

 个人中心
个人中心 退出
退出




MongoDB快速入门
微信公众号:运维开发故事,作者:double冬
1 进入MongoDB的世界
随着大数据时代的到来,数据急速增长,导致关系型数据库(SQL)越来越不够用。高性能、可扩展的数据库变得越来越重要起来,在这样的场景下,非关系型数据库(NoSQL)应运而生,这里的“NoSQL”不是“NoSQL(不是SQL)”,而是“Not only SQL(不仅是SQL)”的简称。2009年,分布式文档型数据库MongoDB引发了一场去SQL的浪潮。
1.1 非关系型数据库的分类及特点非关系型数据库主要分为以下几类
- 1.键值数据库
主要代表是Redis、Flare。这类数据库具有极高的读写性能,用于处理大量数据的高访问负载比较合适。
- 2.文档型数据库
主要代表是MongoDB、CouchDB。
这类数据库满足了海量数据的存储和访问需求,同时对字段要求不严格,可以随意地增加、删除、修改字段,且不需要预先定义表结构,所以适用于各种网络应用。
- 3.列存储数据库
主要代表是Cassandra、Hbase。这类数据库查找速度快,可扩展性强,适合用作分布式文件存储系统。
- 4.图数据库
主要代表是InfoGrid、Neo4J。这类数据库利用“图结构”的相关算法,适合用于构建社交网络和推荐系统的关系图谱。
1.2 MongoDB适合做什么
MongoDB适合储存大量关联性不强的数据。MongoDB中的数据以“库”—“集合”—“文档”—“字段”结构进行储存。这种结构咋看和传统关系型数据库的“库”—“表”—“行”—“列”结构非常像。但是,MongoDB不需要预先定义表结构,数据的字段可以任意变动,并发写入速度也远远超过传统关系型数据库。
1.3 从文件到MongoDB数据库
对于少量数据,可以使用“记事本”程序来保存。但如果需要对数据进行计算,那么记事本显然就不能胜任了。此时可以考虑 Excel。还可以使用Excel 的数据透视表来统计数据,如图所示。
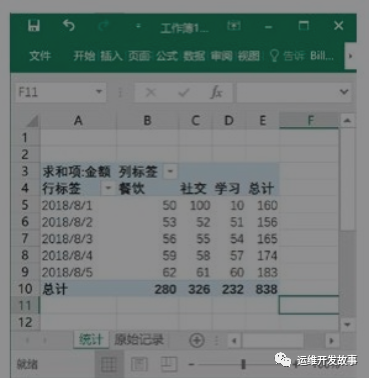
Excel的一张表可以存放100万行左右的数据,那如果每天的数据都超过100万行呢?此时就不得不使用数据库来保存了。
使用MongoDB保存数据使用数据库,可以保存大量的数据,这是数据库最基本的功能。另外,数据库还能够对数据进行逻辑运算、数学运算、搜索、批量修改或删除。相比于传统的关系型数据库,MongoDB对于每一次插入的字段格式没有要求,字段可以随意变动,字段类型也可以随意变动,如图所示。
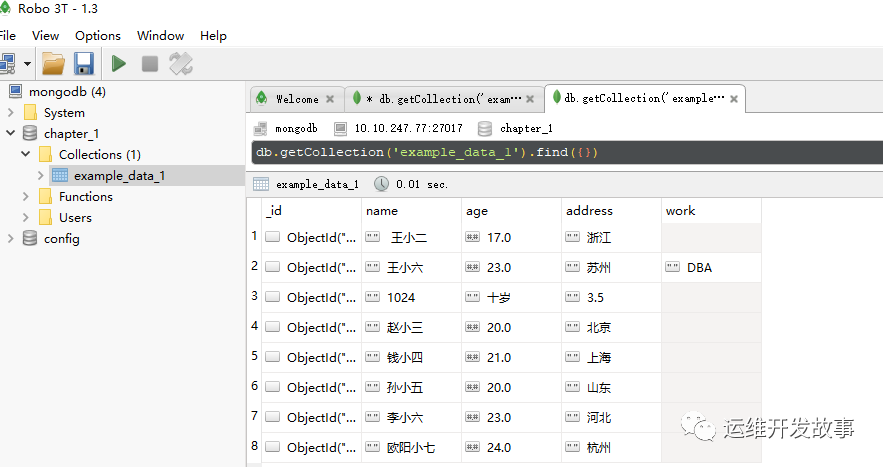
image.png
MongoDB可以并发插入上万条文档,这是传统关系型数据库所不能望其项背的。
2 MongoDB快速入门
会介绍MongoDB的安装和基本语法。另外,介绍在图形化管理工具Robo 3T中操作MongoDB,以及使用Python操作MongoDB的方法
MongoDB的语法与Python非常相似。在很多情况下,操作MongoDB的代码都可以直接用到Python中。所以,结合Python来学习MongoDB可以起到事半功倍的效果
1.1 MongoDB和SQL术语对比
SQL与MongoDB术语对比见
| SQL | MongoDB |
|---|---|
| 表(Table) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象ID(Objectid) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
| 数组(Array) | 数组(Array) |
1.2 安装MongoDB
1.2.1 在Windows中安装
- (1)访问 MongoDB 官网的下载页面(https://www.mongodb.com/download-center?jmp=nav#community),单击“DOWNLOAD(msi)”按钮。
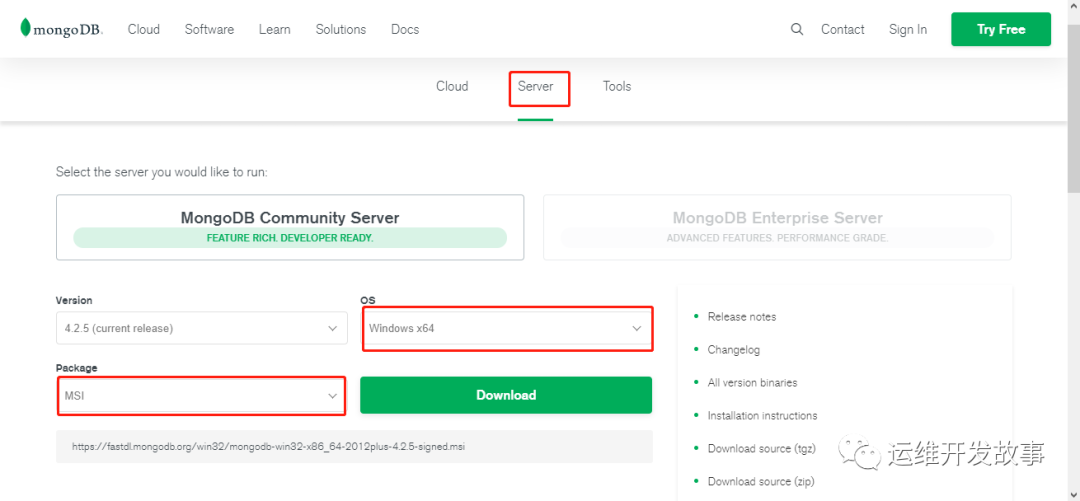
image.png
- (2)双击下载的文件(如无特殊说明,只需要一直单击“Next”按钮即可)。在安装过程中将会看到如图所示的界面选择安装方式,这里单击“Custom”按钮。
image.png
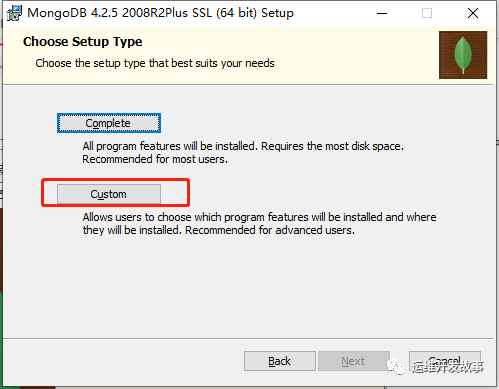
image.png
- (3)修改文件的安装路径到 D:\MongoDB\Server\,单击“Next”按钮进行安装,如图所示。
