的词向量的质量,同时如果词向量的维度很高时,可以先把词向量降维到低维的空间,再做可视化。
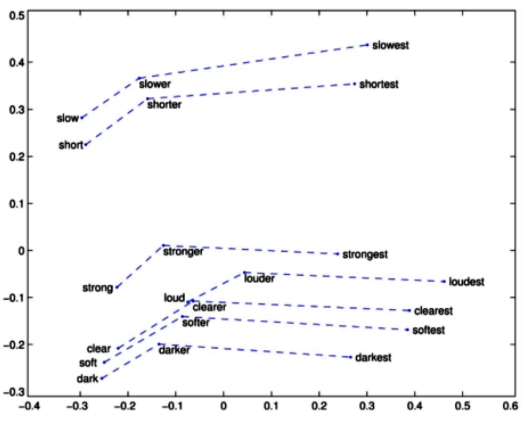
可视化举例如下:
英文词向量可视化
中文词向量可视化
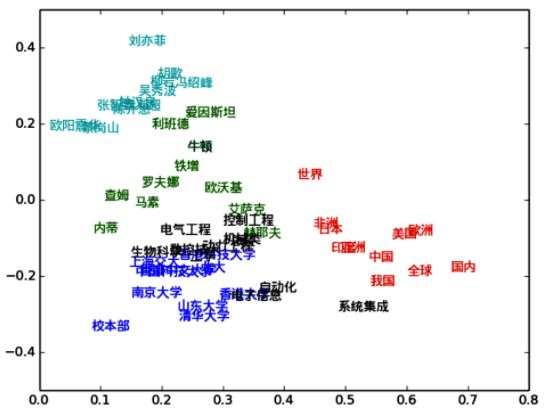
从上图可以看到,语义上比较相似的单词聚集在了一起,这其实变相地说明,词向量在某种意义上表达出了一个单词的含义。为了可视化词向量而使用的降维技术可以参考https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html,这也是一种常用的降维方法。
3.句子向量
在分布式系统中也可以表示句子的向量。在已经有了训练好的词向量的情况下,要通过这些词向量来表示一个完整的文本或者一个句子,一种最简单且常用的方法就是进行平均,如下:

可以看到,上面采用了最简单的方法——取平均值。同时句子向量的质量也很大程度上依赖于组成句子的词的词向量的质量。
有了文本表示之后,就可以开始对文本进行建模了,比如计算两个文本之间的相似度,或者对某个文本进行分类。
小结如下:
单词的独热编码和分布式表示是两种完全不一样的编码方式,这两种不同的编码方式是目前文本表示的两个方向,有些时候传统的独热编码的方式可能更适合,有些时候分布式表示法更适合,具体还是要通过测试来获得结论。独热编码的最大问题是不能表示一个单词的含义;词向量的质量取决于词向量训练模型,不同的模型给出的结果是不一样的。
扫码进群:
 分类导航
分类导航