

 个人中心
个人中心 退出
退出




PyTorch使用常见异常和解决办法汇总
文章目录
1.使用conda安装PyTorch后同时在Jupyter导入失败No module named ‘torch’
通过Conda安装PyTorch,同时在Jupyter中导入PyTorch,会报错No module named 'torch'。
分析:
原因就是在使用Jupyter Notebook的时候,加载的仍然是默认的Python Kernel。
解决:
(1)在Conda中切换到安装PyTorch的虚拟环境,然后执行conda install nb_conda_kernels安装Jupyter内核切换工具。
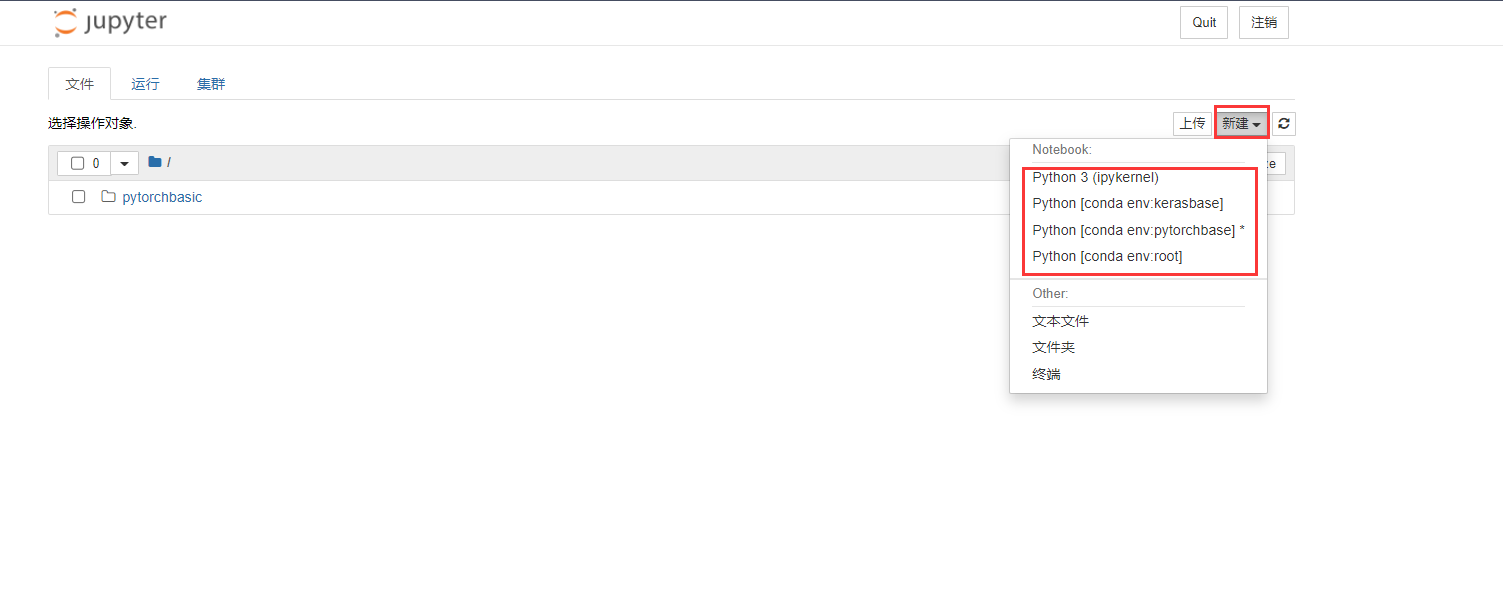
安装完成后,再重启Jupyter Notebook,在新建脚本时就能选择Kernal:
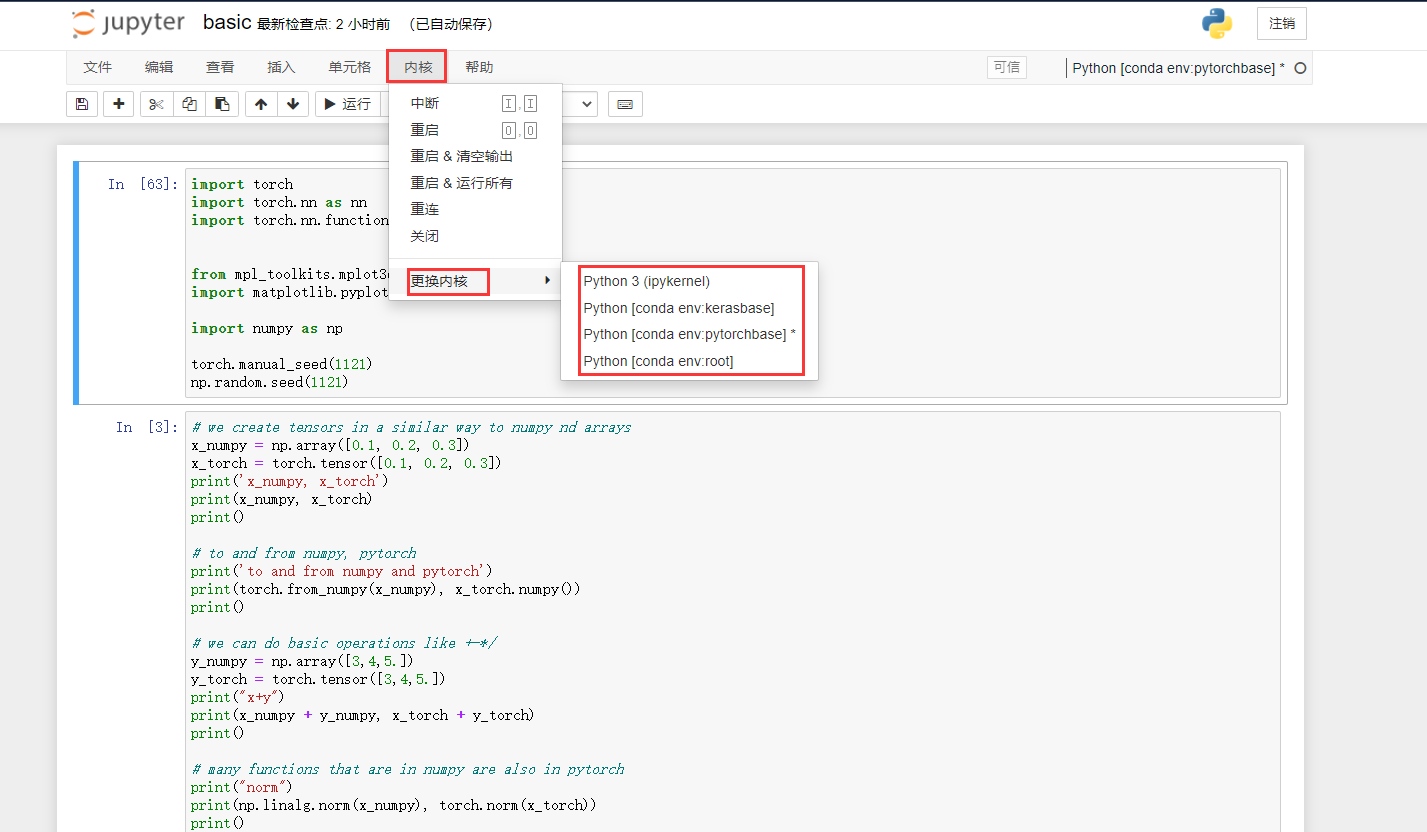
也可以对建好的文件切换Kernal:
2.PyTorch使用张量时报错expected scalar type Double but found Float
有时候,使用张量Tensor会报错:
RuntimeError: expected scalar type Double but found Float
分析:
这是因为张量的数据类型不正确。
解决:
此时需要先进行类型转换,将数据类型转为float32,再进行操作,如下:
tensor = tensor.to(torch.float32)
3.PyTorch创建Embedding时报错IndexError: index out of range in self
PyTorch中很多时候都会用到Embedding嵌入,特别是在NLP任务中,用于存储一个简单的存储固定大小的词典的嵌入向量的查找表,按时在创建EMbedding时有时候会出错,如下:
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\modules\sparse.py", line 158, in forward
return F.embedding(
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\functional.py", line 2044, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
分析:
这是因为num_embeddings(词典的词个数)不够大,进行词嵌入的时候字典从1, …, n,映射所有的词(或者字)num_embeddings =n是够用的,但是会考虑pad,pad默认一般是0,所以我们会重新处理一下映射字典0, 1, 2, …, n一共n+1个值,此时num_embeddings=n+1才够映射。
解决:
修改参数num_embeddings的值为实际词个数+1即可解决这个问题。
扫码进群:
 分类导航
分类导航