

 个人中心
个人中心 退出
退出




图像优化原理,原来这么简单
我们都喜欢有图片的网页,图片很美好,很有趣,同时它涵盖了丰富的信息。所以,在加载网页时,大部分流量被图像资源所占据(平均60%,数据可能不准确)。
图像资源不只占用网络资源,它也会占用网页中大量的视觉空间。所以图像渲染的速度会直接影响用户体验。图像优化其实就是最大限度地减少图像的字节数,从而最大化地缩减网络资源占用,使浏览器下载速度变的更快。下载速度越快,在屏幕上渲染的时间就越早,所以视觉上就会有一个更好的体验。
当然,优化图像最佳的方式就是不用图像,例如使用CSS效果(渐变,阴影,圆角等)代替图像。使用CSS比同等视觉效果的图像资源的字节数要小非常多,这是毋庸置疑的。另一个好处是CSS不受分辨率影响,使用CSS渲染出的视觉效果可以在任何分辨率和缩放级别下始终清晰地显示。
但必须使用图像资源时,对图像进行合理的优化将对性能有着至关重要的影响。
本文不会介绍如何进行图像优化,有大量在线工具和开源项目供我们使用,使用起来非常的简单。本文将重点介绍图像优化的原理。
首先,本文会介绍两种图像资源:矢量图与栅格图(位图),并分别介绍优化它们的原理。随后介绍无损压缩与有损压缩以及它们的区别。在本文的最后,我们会介绍什么是高分辨率屏幕。
希望通过本篇文章的介绍,可以让您对图像优化的原理有一个直观的感受。
1. 矢量图与栅格图(位图)
矢量图与栅格图(位图)是两种不同的图像格式。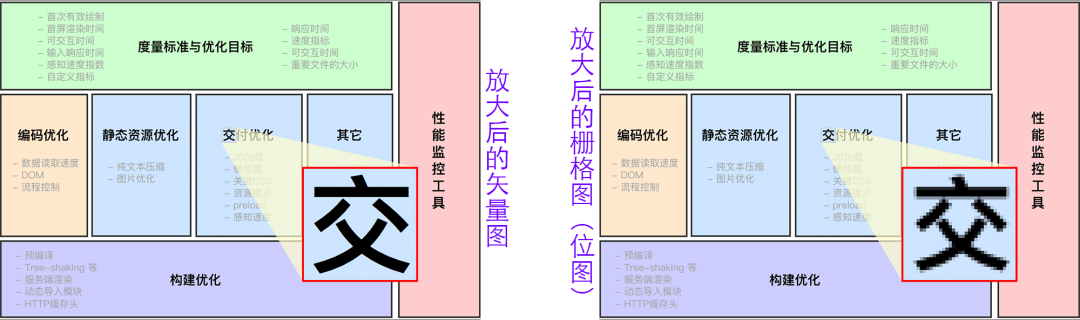
图1-1 矢量图与栅格图
矢量图形是计算机图形学中用点、直线或者多边形等基于数学方程的几何图元表示图像。
栅格图(英语:Raster graphics),又称位图(Bitmap)或点阵图,是使用像素阵列(Pixel-array/Dot-matrix点阵)来表示的图像。
以矢量图为例,程序绘制一个半径为r的圆所需的主要信息是:
半径r
圆心坐标
轮廓样式与颜色(可能是透明)
填充样式与颜色(可能是透明)
矢量图的内容是这些绘制相关的关键信息,同样的图像如果是栅格图(位图),则图像是由称作像素的单个点组成的。
栅格图的每个像素都分配有特定的位置和颜色值。每个像素的颜色信息由RGB组合或者灰度值表示。
根据位深度,可将栅格图分为1、4、8、16、24及32位图像等。每个像素使用的信息位数越多,可用的颜色就越多,颜色表现就越逼真。当然,相应的数据量就越大,图像所占字节数也就越大。
那什么是位深度呢?位深度也叫做色彩深度或者色彩位数,即栅格图中要用多少个二进制位来表示每个点的颜色,色彩深度越高,每个像素点可用的颜色就越多。色彩深度是用“n位颜色”(n-bit colour)来说明的。若色彩深度是n位,即有2^n种颜色选择,而储存每像素所用的位数就是n。例如,位深度为 1 的像素栅格图只有两个可能的值(黑色和白色),所以又称为二值栅格图。位深度为 8 的图像有 2^8(即 256)个可能的值。
所以矢量图对比栅格图的优点主要在以下几点:
保存最少的信息,文件字节数比栅格图小,且文件大小与物体的大小无关
任意放大矢量图形,不会丢失细节或影响清晰度,因为矢量图形是与分辨率无关的
在放大的时候,直线与曲线都不会成比例地变粗,它只会保持不变或者要小于缩放比例
保存的物体参数可以在后面修改。也就是说物体的运动、缩放、旋转、填充等都不会降低绘制的精度。
但每一种格式都有优缺点,矢量图适用于简单的几何图像,如果是场景复杂的照片,矢量格式就不能满足要求了,因为描述所有形状所需的 SVG 标记量可能高得离谱。即便如此,输出效果可能仍然无法达到“照片级真实感”,所以这种情况使用栅格图显然更合适。
因为栅格图是由很多个像素点组成的,所以当我们放大栅格图时,我们会看到图形会出现锯齿并且模糊不清(因为像素点被放大了),所以我们在使用栅格图时,需要根据不同的屏幕分辨率来保存多个版本的栅格图图像,这样可以提供最佳的用户体验。
现在我们已经了解了什么是矢量图与栅格图,接下来我们将介绍如何优化它们。
2. 优化矢量图
SVG大家应该都不陌生,它是一种可缩放矢量图形。前不久我在写 《嗨,送你一张Web性能优化地图》 这篇文章时,@安佳 姐姐帮我画了一张SVG图。
图2-1 SVG示例图
图2-1您可以通过点击链接在浏览器打开它,然后查看网页源代码,在源码中可以看到它涵盖了大量的元数据,例如图层信息、注解和 XML 命名空间等,而浏览器渲染时通常不需要这些数据。
我们可以通过svgo之类的工具将 SVG 文件缩小。