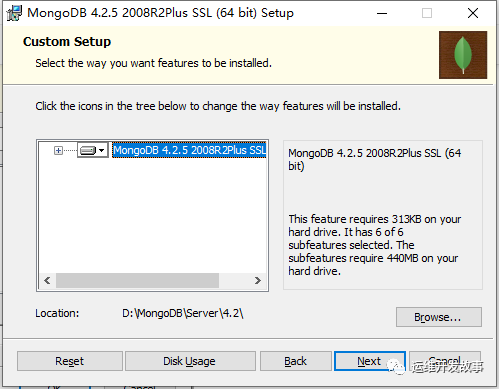
image.png
- (4)安装完成以后,进入D:\MongoDB\Server\4.2\bin,可以看到如图所示的内容,配置文件为mongod.cfg
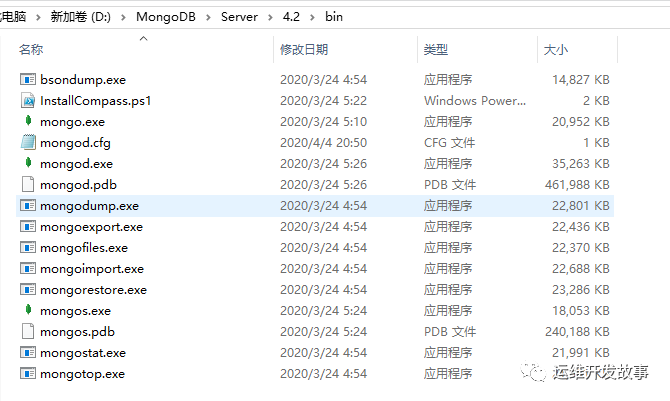
image.png
- (5)日志路径为D:\MongoDB\Server\4.2\log
正常安装完成之后,mongodb已经注册到服务,并已正常运行,后续的启停都在这里管理
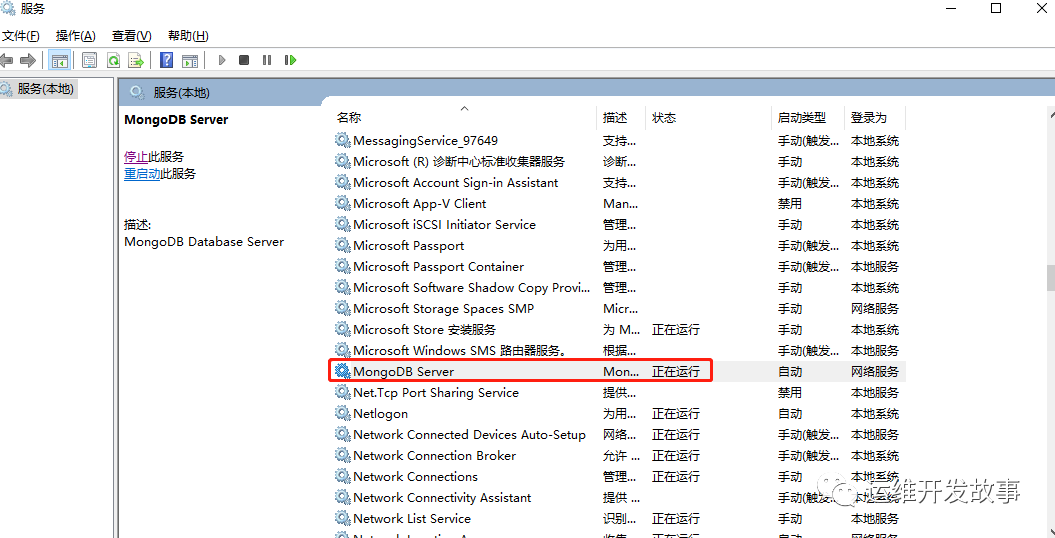
image.png
1.2.2 在Linux中安装
由于 Linux 有众多的发行版,不同发行版本有不同的包管理工具,所以在各个发行版本中安装MongoDB的命令可能会有一些差异。本文以Centos7.6为例,来说明如何安装MongoDB。
1.配置MongoDB的yum源
创建yum源文件
添加以下内容:(我们这里使用阿里云的源,安装的是4.25版本)
[root@localhost ]# cd /etc/yum.repos.d
[root@localhost yum.repos.d]# vim mongodb-org-4.2.repo
[mngodb-org]
name=MongoDB Repository
baseurl=http://mirrors.aliyun.com/mongodb/yum/redhat/7Server/mongodb-org/4.2/x86_64/
gpgcheck=0
enabled=1
这里可以修改 gpgcheck=0, 省去gpg验证
安装之前先更新所有包 :
[root@localhost yum.repos.d]# yum update
2.安装MongoDB
安装命令:
[root@localhost yum.repos.d]# yum -y install mongodb-org
安装完成后
查看mongo安装位置 whereis mongod
[root@localhost yum.repos.d]# whereis mongod
mongod: /usr/bin/mongod /etc/mongod.conf /usr/share/man/man1/mongod.1
查看修改配置文件 :vim /etc/mongod.conf
bindIp: 172.0.0.1 改为 bindIp: 0.0.0.0
(注意冒号与ip之间需要一个空格)
[root@localhost yum.repos.d]# cat /etc/mongod.conf
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
# Where and how to store data.
storage:
dbPath: /var/lib/mongo
journal:
enabled: true
# engine:
# wiredTiger:
# how the process runs
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
# network interfaces
net:
port: 27017
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
#security:
#operationProfiling:
#replication:
#sharding:
## Enterprise-Only Options
#auditLog:
#snmp:
3.启动MongoDB
启动mongodb :systemctl start mongod.service
停止mongodb :systemctl stop mongod.service
查到mongodb的状态:systemctl status mongod.service
设置开启自启动:systemctl enable mongod.service
[root@localhost yum.repos.d]# systemctl status mongod.service
● mongod.service - MongoDB Database Server
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2020-04-04 16:01:31 CST; 8s ago
Docs: https://docs.mongodb.org/manual
