

 个人中心
个人中心 退出
退出




关于数仓建模中的空值处理——以阿里云Dataworks语法为例
篇首语
大家好,我是唐三少,今天给大家带来热心读者的投稿,欢迎大家品读。废话不多说,再次上号。
1 数据准备
在日常建模过程中,我们会遇到不同的空值的情形,在不同的情况下需要有不同的处理方式。
首先我们先创建两张表,分别是学生表和班级表
create table yht_dw_dev.t_student_info(
id string COMMENT '学号',
stu_name string COMMENT '学生姓名',
class_id string COMMENT '班级id'
)TBLPROPERTIES('comment'='学生表');
create table yht_dw_dev.t_class_info(
id string COMMENT '班级id',
class_name string COMMENT '班级'
)TBLPROPERTIES('comment'='班级表');
然后我们构造数据插入表中:
insert overwrite table yht_dw_dev.t_student_info
select
*
from(
select 's001' as id,'高启 强' as stu_name,'c001' as class_id union all
select 's002' as id,'安欣 ' as stu_name,'c003' as class_id union all
select 's003' as id,' 孟钰' as stu_name,'c002' as class_id union all
select 's004' as id,'孟德海 ' as stu_name,'c005' as class_id union all
select 's005' as id,'徐忠\n' as stu_name,'c001' as class_id union all
select 's006' as id,'李\r响' as stu_name,'c002' as class_id union all
select 's007' as id,'陈\t书婷' as stu_name,'c002' as class_id union all
select 's008' as id,'杨 健' as stu_name,'c001' as class_id union all
select 's009' as id,'吴刚\r' as stu_name,'c003' as class_id union all
select 's010' as id,'\r张志\n\n坚' as stu_name,'c004' as class_id union all
select 's011' as id,'李健\t' as stu_name,'c003' as class_id union all
select 's012' as id,'\t高)叶' as stu_name,'c004' as class_id union all
select 's013' as id,'张\n颂(文 \t' as stu_name,'c005' as class_id union all
select 's014' as id,'\n张\r\r译' as stu_name,'c001' as class_id
) t1 ;
insert overwrite table yht_dw_dev.t_class_info
select
id,
class_name
from
(
select 'c001' as id,'卖鱼班' as class_name union all
select 'c002' as id,'调查组班' as class_name union all
select 'c003' as id,'狡猾班' as class_name union all
select 'c004' as id,'演员班' as class_name
)tt
2 Join后得到的空值的处理方式
上文中t1和t2两表关联后,如下:
select
t1.id as stu_id,
stu_name,
t1.class_id,
t2.class_name
from yht_dw_dev.t_student_info t1
left join yht_dw_dev.t_class_info t2
on t1.class_id=t2.id
关联后结果如下,我们发现在class_name列存在空值。
在某些实际建模过程中可能需要对空值进行处理,我们可以用nvl() 或者coalesce() 函数进行处理。
select
t1.id as stu_id,
stu_name,
t1.class_id,
t2.class_name,
nvl(t2.class_name,'-') as nvl_class_name,
coalesce(t2.class_name,'-') as coal_class_name
from yht_dw_dev.t_student_info t1
left join yht_dw_dev.t_class_info t2
on t1.class_id=t2.id
处理后的结果,如下:
3 值中存在空值处理方式
3.1 单元格存在空格——开头或者结尾
Dataworks提供了三个函数针对这样的情景:trim,rtrim和ltrim,我们来看最后代码和结果:
select
t1.id as stu_id,
stu_name,
trim(stu_name) as trim_stu_name,
case when length(stu_name)>length(trim(stu_name)) then '空格剔除' else '空格未剔除' end as is_trim,
-- trim函数是否有效
rtrim(stu_name) as rtrim_stu_name,
case when length(stu_name)>length(rtrim(stu_name)) then '空格剔除' else '空格未剔除' end as is_rtrim,
-- rtrim函数是否有效
ltrim(stu_name) as ltrim_stu_name,
case when length(stu_name)>length(ltrim(stu_name)) then '空格剔除' else '空格未剔除' end as is_ltrim
-- ltrim函数是否有效
from yht_dw_dev.t_student_info t1
where regexp_count(stu_name,'\\s')>=1
-- 筛选stu_name字符串中含有空白字符的项
*需要注意的一点是 \s 指空格,换行,tab缩进等空白字符,时间长了,大家很容易误认为其仅代表空格 ,下面的例子很容易说明这个问题。
根据上述的结果中,我们发现,trim是可以将字符串开始和字符串结尾的连续空格去除(比如上图数字1部分),对\n 、\r 、\t 等空白无法做剔除,对字符串内部空格不起作用;rtrim是可以将字符串结尾的连续空格去除(比如上图数字2部分),对\n 、\r 、\t 等空白无法做剔除,对字符串内部空格不起作用;ltrim是可以将字符串开始的连续空格去除(比如上图数字3部分),对\n 、\r 、\t 等空白无法做剔除,对字符串内部空格不起作用。
当然了,此处你也可以用replace 函数,不过前提是你需要知道字符串中空白字符具体是什么,并且不支持多种空白字符同时使用或者正则表达式的使用,除非你愿意嵌套,这是可以的。
综上所述,不论是trim,rtrim和ltrim三个函数,是存在局限性的。那问题就来了,对于非空格的其他空白字符怎么处理呢?对于字符串内部的空白字符怎么处理呢?对于同时有多种空白字符怎么处理呢?
3.2 单元格字符串空格通用处理
此处,我们引入需要使用 正则表达式 的函数 regexp_replace(待处理的值,匹配值,替换的值) ,脚本和结果如下:
select
t1.id as stu_id,
stu_name,
regexp_replace(stu_name,'\\s+','') as trim_stu_name,
case when length(stu_name)>length(regexp_replace(stu_name,'\\s+','')) then '空格剔除' else '空格未剔除' end as is_trim
from yht_dw_dev.t_student_info t1
where regexp_count(stu_name,'\\s')>=1
从上图中我们可以看到结果,对于字符串中的开始,结果或者中间存在的空白字符(空格,\n,\r,\t),都被剔除了。
简单说明一下其中的正则参数:'\s' 表示空白字符,双斜杠 '\\' 是表示对斜杠的转义,+表示前述一次或者多次,这样既能匹配单个空白字符也能匹配连续多个空白字符。具体想了解正则表达式的写法,可以参考菜鸟学院 正则表达式教程 。
如果同时要剔除多种符号,空白字符,有应该如何处理呢?regexp_replace 也提供了同时替换多种字符串的功能,可以用“|”隔开不同匹配模式,如下:
select
t1.id as stu_id,
stu_name,
regexp_replace(stu_name,'\\s+|\)|\(','') as trim_stu_name,
case when length(stu_name)>length(regexp_replace(stu_name,'\\s+','')) then '空格剔除' else '空格未剔除' end as is_trim
from yht_dw_dev.t_student_info t1
where regexp_count(stu_name,'\\s')>=1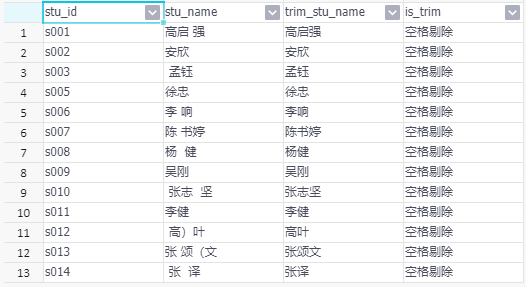
同时剔除多种模式
按照上述模式,是不是就能处理所有的空白字符以及指定字符呢?我们来看例子:
select
id as stu_id,
stu_name,
regexp_replace(stu_name,'\\s+|\)|\(','') as trim_stu_name,
case when length(stu_name)>length(regexp_replace(stu_name,'\\s+','')) then '空格剔除' else '空格未剔除'
from yht_dw_dev.t_student_info
where stu_name rlike '孟德海'
结果如下:
stu_id stu_name replace_stu_name is_replace
s004 孟德海 孟德海 空格未剔除
我们发现上面的删除模式也失败了,并没有被剔除,这种应该如何处理呢?
