

 个人中心
个人中心 退出
退出




开源大数据OLAP引擎最佳实践
大家好,我是梦想家Alex ~ 今天给大家分享一篇很不错的文章,通过六个部分来介绍开源大数据OLAP引擎最佳实践。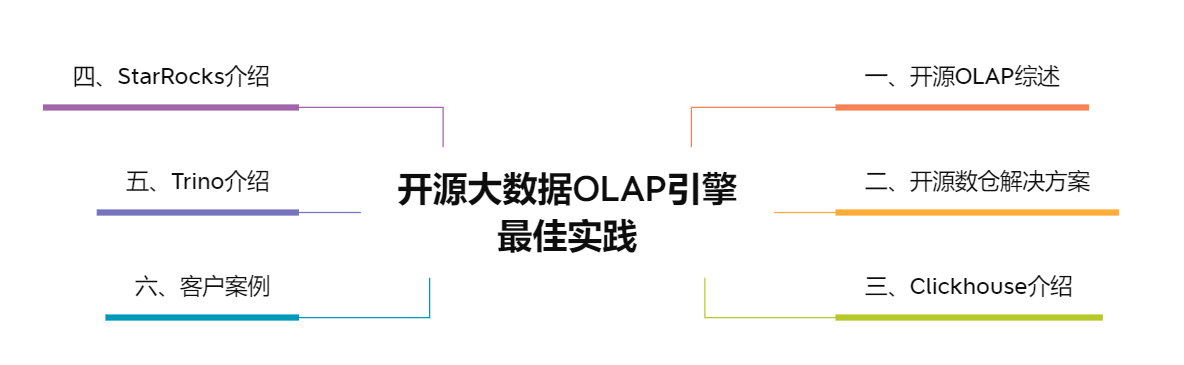
01
开源OLAP综述
如今的开源数据引擎多种多样,不同种类的引擎满足了我们不同的需求。现在ROLAP计算存储一体的数据仓库主要有三种,即StarRocks(DorisDB),ClickHouse和Apache Doris。应用最广的数据查询系统主要有Druid,Kylin和HBase。MPP引擎主要有Trino,PrestoDB和Impala。这些引擎在行业内有着广泛的应用。
02
开源数仓解决方案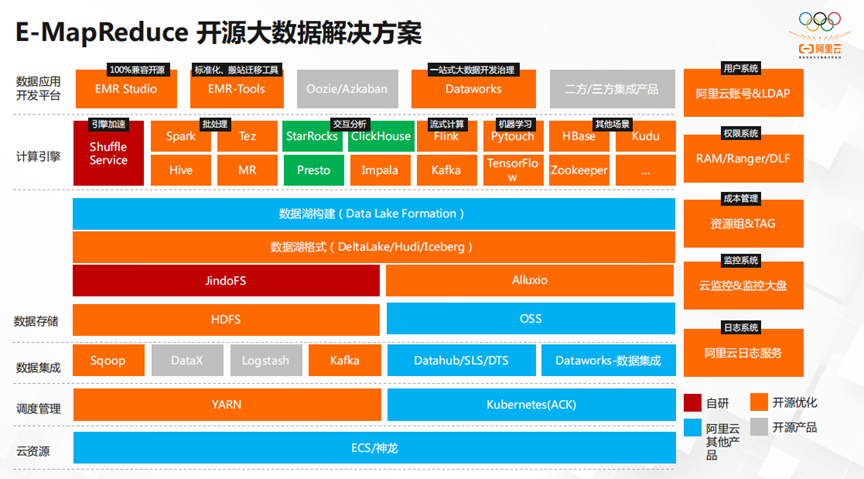
接下来,我们讲讲开源大数据以及数仓的解决方案。上图是EMR的整体架构,在云资源层,主要有ECS。在存储层的JindoFS提供了以OSS为基底的Hadoop接口,不但节约了成本,而且提升了整体的扩展性。数据湖格式有效解决了数据统一管理的难题。其次在计算引擎方面,它具有批处理,流式计算,机器学习和引擎加速等能力。
目前,大家应用最多的离线数仓体系是Lambda架构。该架构主要分为两个部分。
第一部分,在实时方面我们从CDC,ORTP的数据源开始,进行行为数据分析,然后通过Kafka,Flink进行加工。让数据在线系统,可以直接调用API,提升点查效率。其次,当所有聚合的数都导入Olap系统时,运营人员可以快速用它,实现自己新的想法,提升工作效率。