Process: 5492 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)
Process: 5488 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 5485 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)
Process: 5481 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)
Main PID: 5495 (mongod)
CGroup: /system.slice/mongod.service
└─5495 /usr/bin/mongod -f /etc/mongod.conf
Apr 04 16:01:30 localhost.localdomain systemd[1]: Starting MongoDB Database Server...
Apr 04 16:01:30 localhost.localdomain mongod[5492]: about to fork child process, waiting until server is ready for connections.
Apr 04 16:01:30 localhost.localdomain mongod[5492]: forked process: 5495
Apr 04 16:01:31 localhost.localdomain mongod[5492]: child process started successfully, parent exiting
Apr 04 16:01:31 localhost.localdomain systemd[1]: Started MongoDB Database Server.
4.外网访问需要关闭防火墙
CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙。
关闭firewall:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
vim /etc/sysconfig/iptables
iptables文件添加
-A INPUT -m state --state NEW -m tcp -p tcp --dport 27017 -j ACCEPT
(注意:-A INPUT -m state --state NEW -m tcp -p tcp --dport 27017 -j ACCEPT要加在-A INPUT -j REJECT --reject-with icmp-host-prohibited之前,不然启动无效)
3 MongoDB的图形化管理软件——Robo 3T
MongoDB虽然自带了一个终端环境下的客户端,但是操作起来比较繁琐,数据显示也不够直观,因此需要使用一个图形界面管理软件来提高MongoDB数据的可读性。
3.1 安装
Robo 3T是一个跨平台的MongoDB管理工具,采用图形界面查询或者修改MongoDB。Robo 3T的下载地址为:https://robomongo.org/download。在下载页面中可以看到另一个叫作 Studio 3T 的软件,它是一个功能更加强大的MongoDB图形化管理软件,但它是一个商业软件,需要收费,而Robo 3T是开源软件并且免费,它的功能足够应付本书的所有应用场景,因此本文选择使用Robo 3T。
- (1)安装Robo 3T的安装没有任何需要特别说明的地方,和安装普通软件一样简单
image.png
- (2)第一次成功启动Robot 3T时,会看到一个用户协议,如图所示,勾选“我接受”按钮
image.png
-
(3)选择需要安装的路径,然后点击安装即可
-
(4)在下一个界面中添加名字公司之类的信息,可以直接忽略,单击“完成”按钮跳过即可
3.2 用Robo 3T连接MongoDB
- (1)打开Robo 3T,看到如图所示对话框,单击左上角“Create”链接。
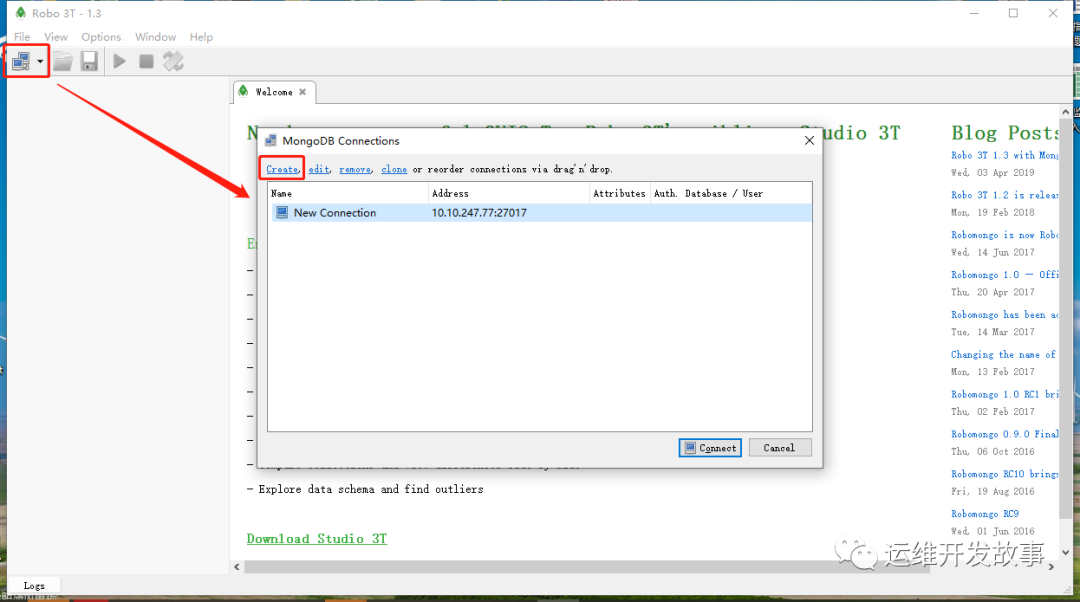
image.png
- (2)弹出如图所示对话框。如果MongoDB就在本地电脑中运行,则只需在“Name”栏中填写一个名字,其他地方不需要修改,然后直接单击“Save”按钮
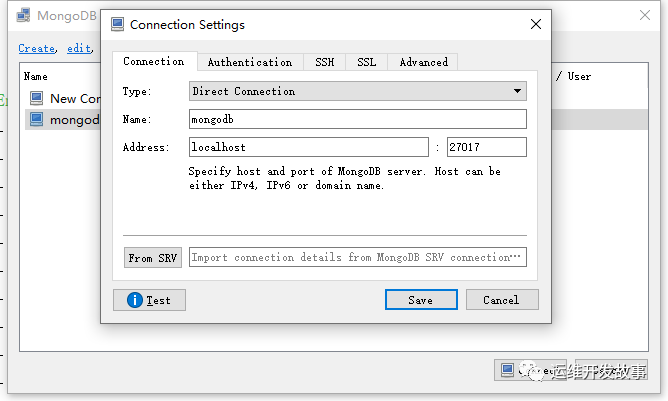
image.png