3.3 单元格字符串特殊空格处理
上述处理方式有两种,但是第一步都是一样的:
一、复制字符串到 在线编码转换器 网站,查看空白字符的编码,如下图: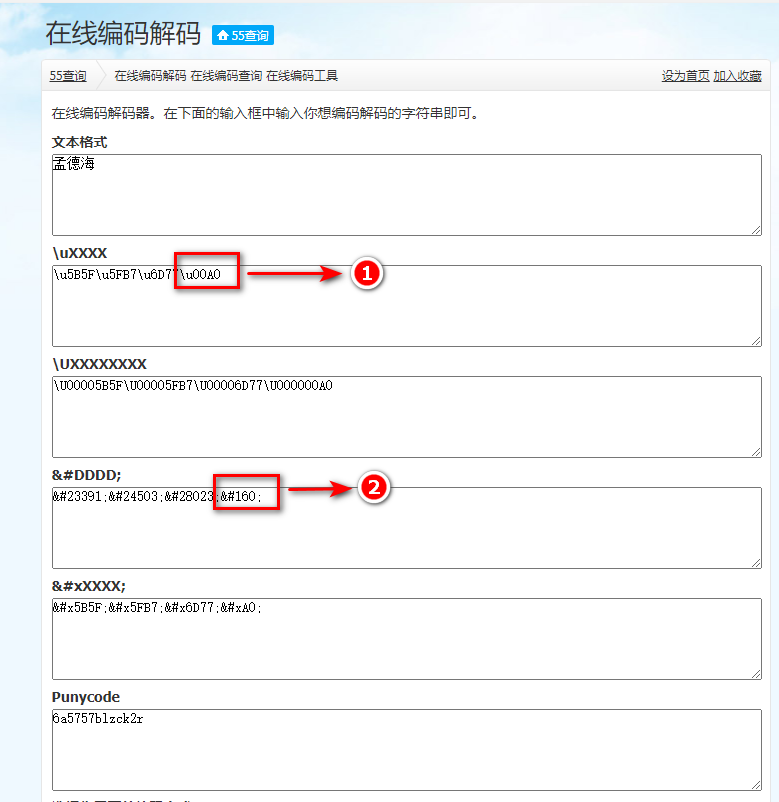
二、如图所示,如果 符号2 中的数字范围在0~255之间,我们可以直接将空白符转换为chr(数字),这样替换是没有问题的;如果符号2中的数字范围大于255,那么可以直接用1中的编码(如\u00A0)。具体脚本如下:
select
id as stu_id,
stu_name,
regexp_replace(regexp_replace(stu_name,'\\s+|\)|\(',''),chr(160),'') as trim_stu_name,
case when length(stu_name)>length(regexp_replace(regexp_replace(stu_name,'\\s+|\)|\(',''),chr(160),'')) then '空格剔除' else '空格未剔除'
from yht_dw_dev.t_student_info
where stu_name rlike '孟德海'
结果如下:
备注1:关于编码的替换
但是有一点需要说明:在dataworks上,使用 regexp_replace 函数使用上文提到的编码作为匹配模式,是不会成功的,至少在\u00A0编码上是替换不成功的,但是有的编码却是可以成功的。
如果有读者了解这里的细节,还希望在评论中进行交流。
备注2 :对常见空格的编码的说明
1.不间断空格\u00A0,主要用在office中,让一个单词在结尾处不会换行显示,快捷键ctrl+shift+space ;
2.半角空格(英文符号)\u0020,代码中常用的;
3.全角空格(中文符号)\u3000,中文文章中使用;
4.水平制表符\t
5.垂直制表符\v
6.换页符\f
7.不间断空白符\xa0
8.空格 ,HTML 中的空格表示形式
4 小结
本文洒洒两千字,其实重点要介绍的经验就是3.3小节中的对于一些特殊字符处理的经验。第一,对于字符串中出现的特殊空白字符可以通过线上转码网站来进行剖析其“庐山真面目”;第二,对于数仓建模过程中,想要清洗数据,对于正则表达式的使用是需要引起读者重视的,尤其是对于regexp_** 系列函数的熟练使用,可以有效简化语句,提升模型的运行效率。
个人水平有限,仅记录自身工作中的经验,以飨读者,还望多多指正。
作者: 教你学懂大数据
欢迎关注微信公众号 :教你学懂大数据
 分类导航
分类导航