第二部分,在离线方面当需要长久保存数据时,大家都会使用hive。如果没有增量数据库格式,大家一般通过insert overwrite,在detail上做一些数据集市。除此之外,我们通过离线t+1的方式,实现离线数仓的实时数据订正。因为实时数据一般得出的是近似值,离线数据得到的是准确值。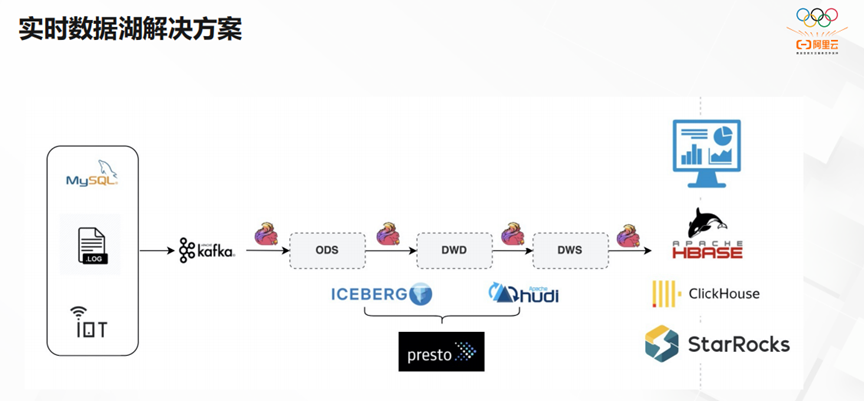
第三部分,实时数据湖的解决方案,其数据量在PB+级别。我们希望统一离线和实时数仓,用一套代码构建业务。数据湖的数据存储在OSS/HDFS,由于我们的部分业务有Upsert变更需求,所以我们希望建设分钟级到小时级的数仓。能够将最热的数据导入StarRocks/CK,OLAP的查询时长保证在500毫秒到2秒之间。与此同时,我们利用Presto查询Hudi/Iceberg/Delta时,其速率能够保证在5秒至30秒之间。
上图是比较传统的实时数仓方案。当每天增量数据达到10TB+,我们希望直接以单软件构建业务底座,让数据先存储在CK/StarRocks,让冷数据转存到OSS。不必再运维Hadoop的庞大体系,极大简化运维操作,可以媲美全托管。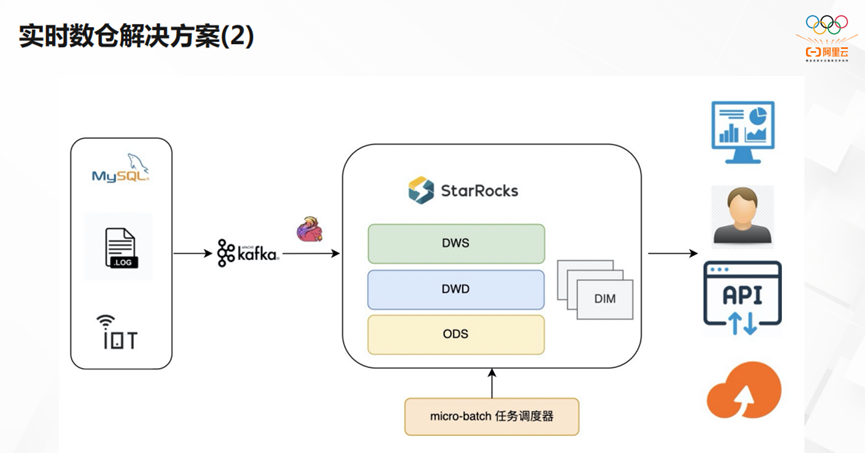
第二种实时数仓的解决方案,我们通过micro-batch任务调度器去处理DWS,DWD和ODS。其实时性非常强,极大简化了开发效率,数据的一致性最高。后续我们将推出存算分离方案,用OSS存储海量数据,用Cache加速热数据。
03
ClickHouse介绍