- (3)保存回到界面后,单击“Connect”按钮就可以连接MongoDB了
3.3 认识Robo 3T的界面
Robo 3T的主界面如图所示。重点关注A、B、C三个区域
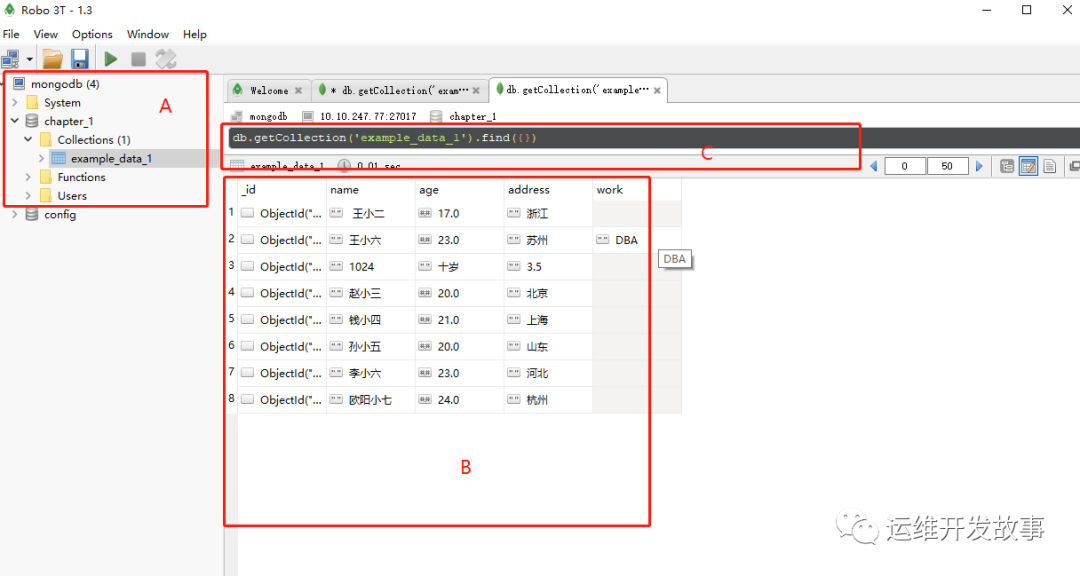
image.png
-
数据库列表区(后简称A区域),用于选择数据库和集合。
-
数据展示区(后简称B区域),用于显示数据。
-
命令执行区(后简称C区域),用于编写MongoDB代码。
在A区域中,单击数据库图标左边的箭头,展开数据库;单击“Collections”左边的箭头,展开集合。双击集合的名字,则B区域和C区域发生相应的变化。
4 MongoDB的基本操作
增、查、改、删是所有数据库必备的功能。本节将介绍如何使用MongoDB 来实现这四个功能
4.1 创建数据库与集合,写入数据
在Robo 3T中进行如下操作:
-
(1)创建一个名为“chapter_1”的数据库,以及其中的多个集合
-
(2)往集合里逐条插入数据
-
(3)往集合里批量插入数据
使用Robo 3T打开刚刚安装完成的MongoDB,可以看到A区域是空的,还没有数据库,如图所示:
image.png
1.创建数据库与集合
-
(1)鼠标右击“小电脑”图标,在弹出的菜单中选择“CreateDatabase”命令
-
(2)在弹出的对话框中输入数据库的名字,单击“Create”按钮完成数据库的创建
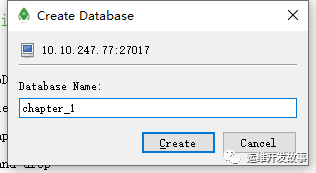
-
(3)新创建的数据库会出现在 A 区域中。单击数据库左边的小箭头将其展开,然后右击“Collections(0)”文件夹,在弹出的菜单中选择“Create Collection…”命令
-
(4)在弹出的对话框中输入集合的名字,然后单击“Create”按钮,创建一个集合。
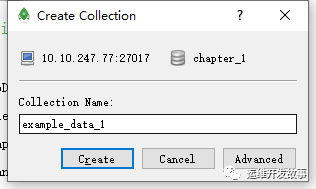
- (5)创建完集合后,原来的“Collections(0)”变成了“Collections(1)”。由此可以推测:括号里面的数字表示这个数据库里面有多少个集合。单击“Collections(1)”左侧的小箭头将其展开,可以看到集合“example_data_1”已经创建好了。双击集合名字,可以看到当前集合里什么都没有,如图所示:
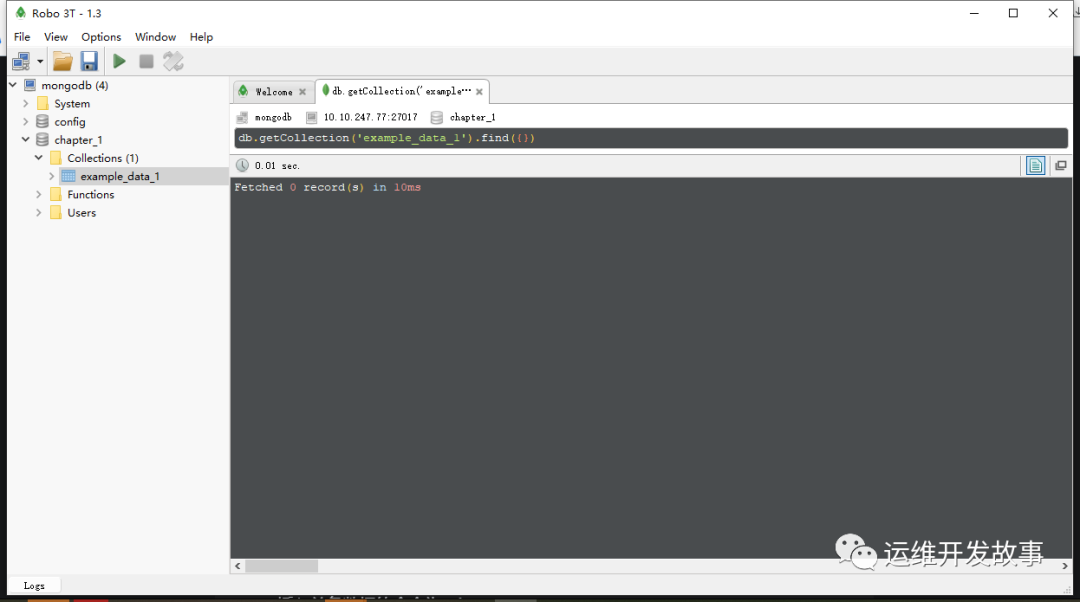
image.png
2.插入单条数据
插入单条数据的命令为“insertOne()”,Robo 3T自带插入数据的功能,但是在此不介绍了,本文会直接介绍如何在C区域执行MongoDB命令插入数据。
(1)创建一条JSON字符串
例如:
{“name”: “王小二”, “age”: 17, “address”: “浙江”}
(2)对C区域的内容做一些修改
原来是:
db.getCollection(‘example_data_1’).find({})
修改为:
db.getCollection(‘example_data_1’).insertOne({“name”: " 王小二 ",“age”: 17,“address”: “浙江”})
(3)使用Windows与Linux的读者,可以按键盘上的“Ctrl + R”组合键,运行后的界面如图所示。可以看到,一条数据已经插入到了MongoDB中
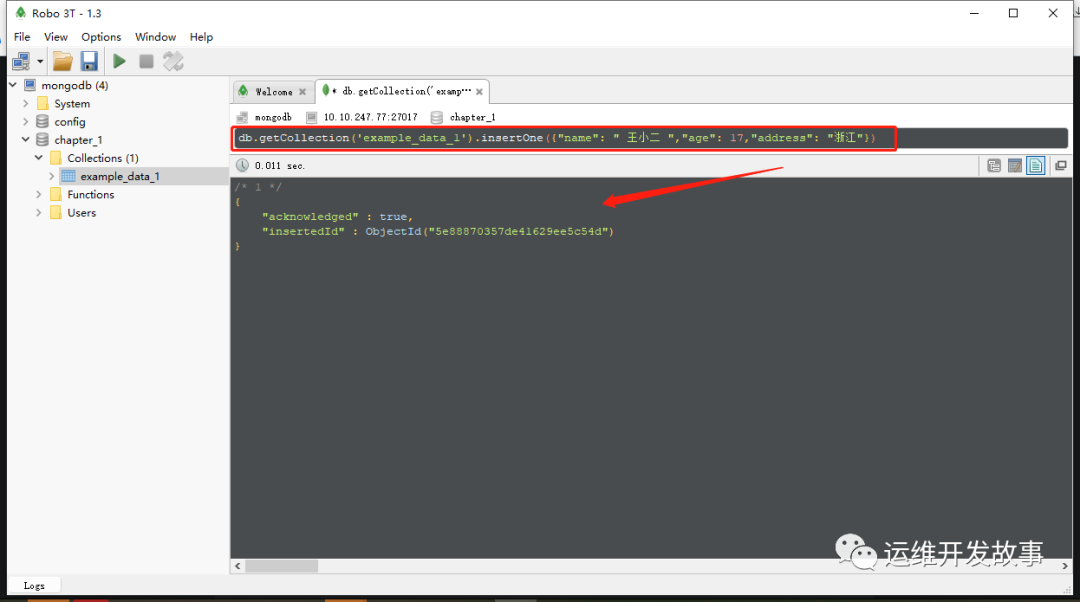
image.png
提示:还可以通过单击Robo 3T上面的绿色三角形来运行命令
- (4)在 A 区域双击集合“example_data_1”,从新打开的选项卡中可以看到数据已经成功插入,如图所示:
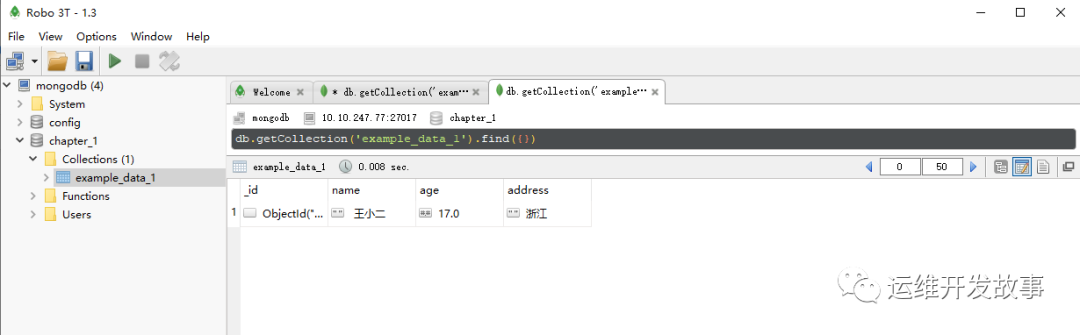
image.png
数据已经成功插入被插入的数据就是JSON字符串:
{“name”: “张小二”, “age”: 17, “address”: “浙江”}
提示:JSON字符串必须使用双引号,不过这个规定在MongoDB中并非强制性的,用单引号也没有问题。例如,在C区域执行以下命令:
db.getCollection(‘example_data_1’).insertOne({‘name’: ‘王小六’,‘age’: 23, ‘work’: ‘运维工程师’})
如果将Python的字典直接复制到MongoDB的insertOne命令中,则绝大部分情况下这些字典都可以直接使用,只有极少数情况下需要做一些修改,后面会讲到这些少数情况
提示:MongoDB还允许Key不带引号,直接写成
{name: ‘王小六’, age: 23,work: ‘运维工程师’}
