

 个人中心
个人中心 退出
退出




Hive窗口函数row number的用法
条评论

row_number
前面我们介绍窗口函数的时候说到了窗口函数的使用场景,我们也给它起了一个名字进行区分,通用窗口函数和特殊窗口函数,今天我们就来看一下排序相关的窗口函数,因为是窗口函数,并且我们说它是用来排序的,我们大概也能猜到它就是用来对窗口内的数据进行排序的
其实关于排序我们前面也介绍过order by,sort by 等排序的方式Hive语法之常见排序方式,为什么还有窗口函数进行排序的,因为前面的order by,sort by 等虽然可以排序但是不能给我们返回排序的值(名次),如果你用过mysql 的话,这个时候你就知道写存储过程或者使用自定义变量来完成这个功能,row number 也是一样的道理,可以按照我们自定义的排序规则,返回对应的排序先后顺序的值
所以我们认为row_number是窗口排序函数,但是hive 也没有提供非窗口的排序函数,但是我们前面说过了如果没有窗口的定义中没有partition by 那就是将整个数据输入当成一个窗口,那么这种情况下我们也可以使用窗口排序函数完成全局排序。
测试数据
下面有一份测试数据id,dept,salary,然后我们就使用这份测试数据学习我们的窗口排序函数
1,销售,10000
2,销售,14000
3,销售,10000
4,后端,20000
5,后端,25000
6,后端,32000
7,AI,40000
8,AI,35000
9,AI,60000
10,数仓,20000
11,数仓,30000
12,数仓,32000
13,数仓,42000从例子中学习 row_number
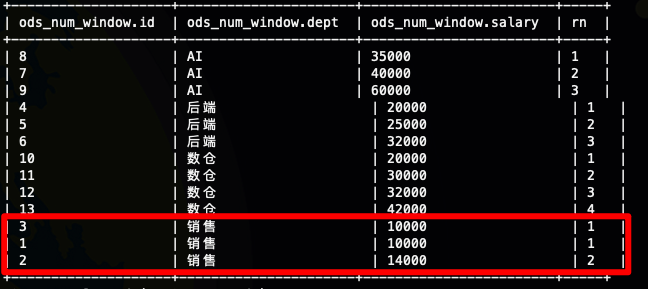
每个部门的员工按照工资降序排序
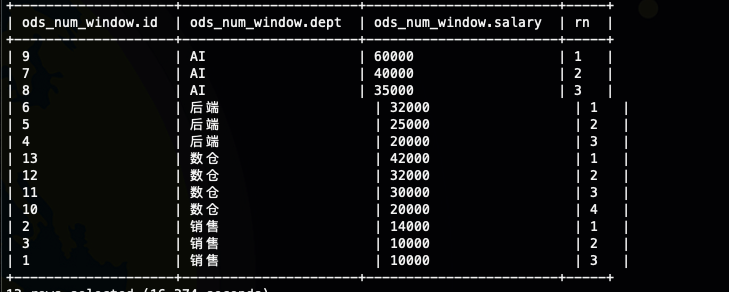
我们看到每个部门都有自己的第一名,明显的可以看到排序是发生在每个部门内部的
全部的员工按照工资降序排序
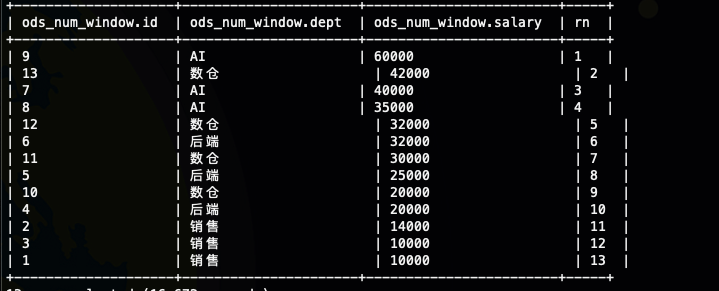
当我们没有定义partition by 子句的时候,我们的所有数据都放在一个窗口里面,这个时候我们的排序就是全局排序,其实如果你仔细看过我们的Hive语法之窗口函数初识这一节的话,你就知道partition by 其实是定义了子窗口,如果没有子窗口的话,那就就是一个窗口,如果所有的数据都放在一个窗口的话那就是全局排序
取每个部门的工资前两名
这个是row_number() 函数非常常见的使用场景top-N,其实如果你仔细看过我们的Hive语法之窗口函数初识这一节的话,你就知道partition by 其实是定义了子窗口,那其实这里的top-N,本质上是子窗口的的top-N
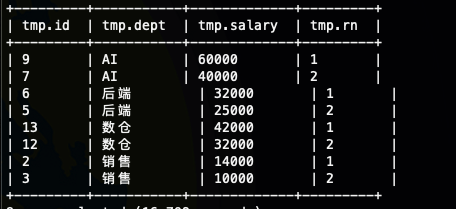
其实这个的实现方式就是我们对数据在子窗口内进行排序,然后选择出我们我们需要的数据,也就是这里的 rn <=2
rank 和 dense_rank
其实这两个窗口函数和row_number 是一样的,都是窗口排序函数,既然这样那为什么还有这两个函数呢,存在即合理,我们看一下row_number 函数,这次我们采用升序排序
select
*,row_number() over(partition by dept order by salary) as rn
from
ods_num_window
;我们看到在销售部门有两个人的工资其实是一样的10000,但是排名不一样
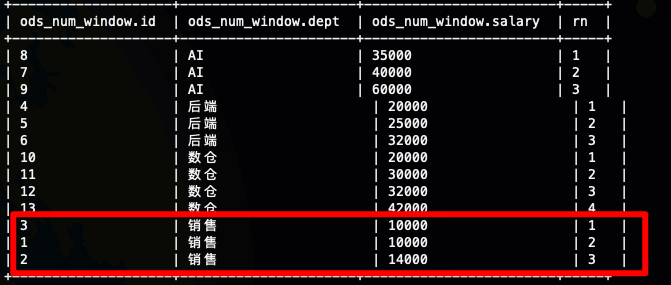
接下来我们看一下rank,我们发现销售部门那两个工资相等的实并列第一了,然后下一个人直接第三了