ClickHouse是面向联机分析处理(OLAP)的开源分析引擎。最初由俄罗斯第一搜索引擎Yandex开发,于2016年开源,开发语言为C++。由于其优良的查询性能,PB级的数据规模,简单的架构,在国内外公司被广泛采用。
它是列存数据库,具有完备的DBMS功能,备份列式存储和数据压缩。它的MPP架构易于扩展,易于维护。除此之外,它支持向量化的查询,完善的SQL以及实时的数据更新,查询速度可以达到亚秒级的响应。
那么ClickHouse的查询速度为什么会这么快呢?它类似于LSM tree,所有数据都是经过有序排列,提前做好聚合计算,再存储。并且它的数据存储格式自带索引。
其次,ClickHouse可以基于多个Key创建索引。它的二级索引采用Data skipping index。
ClickHouse的应用场景主要有四个方面。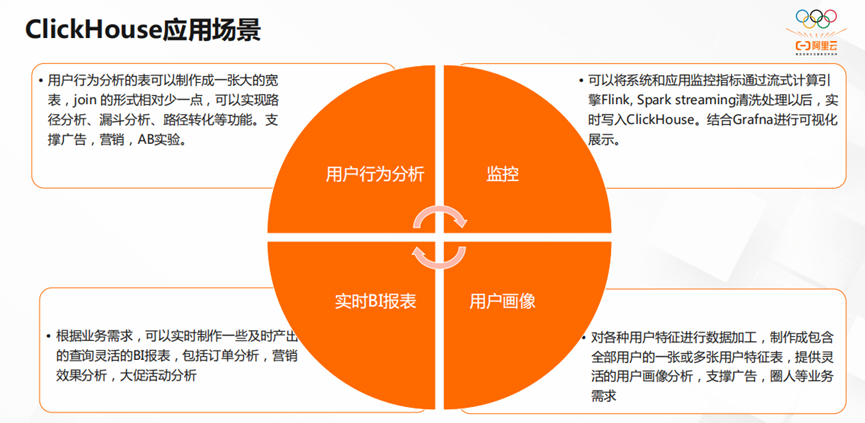
第一,用户行为分析。ClickHouse将用户行为分析表制作成一张大的宽表,减少join的形式,实现路径分析、漏斗分析、路径转化等功能。除此之外,它还能支撑广告,营销和AB实验。
第二,实时BI报表。ClickHouse可以根据业务需求,实时制作及时产出,查询灵活的BI报表,包括订单分析,营销效果分析,大促活动分析等等。
第三,监控。ClickHouse可以将系统和应用监控指标通过流式计算引擎Flink,Spark streaming清洗处理以后,实时写入ClickHouse。结合Grafna进行可视化展示。