上面这张图片,我使用svgo优化完之后,文件大小缩减了69.3%!原图16.315 KiB优化后文件大小5.009 KiB。您可以点击链接在浏览器打开优化后的SVG矢量图,并查看网页源代码,对比它们之间的区别,您可以看到源代码明显少了很多,但并不影响浏览器正常渲染。
3. 优化栅格图
通过第一小节的介绍,我们大致可以想象出,其实栅格图是二维“像素”栅格。例如一个10*10像素的图像是 100 个像素序列,而每个像素中又存储了RGBA值(R红色通道、G绿色通道、B蓝色通道、A alpha透明度通道)。
在内部,浏览器会为每个通道分配 256 个值(色阶),就是说每个通道 8 位(因为2^8=256),那么一个像素有四个通道(RGBA),所以每个像素一共 32 位(4 个通道 * 8 位 = 32 位),32 位 = 4 字节,也就是说每个像素 4 占个字节。所以,只要我们知道栅格图尺寸,我们就可以轻易地计算出图像文件的大小。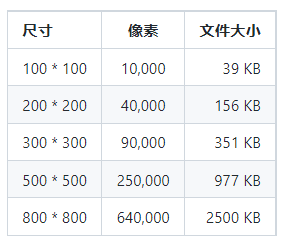
从上表可以看到,随着图片尺寸的变大,文件大小会以惊人的速度暴增。
再基于此特征的前提下,我们应该怎样改善栅格图的文件大小以获得更快的加载速度呢?
在第一小节中,我们简单介绍了”色彩深度“,所以一个简单的策略是我们可以通过调整图像的色彩深度来降低图像文件的大小。每个通道 8 位为每个通道提供 256 个值,RGB三个通道一共可以为每个像素提供 16777216 种颜色(256^3=16777216)。如果我们将色彩深度调整为 RGB 通道一共只需要 8 位,那么加上 Alpha 透明度通道的 8 位,一共为 16 位,也就是说每个像素两个字节(16位 = 2个字节),与原来每个像素 4 个字节相比,节约了 50% 的字节!
但是你一定会有疑问,颜色值少了那么多,图像的质量会不会变得很差?我们可以用一张图来对比一下。
图3-1 不同色彩深度的图片进行对比
这张图是上个月(2018-10)我去参加W3C TPAC会议时在法国让彭星小哥哥帮我拍摄的。这张图包含渐变色过渡的复杂场景(天空),可以看到,调整了色彩深度后,从肉眼上看到的视觉差异并不明显。
在优化了各个像素中存储的数据之后,我们还可以更进一步。事实上,许多图像的相邻像素都具有相似的颜色,压缩程序可以利用这个特征采用“增量编码”的方式对图像进行压缩。在这种编码方式下,并不为每个像素单独存储值,而是存储相邻像素之间的差异,如果相邻像素相同,则增量为“零”,只需存储一位即可。通过存储数据之间的差异,而不是存储数据本身,这样的方式可以大幅减少数据的重复,从而降低文件大小。
当然,图像压缩领域的解决方案还远不止这些,因为图像占据了网络世界中大量的字节,所以好的图像压缩方法具有极大的价值,这一领域学术性很强,我们也没有能力去发明新的算法,但了解这一领域的基本概念还是可以的,例如本文介绍的 RGBA 像素、色彩深度和各种优化方法。
4. 无损压缩与有损压缩
无损数据压缩(Lossless Compression)指数据经过压缩后,信息不受损失,还能完全恢复到压缩前的原样。
那么无损压缩是如何做到保存完整的原始信息的同时降低文件大小的呢?
举个例子:一张图是由100个红点构成,那么正常情况下它会以类似“红点、红点、...(重复97次)...、红点”的格式来存储它(栅格图的存储格式我们在本文的第三小节中介绍过)。为了降低文件大小,我们可以改成用“100个红点”这样的格式来存储这张图片,这样就可以在不失去任何信息的情况下完成压缩,这就是无损压缩。
但如果想保存文件的所有信息,那么无论使用任何压缩方法,文件大小都无法低于一个下界。举个例子:压缩后得到的zip文件会比源文件更小,但一直重复压缩同一个文件并不会让文件大小变成0,因为源文件终究含有一定的数据量。
这个时候,使用有损压缩可以突破这个限制。
因为人的肉眼很难观察到一张高分辨率图像里面的一些细节,所以舍弃这些人类无法察觉的细节,就可以用更小的数据量提供与原始数据相差无几的感官体验(当然也可以更进一步,例如:通过失去一部分可以察觉的细节,来达到更好的压缩率),这就是有损压缩。有损数据压缩又称破坏性资料压缩、不可逆压缩。有损数据压缩是将次要的信息数据舍弃,牺牲一些质量来减少数据量,提高压缩比。
有损压缩的一个优点是在有些情况下,它能够获得比任何已知无损压缩小得多的文件大小,同时又能满足系统的需要。
总结
本文重点介绍了什么是矢量图与栅格图(位图),以及各种图片优化工具是如何优化它们的。
最后,我们还讨论了什么是有损压缩与无损压缩,以及它们之间的区别。
作者:berwin
欢迎关注微信公众号 :前端阳光

 分类导航
分类导航