但这种写法存在一些局限性,并且会导致MongoDB的命令不方便平滑移植到Python中。因此,建议读者一律使用带单引号的写法或者带双引号的写法
3.调整插入的字段
- (1)任意修改、添加、删除字段。在现有的数据中,第1条数据没有“work”这个字段,第2条数据没有“address”这个字段。这就说明:在MongoDB里,插入数据的字段是可以任意修改、添加、删除的。例如,再插入一条新的数据:
db.getCollection('example_data_1').insertOne({"hello": "world","sex": "男","职位": "程序员"})
这一次所有的字段都和前两条数据不一样,但 MongoDB 仍然可以轻松处理——遇到新来的字段,加上去就是了,没什么大不了的,如图所示:
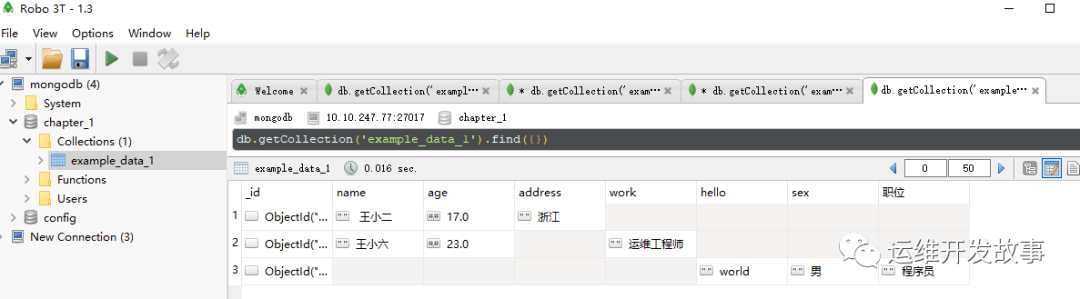
image.png
- (2)插入同一个字段,但格式却不同,即使是同一个字段,其数据格式也可以不一样
例如,再插入一条数据:
db.getCollection('example_data_1').insertOne({"name": "1024","age": "十岁","address": "3.5"})
添加后的数据如图所示:
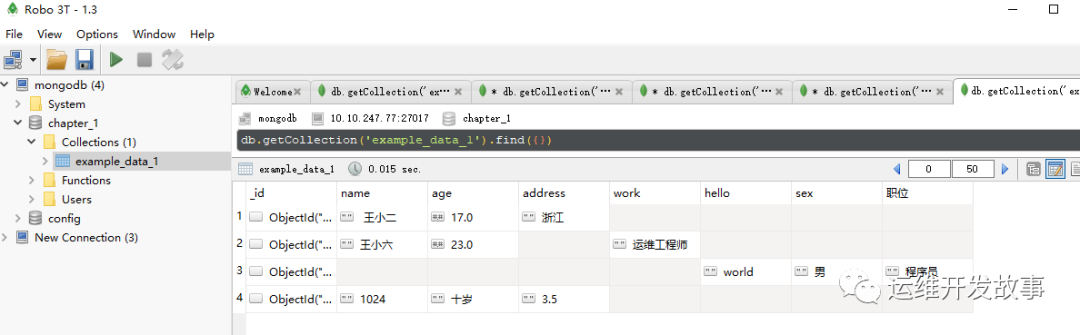
image.png
提示:“能不能做”是一回事,“应不应该做”是另一回事。虽然MongoDB能够处理同一个字段的不同数据类型,也可以随意增减字段,但并不意味着应该这样做。在设计数据库时,应尽量保证同一个字段使用同一种类型的数据,并提前考虑好应该有哪些字段。
3.批量插入数据
批量插入数据的命令是“insertMany”,把一个包含很多个字典的列表传给“insertMany”。
列表为:
data_list = [
{'name': '赵小三','age':20,'address':'北京'},
{'name': '钱小四','age':21,'address':'上海'},
{'name': '孙小五','age':20,'address':'山东'},
{'name': '李小六','age':23,'address':'河北'},
{'name': '欧阳小七','age':24,'address':'杭州'},
]
对应的MongoDB批量插入语句为:
db.getCollection('example_data_1').insertMany([
{'name': '赵小三','age':20,'address':'北京'},
{'name': '钱小四','age':21,'address':'上海'},
{'name': '孙小五','age':20,'address':'山东'},
{'name': '李小六','age':23,'address':'河北'},
{'name': '欧阳小七','age':24,'address':'杭州'}
])
运行后返回的数据如图所示:
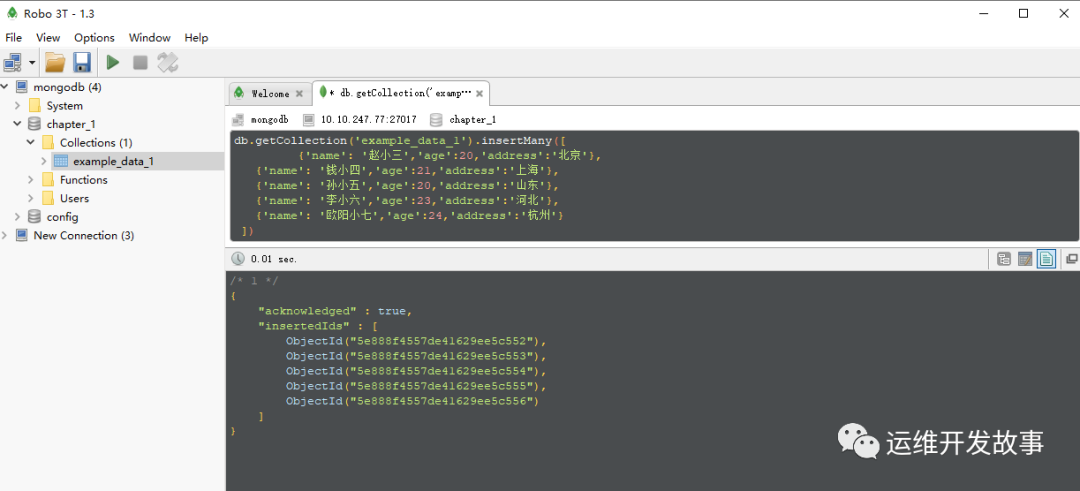
image.png
提示:可以通过换行和缩进让代码更美观、易读。换行和缩进不影响代码功能
运行以后的集合数据如图所示:
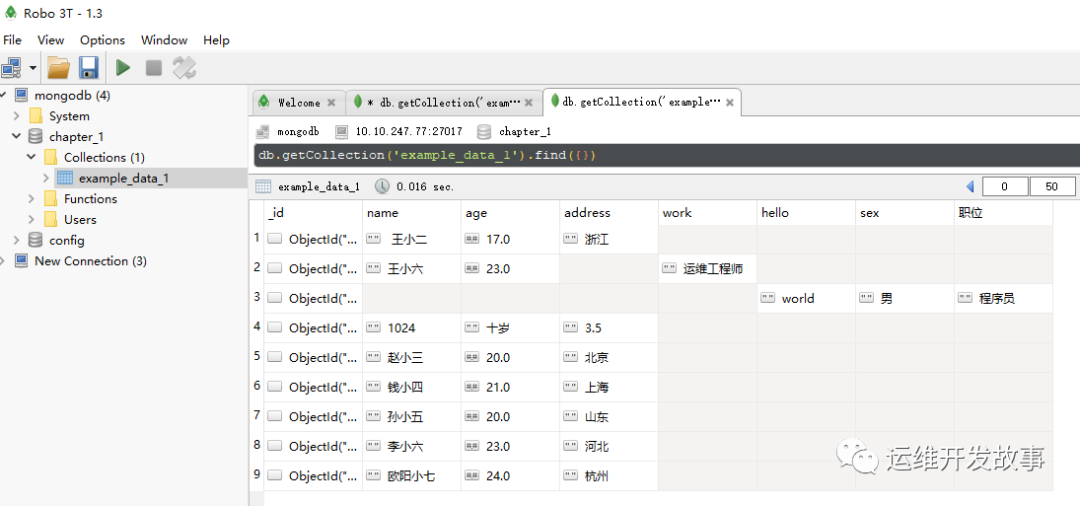
image.png
无论是插入一条数据还是插入多条数据,每一条数据被插入 MongoDB后都会被自动添加一个字段“_id”。“_id”读作“Object Id”,它是由时间、机器码、进程pid和自增计数器构成的。“_id”始终递增,但绝不重复。
● 同一时间,不同机器上面的“_id”不同
● 同一机器,不同时间的“_id”也不同
● 同一机器同一时间批量插入的数据,“_id”依然不同
提示:_id的前8位字符转换为十进制就是时间戳。例如“5b2f2e24e0f42944105c81d2”,前8位字符“5b2f2e24”转换为十进制就是时间戳“1529818660”,对应的北京时间是“2018-06-2413:37:40”
4.2 查询数据
对数据集example_data_1进行如下查询:
(1)查询所有数据
(2)查询特定数据:查询“age”为25岁的员工
(3)查询特定数据:查询“age”不小于25的所有记录
(4)限定返回的数据字段类型
在Robo 3T中双击集合名字,实际上是自动执行了以下这条查询语句:
db.getCollection(‘example_data_1’).find({})
下面先来了解一下查询结果的三种显示模式