第四,用户画像。ClickHouse可以对各种用户特征进行数据加工,制作成包含全部用户的一张或多张用户特征表,提供灵活的用户画像分析,支撑广告,圈人等业务需求等等。
接下来,我们讲讲EMR ClickHouse架构。我们在ClickHouse的基础上做了一定的增强。首先,我们重构了In Memory Part写入模块,让它支持Flink单条写入,Flink Exactly Once事务写入以及Sharding Key写入。成功解决了写Distributed表的痛点,提升了整体性能。其次,它还支持DiskOSS。实现了冷热的分层存储,节约了成本。最后,我们实现了副本扩容和分片扩容,让扩容方式变得更灵活。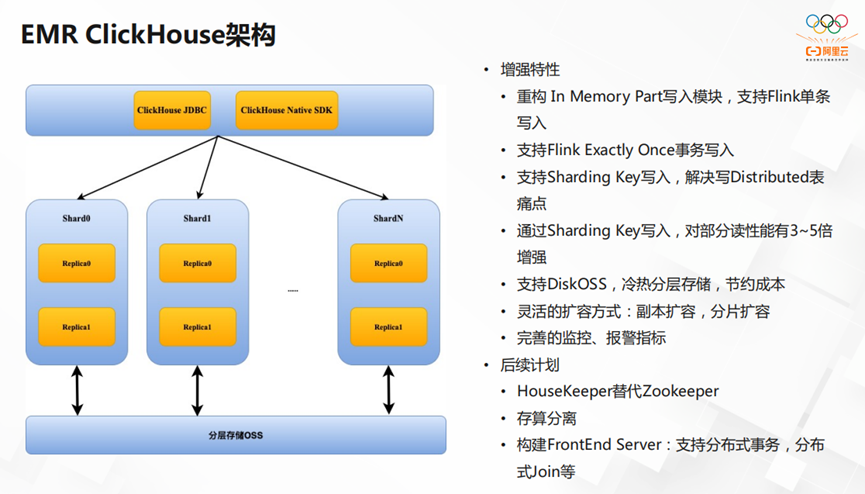
04
StarRocks介绍 
接下来,我们聊一聊StarRocks。StarRocks其向量化的执行引擎,实现了亚秒级查询延时。StarRocks单节点100M/秒的写入速度,让它每秒可处理100亿行数据。StarRocks的综合查询速度比其他产品快10到100倍。数据秒级实时更新可见。其次,StarRocks支持数千用户同时分析,部分场景每秒可支持1万以上的QPS,TP99控制在1秒以内。最后,StarRocks基于多种数据模型,实现了极速分析,缩短业务交付时间。提升了数据工程师和分析师工作效率。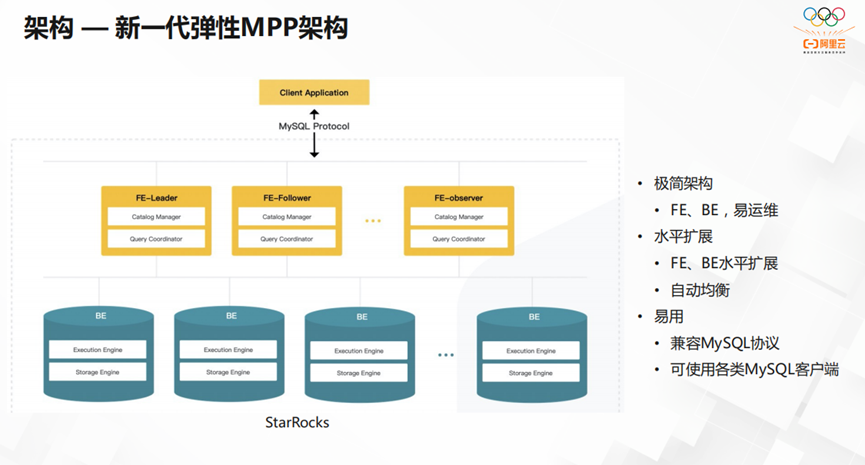
如上图所示,StarRocks的架构简洁明了,兼容MySQL协议,可使用各类MySQL客户端。并且支持FE、BE的水平扩展,从而实现自动均衡。让运维和使用都非常方便。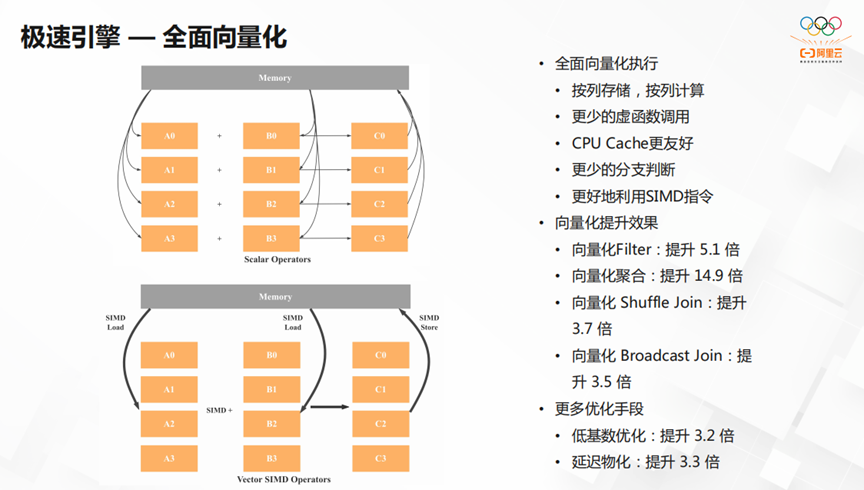
