

 个人中心
个人中心 退出
退出




Elasticsearch基本知识
ES是一个基于Apache的开源索引库Lucene而构建的 开源、分布式、具有RESTful接口的全文搜索引擎, 还是一个分布式文档数据库.
一、基本概念
1.index:
索引是具有相似结构的文档的集合, 比如可以有一个商品分类索引, 订单索引.
每个索引都要有唯一的名称, 名称要小写, 通过索引名称来执行索引、搜索、更新和删除等操作.
一个集群中可以有任意多个索引, 只要保证名称不同即可
2.document
文档是存储在ES中的一个个JSON格式的字符串, 是ES索引中的最小数据单元, 由field(字段)构成.
ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识.
3.field
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象.
字段类似于关系数据库中表数据的列, 每个字段都对应一个类型.
可以指定如何分析某一字段的值, 即对field指定分词器
4.type
一个索引中,可以定义一个或者多个类型(7.x版本中被废弃,8.x版本中已移除)
5.text
文本是field类型的一种, 通常会被分析成多个Term, 存储在ES的索引库中.
6.mapping
类似于关系数据库中的Table结构, 每个index都有一个映射: 定义索引中每个字段的类型.
所有文档在写进索引之前都会先进行分析, 如何对文本进行分词、哪些词条又会被过滤, 这类行为叫做映射(mapping).
映射可以提前定义, 也可以在第一次存储文档时自动识别.
7.analysis
将文本转换为索引词的过程, 分析的结果依赖于分词器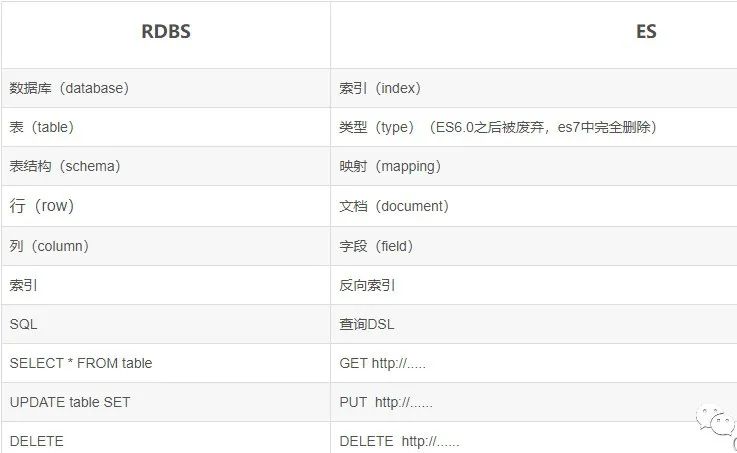
二、基本原理
正排索引:通过记录id查询内容记录;
倒排索引:通过内容关键词获取记录id。ES写入数据时,会把数据进行分词,把每一个分词的结果与文档进行关联,再把相同的词所关联的文档进行合并,建立倒排索引。
三、ES的字段
es的字段都有一个字段类型,不同的类型都各有所长,比如keyword类型的字段适合做聚合和排序,而text的类型可以用来全文搜索。下面按大类介绍下es常用的数据类型,es的数据字段的类型定义和搜索的方式紧密相关,
例如 keyword类型,Number类型在搜索时,只适合精准匹配,范围搜索之类的,不能用于全文搜索。而text类型适合全文搜索。
1.Common types
1.1 binary
二进制类型 ,值以base64字符串的形式存贮,_source默认不会存贮该类型的值,如果需要实际的存贮,请设置 store属性为true默认是false
type:binary
PUT my-index-000003
{
"mappings": {
"properties": {
"blob": {
"type": "binary",
"store": true
}
}
}
}
PUT my-index-000003/_doc/2
{
"blob": "U29tZSBiaW5hcnkgYmxvYg=="
}
1.1 boolean
布尔类型
type:boolean
true :true,“true"都可以表示 true
false: false,“false”,”" 都可以表示 false
PUT my-index-000003
{
"mappings": {
"properties": {
"boolean_field": {
"type": "boolean"
}
}
}
}
PUT my-index-000003/_doc/2
{
"boolean_field": "false"
}
1.2 Keywords
keywords大家庭包括 keyword,constant_keyword,widecard
keyword:类型的字段适合聚合(aggragate)和排序(sort)操作,term和term_level查询比较快,如果字段的值都是数字,但term查询比较多,可以考虑定义keyword类型,而不是interger或者其他数字类型,
constant_keyword:所有文档的该字段的值都是一样的,可以定义该类型
widecard:适合通配符搜索日志等场景 ,text类型不支持通配符搜索,但widecard 在聚合和排序的性能会低于其他keyword类型,而且如果前导词是通配符,搜索效率相对会比较慢。
PUT my-index-000003/_mapping
{
"properties": {
"my_keyword":{
"type": "keyword"
},
"my_constant_keyword":{
"type": "constant_keyword",
"value":"constant"
},
"my_wildcard": {
"type": "wildcard"
}
}
}
PUT my-index-000003/_doc/1
{
"my_keyword":"keyword",
"my_wildcard" : "This string can be quite lengthy"
}
GET my-index-000003/_search
{
"query": {
"wildcard": {
"my_wildcard": {
"value": "*quite*"
}
}
}
}
1.3 Numbers
数字类型:包括整数和浮点数类型,有 short,interger,long unsigned_long,
