

 个人中心
个人中心 退出
退出




「Hive进阶篇」HQL底层执行过程及原理详解
一、hive几大组件
ui:用户界面,我们提交hiveQL的命令行界面
driver:驱动程序,接受查询的组件
compiler:编译器,负责将hiveQL编译为MapReduce,对不同的查询块和查询表达式进行语义分析,最终借助表和元数据库查找的分区元数据 来生成执行计划
metastore:元数据库,存储hive各种表和分区的元数据信息
executor engine:执行引擎,负责将compiler编译器 编译好的执行计划提交到不同的平台上去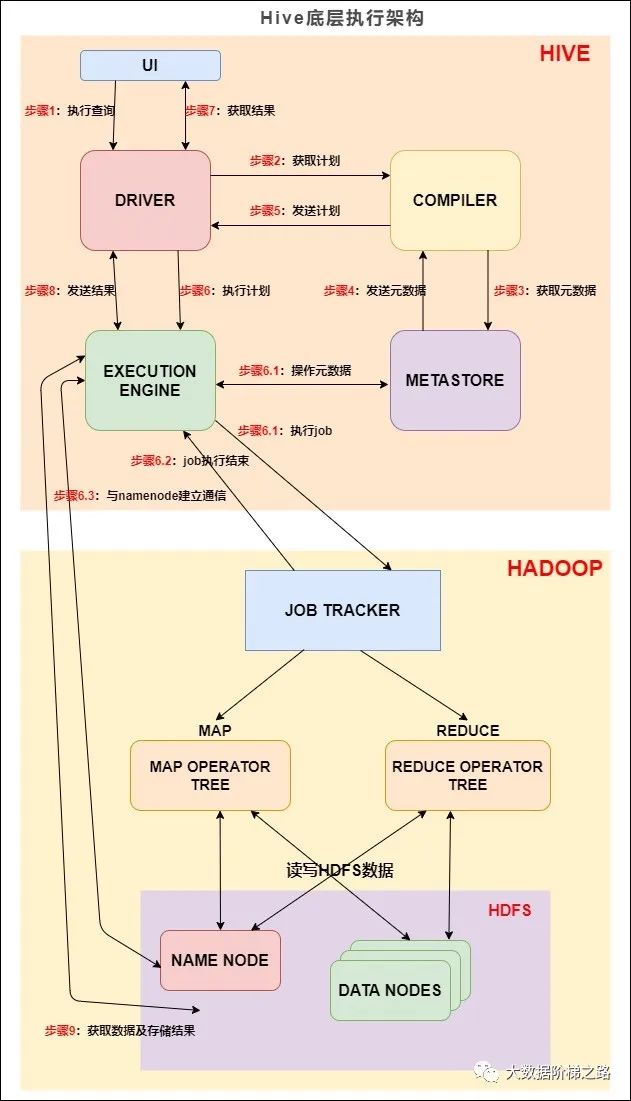
针对上图的流程,我简要概述:hive的执行入口是driver,提交的hql语句首先到driver,由driver来负责执行管理,之后查找元数据信息,再调用compiler编译器解析hql语句成物理计划返回给driver,然后把物理执行计划连同元数据发送给执行引擎执行,至此这就到了hadoop层面的MapReduce程序了。
二、hiveQL编译成MapReduce过程
这个hiveQL编译成MapReduce的过程就是在上面的COMPILER组件里完成的。编译过程主要有以下六个步骤:
词法语法解析 ->语义解析 ->生成逻辑执行计划 ->优化逻辑执行计划 ->生成物理执行计划 ->优化物理执行计划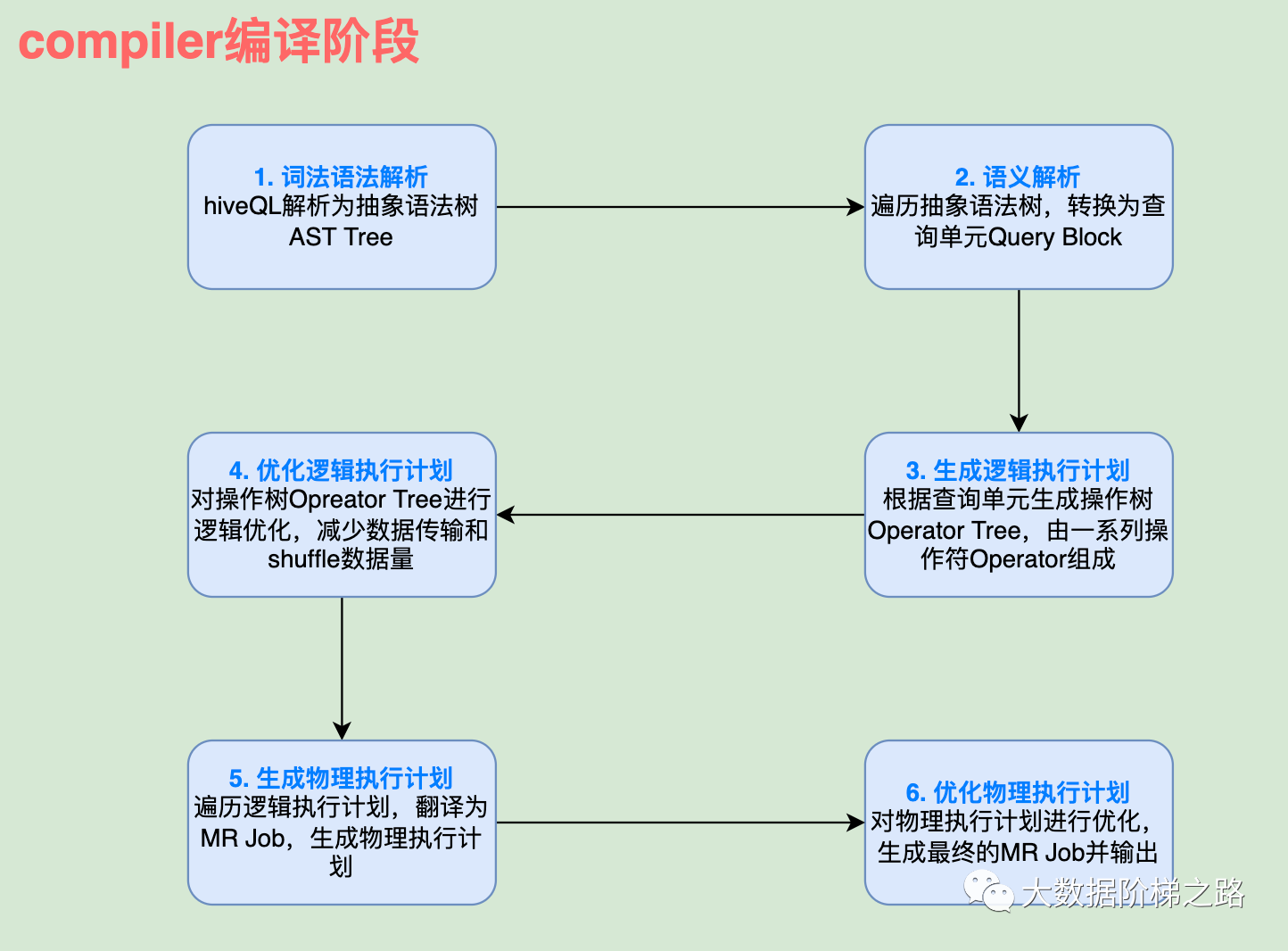
①词法语法解析:先是由解析器解析hiveQL语法和词法,生成抽象语法树AST Tree;
②语义解析:然后遍历抽象语法树,转换为查询单元Query Block,查询单元是一条sql最基本的组成单元,查询单元包含了输入源、计算过程、输出 三个部分;
③生成逻辑执行计划:遍历查询单元,生成操作树Operator Tree,操作树是由一系列操作符Opreator组成,每一个操作符完成操作后就将数据流式传递到下一个操作符进行逻辑计算;
④优化逻辑执行计划:逻辑层优化器针对逻辑执行计划做优化,比如合并多余的操作符,达到减少MapReduce Job,减少数据传输和shuffle数据量;
⑤生成物理执行计划:遍历逻辑执行计划,翻译为MapReduce任务,生成物理执行计划;
⑥优化物理执行计划:物理层优化器针对物理执行计划做优化,最终生成MR job并输出。
作者:bigdataladder
欢迎关注微信公众号 :大数据阶梯之路
 分类导航
分类导航