StarRocks的极速引擎,实现了全面向量化执行。它可以按列存储,按列计算。用更少的虚函数调用,更少的分支判断,更好地利用SIMD指令并且对CPU Cache更友好。其次,StarRocks向量化提升的效果明显。向量化Filter,向量化聚合和向量化Shuffle Join的效果都有几何倍数的提升。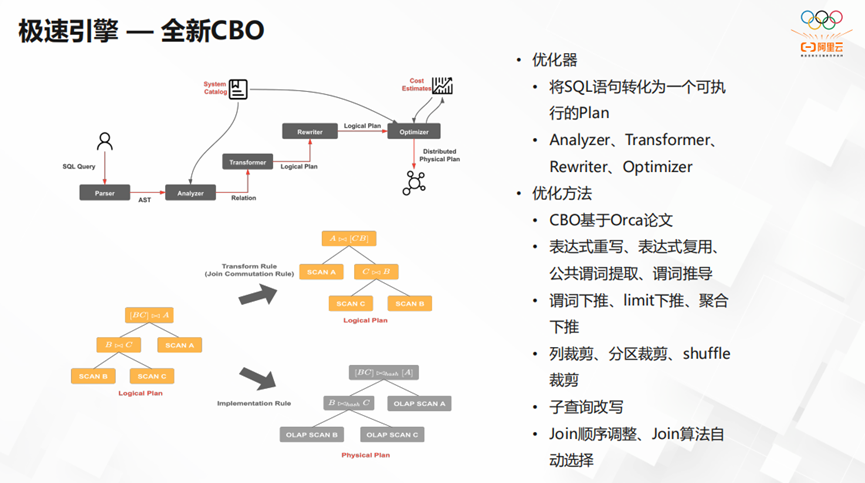
StarRocks的极速引擎,具有全新的CBO。基于Orca论文,将表达式重写、表达式复用。用公共谓词提取、谓词推导。将子查询改写,调整Join顺序、让Join算法自动选择。成功的将SQL语句转化为一个可执行Plan。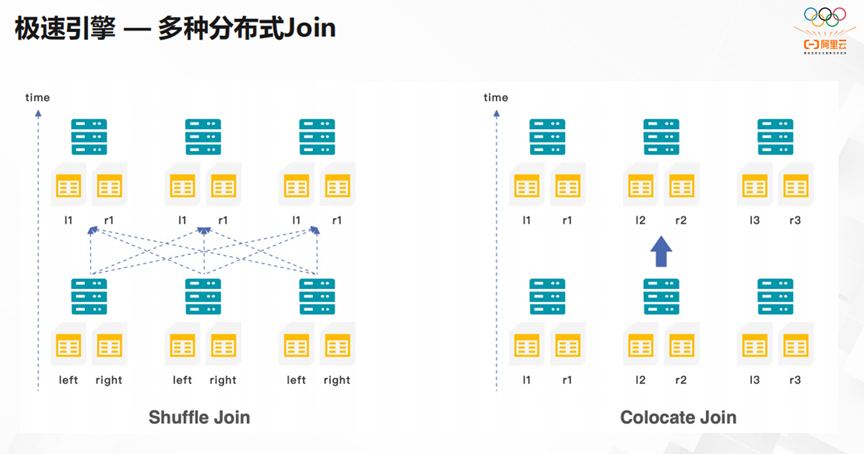
StarRocks的极速引擎,具有多种分布式的Join。目前,这种分布式Join是ClickHouse比较缺乏的功能。右图是更加高效的Join方式,它通过提前完成bucket分类,让整体运行更加高效。
StarRocks为全场景提供了四种数据模型。
第一,明细模型。用于保存和分析原始明细数据,数据写入后几乎无更新。主要用于日志,操作记录,设备状态采样等等。
第二,聚合模型。用于保存,分析,汇总数据。不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新。适用于按时间、地域、机构汇总的数据。
第三,主键模型。支持基于主键的更新,Delete and insert,大批量导入时保证高性能查询。用于保存和分析需要更新的数据。