1.三种显示模式
Robo 3T显示出来的查询结果如图所示,注意右上角方框框住的三个图标。
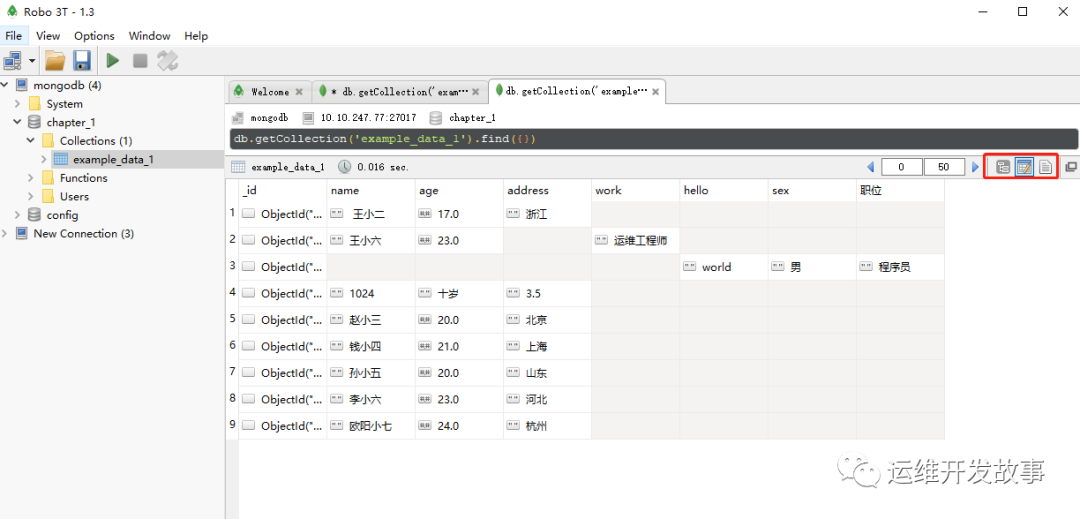
image.png
Robo 3T对于返回的数据有三种组织方式,从左到右分别是:“树形模式(Tree Mode)”“表格模式(Table Mode)和“文本模式(TextMode)”。
提示:这三种显示模式是Robo 3T提供的,不是MongoDB的功能。
2.查询固定值数据
-
(1)查询所有数据。如要查询所有数据值,则直接使用下面两种写法的任意一种即可:
db.getCollection(‘example_data_1’).find()
或
db.getCollection(‘example_data_1’).find({})
- (2)查询特定数据。如要查询某个或者某些具体字段,则可以使用下面的语法来查询。如果有多个字段,则这些字段需要同时满足。
例如,对于数据集 example_data_1,要查询所有“age”字段为25的记录。则查询语句可以写为:```
db.getCollection('example_data_1').find({'age': 23})
查询结果如图所示:
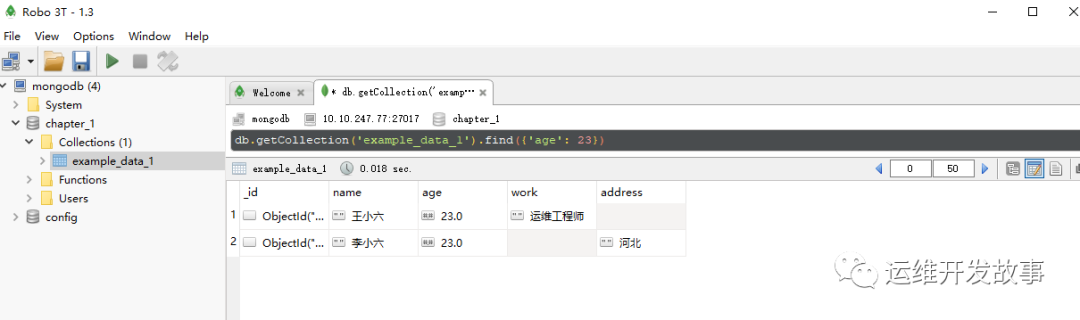
image.png
由于“age”为25的记录有两条,于是需要进一步缩小查询范围——再增加一个限制条件:
db.getCollection('example_data_1').find({'age': 23,'name':'王小六'})
运行结果如图所示:
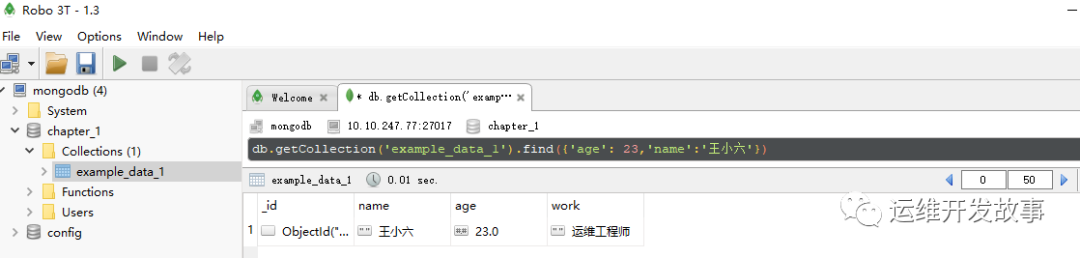
image.png
总结一下,“find”的参数相当于一个字典。字典的 Key 就是字段名,字典的值就是要查询的值。如果字典有多个Key,则这些字段需同时满足。
3.查询范围值数据
如要查询的字段值能够比较大小,则查询时可以限定值的范围,例如,对数据集example_data_1,要查询所有“age”字段不小于25的记录,则需要使用大于等于操作符“$gte”。查询语句如下:
db.getCollection('example_data_1').find({'age': {'$gte': 23}})
运行效果如图所示:
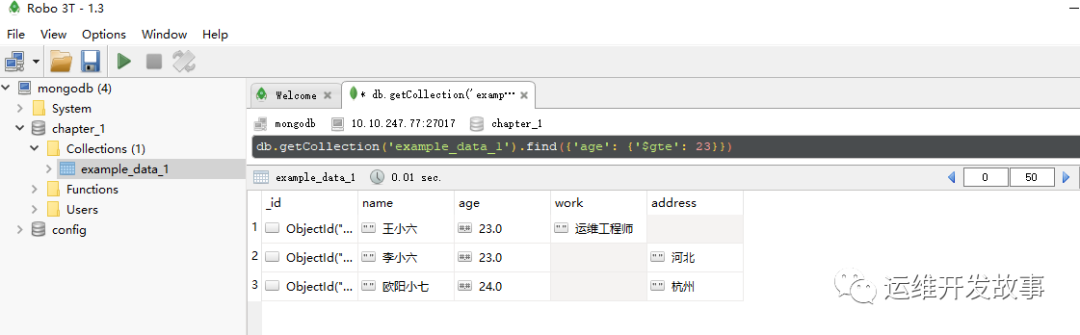
image.png
查询某个范围的数据会用到的操作符见下表:
| 操作符 | 含义 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
使用范围操作符的查询语句格式如下:
db.getCollection('example_data_1').find({'age': {'操作符1': 边界1,'操作符2': 边界2}})
可以看出,在使用范围操作符后,原本填写被查询值的地方现在又变成了一个字典。这个字典的Key是各个范围操作符,而它们的值是各个范围的边界值。
【举例1】查询所有“age”大于21并小于等于24的数据,查询语句如下:
db.getCollection('example_data_1').find({'age': {'$lt': 24, '$gt': 21}})
【举例2】查询所有“age”大于21并小于等于24的数据,且“name”不为“夏侯小七”的记录
db.getCollection('example_data_1').find({
'age': {
'$lt': 24,
'$gt': 21
},
'name':{'$ne':'欧阳小七'}
})
4.限定返回哪些字段
“find”命令可以接收两个参数:第1个参数用于过滤不同的记录,第2个参数用于修改返回的字段,如果省略第2个参数,则MongoDB会返回所有的字段。如要限定字段,则查询语句的格式如下:
db.getCollection('example_data_1').find(用于过滤记录的字典,用于限定字段的字典)
其中,用于限定字段的字典的Key为各个字段名。其值只有两个——0或1。
● 如果值为0,则表示在全部字段中剔除值为0的这些字段并返回。
● 如果值为1,则表示只返回值为1的这些字段。
例如,查询数据集example_data_1,但不返回“address”和“age”字段,查询语句如下:
db.getCollection('example_data_1').find({}, {'address': 0, 'age': 0})
运行结果为如图所示:
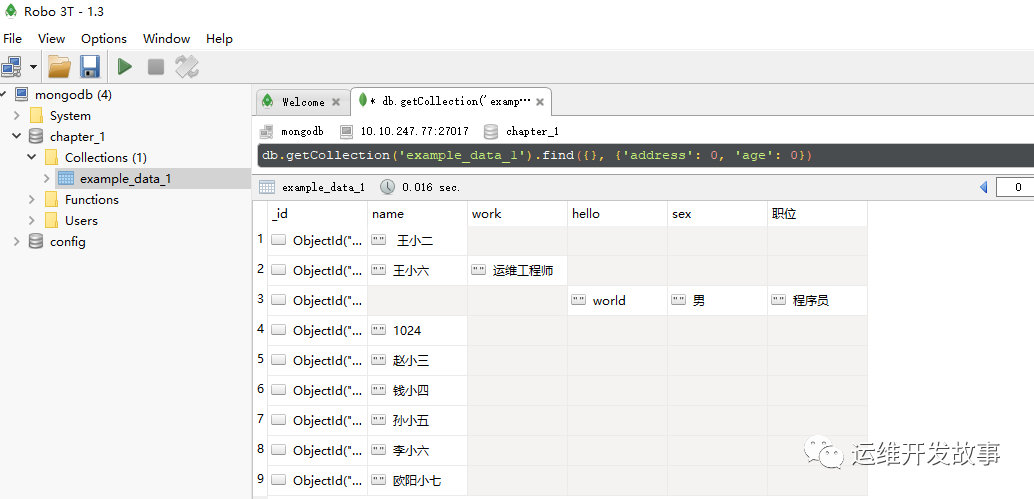
image.png
再例如,要求只返回name字段和age字段,则查询语句如下:
db.getCollection('example_data_1').find({}, {'name': 1, 'age': 1})
运行效果如所示:
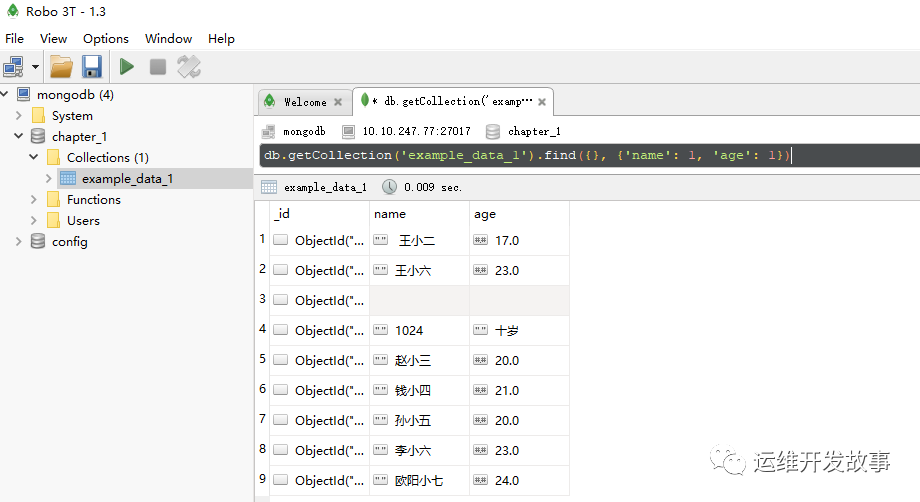
image.png
可能已经发现,不论是选择“只返回某些字段”还是“不返回某些字段”,结果里始终有“_id”。这是因为,“_id”比较特殊,它是默认要返回的,除非明确说明不需要它。即,如果不想要“_id”,则必须在限定字段的字典中把“_id”字段的值设为0,如图所示:
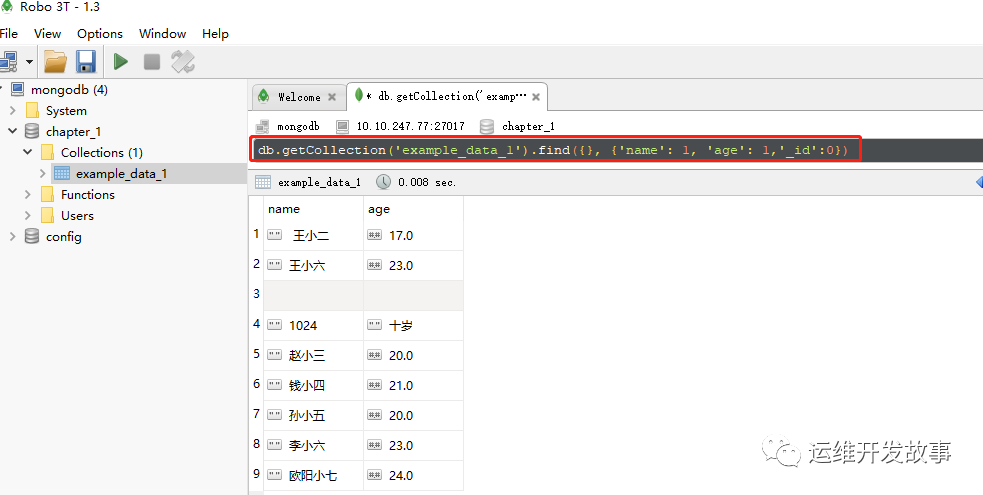
image.png
如果不考虑“_id”,则限定字段的字典里面的值只可能全都是0或全都是1,不可能1和0混用,一旦混用则MongoDB就会报错。这从逻辑上很好理解:
(1)如果只要A、B、C,则没有提到的自然都是不需要的
(2)如果除A、B、C外其他的全都要,则没有提到的自然全都是需要的
提示:只有“_id”很特别,不论其他字段的值是0还是1,如果不需要返回“_id”,则需要把它的值设为0
5.修饰返回结果
- (1)满足要求的数据有多少条——count()命令
如果想知道满足要求的数据有多少条,则可以使用“count()”命令。例如,要查询所有“age”字段大于21的记录有多少条,则查询语句如下:
db.getCollection('example_data_1').find({'age': {'$gt': 21}}).count()
运行结果如图所示。返回数字“3”表示有3条记录满足要求
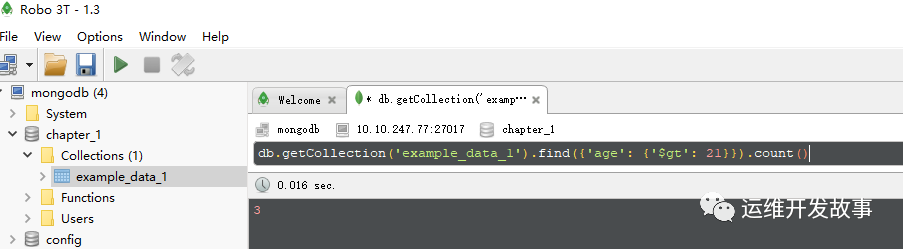
image.png
- (2)限定返回结果——“limit()”命令
如果查询的结果非常多,则可能需要限定返回结果。此时就需要使用“limit()”命令。它的用法如下:
db.getCollection('example_data_1').find().limit(限制返回的条数)
● 如果限制返回的条数为一个数字,则表示最多返回这么多条记录。如果超过限定条数,则只返回限定的条数
● 如果不足限定的条数,则有多少就返回多少。例如,对于数据集example_data_1,限制只返回4条数据。具体命令如下:
db.getCollection('example_data_1').find().limit(4)
运行效果如图所示:
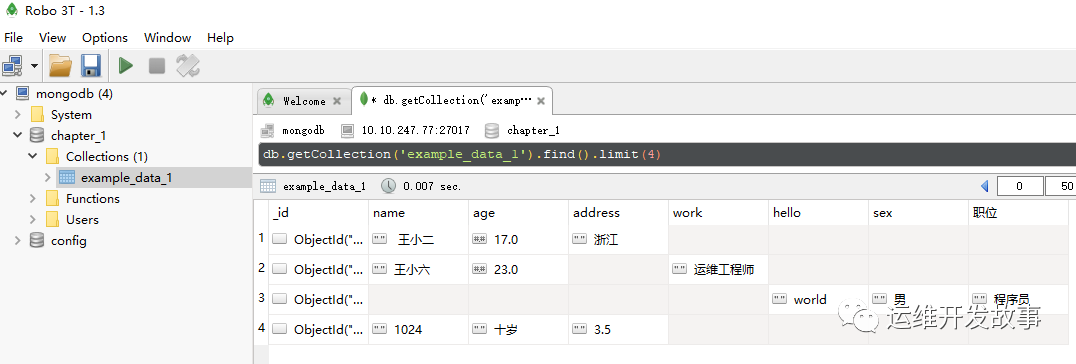
image.png
- (3)对查询结果进行排序——“sort()”命令
有时也需要对查询结果进行排序,此时需要使用“sort()”命令。使用方法如下:
db.getCollection('example_data_1').find({'age': {'$gt':21}}).sort({'字段名': -1或者1})
其中,字段的值为-1表示倒序,为1表示正序。例如,对所有“age”大于21的数据,按“age”进行倒序排列。查询语句如下:
db.getCollection('example_data_1').find({'age': {'$gt':21}}).sort({'age': -1})
运行如下:
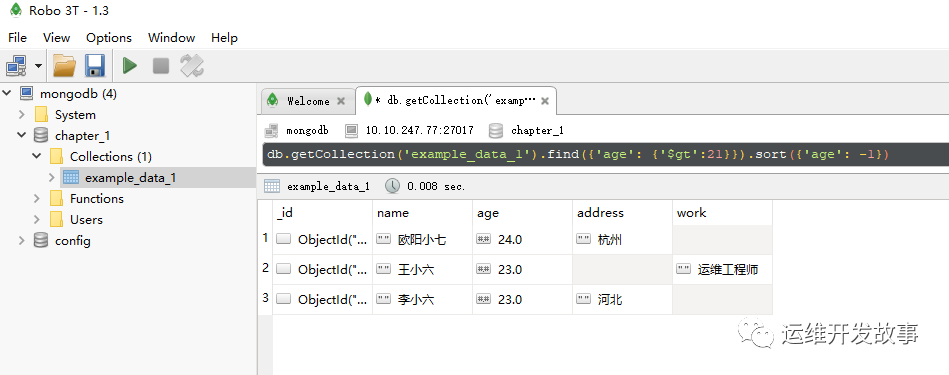
image.png
4.3 修改数据
实例描述数据集 example_data_1,“name”为“王小六”的这个记录是没有“address”字段的。现在需要为它增加这个字段,同时把“work”从“运维工程师”改为“DBA”。
(1)更新集合中的单条数据。
(2)批量更新同一个集合中的多条数据。
修改操作也就是更新(Update)操作,对应的 MongoDB 命令为“updateOne()”和“updateMany()”。
这两个命令只有以下区别,它们的参数完全一致。
● updateOne:只更新第1条满足要求的数据
● updateMany:更新所有满足要求的数据
下面以“updateMany”为例来介绍更新记录的操作。
1.更新操作的语法
db.getCollection('example_data_1').updateMany(
参数1:查询语句的第一个字典,
{'set':{'字段1':'新的值1','字段2','新的值2'}}
)