float,double,half_float,scaled_float(底层是以long类型存贮的,需要配置scaled_factor ,浮点数*scaled_factor,比如价格一般是2位小数 ,如果scaled_factor配置为100 ,某个文档的该类型字段的值为 98.99,那么底层存贮 9899,相对于直接存double,节约了存贮空间),不是该字段存的是数字类型就一定要定义数字类型,数字类型在range查询,和一些数值计算查询相对会快,但是如果是term查询不如keyword类型。
PUT /my-index-000003/_mapping
{
"properties": {
"number_of_bytes": {
"type": "integer"
},
"time_in_seconds": {
"type": "float"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
1.4 Dates
日期类型包括 date和date_nanos.类型,
date类型可以通过format属性指定字段值的日期格式, || 连接多种格式
如果没有显示的指定format的属性值,默认为"strict_date_optional_time||epoch_millis"
"strict_date_optional_time"为常规的iso日期时间转换器,格式“yyyy-MM-dd ‘T’ HH:mm:ss.SSSZ” or “yyyy-MM-dd”,es默认内置了很多日期格式,大家可以翻阅文档查看
PUT my-index-000003/_mapping
{
"properties": {
"create_time":{
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
POST my-index-000003/_doc
{
"create_time":"2021-05-15 23:14:55"
}
1.5 alias
为已存在的字段定义别名,别名可用于却大多数搜索api和field capabilities 。目前不是和写入api,比如添加或者更新等操作。
type : “alias”, path为当前目标字段的路径,如果该字段是有父类对象,
则path为 parentObject1.parentObject2.target_field
例如:
PUT /my-index-000003
{
"mappings": {
"properties": {
"user_name":{
"type": "text"
},
"name":{
"type": "alias",
"path" :"user_name"
},
"friends":{
"type": "nested",
"properties": {
"friends_name":{
"type":"text"
},
"f_name":{
"type": "alias",
"path":"friends.friends_name"
}
}
}
}
}
}
POST /my-index-000003/_doc/1
{
"user_name":"ly",
"frends":{
"friends_name":"luck"
}
}
GET /my-index-000003/_search?pretty
{
"query": {
"match": {
"name": "ly"
}
}
}
2.Objects and relational types(对象关系类型)
2.1 object
对象类型:字段值是一个json对象
POST customer/_doc/3
{
"name":"孙七",
"state":1,
"create_time":"2021-03-14 18:00:00",
"other":{
"age":27,
"address":"beijin",
"phone":"10010"
}
}
不显示指定字段类型,直接往里添加文档也是可以的,es默认会帮我们创建合适的类型,其他对象类型还有flattened,nested,join在object的基础上,提供了自己的一些特性,弥补了object的不足
3.Text search types(文本搜索类型)
text是全文搜索类型,在建立索引和搜索时,输入的文本会经过分析器处理(Analyzed),分析器会对其进行过滤,分词,转换等操作。es内置了多种分析器,而且我们可以定义分析器。
只有text类型才能用于match,match_phrase等搜索语句,
PUT /my-index-000003
{
"mappings": {
"properties": {
"user_name":{
"type": "text"
}
}
}
}
POST /my-index-000003/_doc
{
"user_name":"jack liu"
}
GET /my-index-000003/_search
{
"query": {
"match": {
"user_name": "jack"
}
}
}
4. Arrays 数组类型
es没有专门的数组类型,所有类型字段都可以一个或者多个值,只是多个值得类型必须相同。
PUT my-index-000001/_doc/1
{
"message": "some arrays in this document...",
"tags": [ "elasticsearch", "wow" ],
"lists": [
{
"name": "prog_list",
"description": "programming list"
},
{
"name": "cool_list",
"description": "cool stuff list"
}
]
}
作者:码农编程进阶笔记
欢迎关注微信公众号 :码农编程进阶笔记
 分类导航
分类导航