接下来我们再看一下 dense_rank,工资相等的两个人依然是排名相等的,但是下一个人还是第二
使用场景
Top-N
Top-n 前面我们已经介绍过了,这里就不再介绍了
计算连续
什么是计算连续呢,这个名字有点不太合理,这里举个例子方便大家理解,加入我有个用户访问日志表,那我想筛选出哪些超过连续7天都访问的用户,或者我想计算连续访问天数最大的10位用户
下面是一份测试数据用户ID,访问日期
1,2020-12-01
1,2020-12-02
1,2020-12-03
1,2020-12-04
1,2020-12-05
1,2020-12-06
1,2020-12-07
1,2020-12-08
1,2020-12-09
1,2020-12-10
2,2020-12-01
2,2020-12-02
2,2020-12-03
2,2020-12-04
2,2020-12-06
2,2020-12-07
2,2020-12-08下面是我们的建表语句
CREATE TABLE ods.ods_user_log (
id string,
ctime string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath '/Users/liuwenqiang/workspace/hive/user_log.txt' overwrite into table ods.ods_user_log;现在我们分析一下这个问题,怎么计算连续呢,计算肯定是针对同一个用户的,然后我们可以按照用户的访问时间进行排序,然后我们用日期的数字减去对应的排序就会得到一个值,如果访问时间是连续的话,我们就可以得到同一个值
select
id,ctime,
row_number(partition by id order by ctime ) as rn
from
ods_user_log
;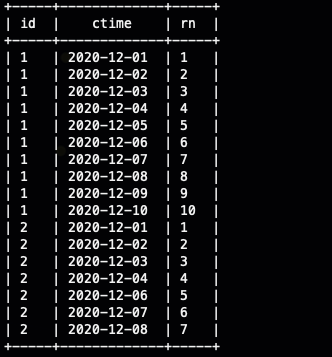
这里为了演示效果比较明显,所以设计的数据有点特殊,大家可以看到对于id 是1的用户,我们发现从12月1号到12月10号,我们的排名也依次是从1到10的,这个时候我们只要将日期变成对于的数字,然后减去对应的排名它是等于20201200的,这个时候我们只需要统计20201200的个数,这个个数就是连续登陆的天数,这里我们就不把日期转换成转换成数字然后做减法了,我们直接使用日期去减。
select
id,ctime,
date_sub(cast(ctime as date),row_number() over(partition by id order by ctime)),
row_number() over(partition by id order by ctime ) as rn
from
ods_user_log
;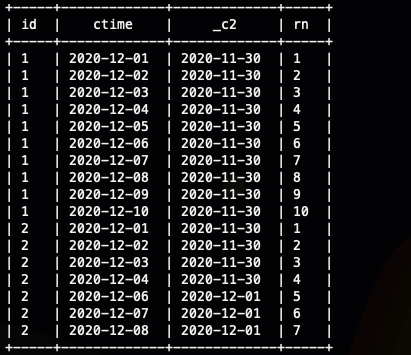
这下我再去统计每个用户的相同日期有多少个即可,在我这里因为是7天,所以我只需要计算出相同日期的个数大于等于7即可

我们尝试着理解一下这个数据,它的意思就是用户1 从(2020-11-30+1) 日开始,连续10天访问了网站
这里有个问题需要注意一下,那就是上面我造的数据就是每天一条的,如果每天如果有多条,那我们上面的代码就不对了,所以这个时候我们不是需要使用dense_rank,大家注意理解一下,我们需要的是去重,大家注意理解一下
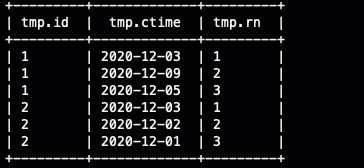
分组抽样
其实抽样这个东西大家都接触过,随机抽样也接触过,今天我们学习一下分组随机抽样,其实实现很简单,我们使用row_number 在子窗口内随机排序,然后抽出所需的样本数据即可,我们还是用上面的数据,每个用户随机抽取三天登陆
总结
- rank() 排序相同时会重复,总数不会变(会有间隙跳跃,数据不连续)
- dense_rank() 排序相同时会重复,总数会减少(不会有间隙,数据连续的)
- row_number() 会根据顺序计算,不会重复不会减少
- Row_number 函数常用的三种场景Top-N,计算连续,分组抽样
作者:柯广的网络日志
微信公众号:Java大数据与数据仓库
 分类导航
分类导航