updateMany的第1个参数和“find”的第1个参数完全一样,也是一个字典,用来寻找所有需要被更新的记录。第2个参数是一个字典,它的Key为“$set”,它的值为另一个字典。这个字典里面是需要被修改的字段名和新的值。
举例:
修改“name”为“王小六”的文档,添加“address”字段,并“work”从“运维工程师”改为“DBA”
db.getCollection('example_data_1').updateMany(
{'name':'王小六'},
{'$set':{'address':'苏州','work':'DBA'}}
)
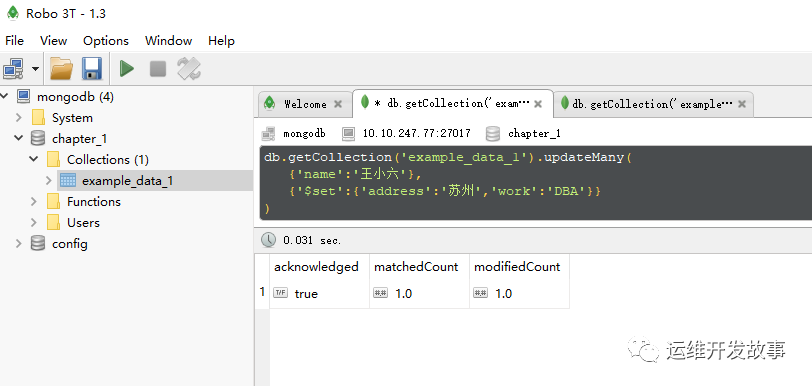
image.png
再次查看数据集,发现“王小六”的信息已经发生了变化,如图所示:
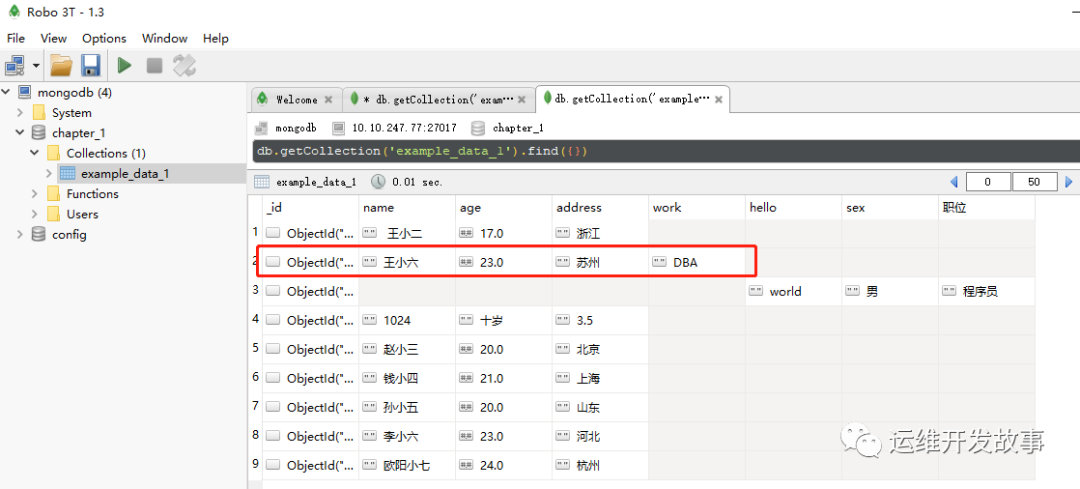
image.png
4.4 删除数据
例如,要从数据集example_data_1中删除字段“hello”值为“world”的这一条记录。
(1)从集合中删除单条数据
(2)从集合中批量删除多条数据
只要会查询数据,就会删除数据。为了防止误删数据,一般的做法是先查询要删除的数据,然后再将查出的数据删除
- (1)查询字段“hello”中值为“world”的这一条记录
具体如下:
db.getCollection('example_data_1').find({'hello': 'world'})
db.getCollection(‘example_data_1’).find({‘hello’: ‘world’})
运行效果如图所示:
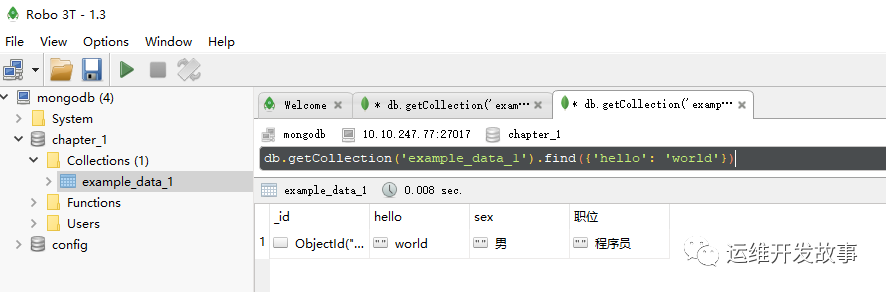
image.png
- (2)把查询语句的“find”修改为“deleteOne”(如果只删除第1条满足要求的数据),或把查询语句的“find”修改为“deleteMany”(如果要删除所有满足要求的数据)
具体命令如下:
db.getCollection('example_data_1').deleteMany({'hello': 'world'})
-
(3)在返回的数据中,“acknowledged”为“true”表示删除成功,“deletedCount”表示一共删除了1条数据
-
(4)再次查询example_data_1,发现已经找不到被删除的数据了
提示:慎用删除功能。一般工程上会使用“假删除”,即:在文档里面增加一个字段“deleted”,如果值为0则表示没有删除,如果值为1则表示已经被删除了。默认情况下,deleted字段的值都是0,如需要执行删除操作,则把这个字段的值更新为1。而查询数据时,只查询deleted为0的数据。这样就实现了和删除一样的效果,即使误操作了也可以轻易恢复
4.5 数据去重
在数据集example_data_1中,进行以下两个去重操作。
(1)对“age”字段去重
(2)查询所有“age”大于等于24的数据,再对“age”进行去重。去重操作用到的命令为“distinct()”
格式如下:
db.getCollection('example_data_1').distinct('字段名', 查询语句的第一个字典)
distinct()可以接收两个参数:
-
第1个参数为字段名,表示对哪一个字段进行去重。
-
第2个参数就是查询命令“find()”的第1个参数。distinct命令的第2个参数可以省略
1.对“age”字段去重对“age”字段去重的语句如下:
db.getCollection('example_data_1').distinct('age')
运行效果如图所示:
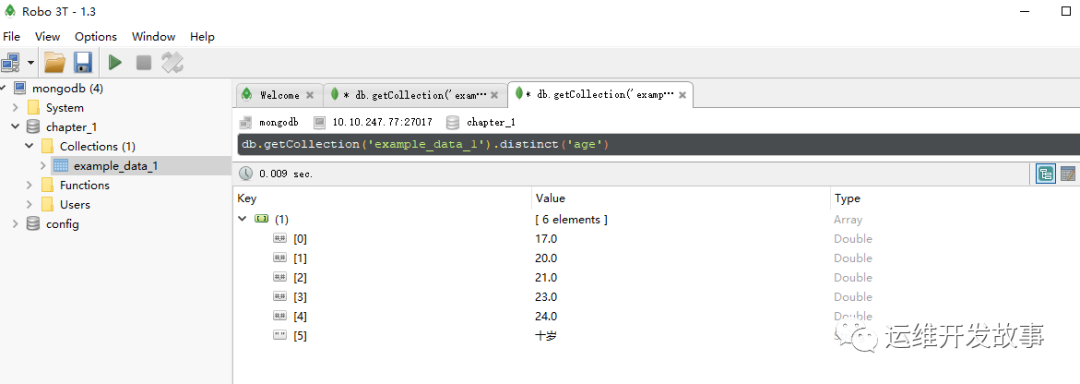
image.png
在MongoDB中返回的数据是一个数组,里面是去重以后的值。
2.对满足特定条件的数据去重首先查询所有“age”大于等于20的数据,然后对“age”进行去重。
db.getCollection('example_data_1').distinct(
'age',
{'age':{'$gte':20}}
)
运行结果:
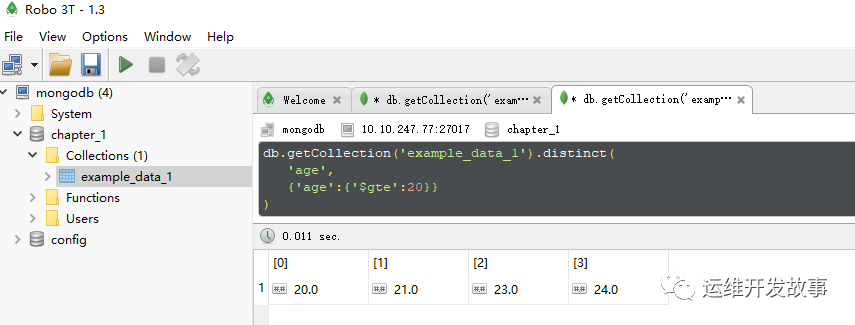
image.png
提示:能否去重以后再带上其他字段呢?答案是,用“distinct()”命令不能实现。要实现这个功能,后面介绍
后面会更新如何使用Python操作MongoDB,请持续关注
公众号:运维开发故事
github:https://github.com/orgs/sunsharing-note/dashboard
作者:double冬 运维开发故事
欢迎关注:运维开发故事

 分类导航
分类导航