第四,更新模型。支持基于主键的更新,Merge On Read,更新频率比主键模型更高。用于保存和分析需要更新的数据。主键模型和更新模型都适用于状态会发生变动的订单,设备状态等。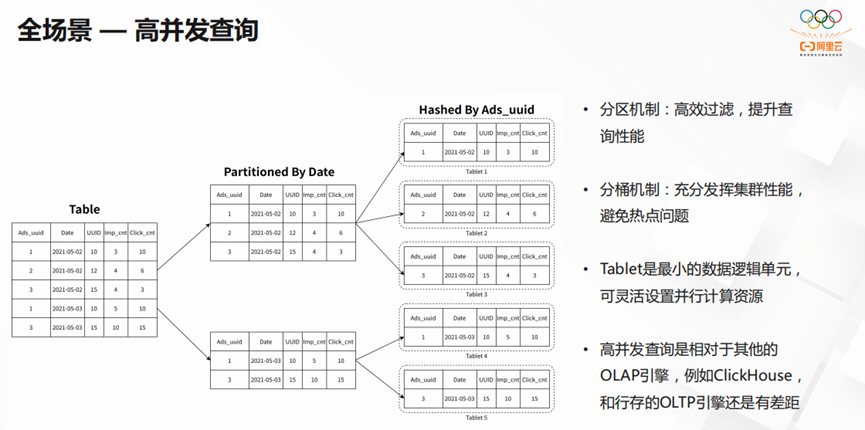
StarRocks在全场景中,还实现了高并发的查询。StarRocks的分区机制可以高效过滤,提升查询性能。StarRocks的分桶机制充分发挥了集群的性能,成功避免了热点问题。但StarRocks相对于其他的OLAP引擎和行存的OLTP引擎还有一定的差距。
在LakeHouse场景中,StarRocks的联合查询,不但屏蔽了底层数据源的细节,而且可以对异构数据据源数据联合分析,与增量数据湖格式完美结合。为了提升查询速度,StarRocks对每种数据源,进行针对性优化。增强了向量化解析ORC、Parquet格式,字典过滤,延迟物化等能力。
StarRocks除了极致的引擎性能和全场景优化的能力,它还实现了弹性伸缩,支持在线扩容,让运维变得简单。面对流量增长,用户不但可以按需伸缩,节省成本。StarRocks还支持小规模初始集群的逐步扩容,大大节省了运维成本。
05
Trino介绍
如下图所示,EMR的数据湖架构以OSS和HDFS作为数据湖的存储层。在存储层的基础上,精心安装了存储优化器,主要是JindoFS和ALLUXIO系列。在存储格式方面,EMR的数据湖支持Hudi,Iceberg和ORC等格式。在计算层,它支持多种计算,比如Flink,SPARK,Trino和Hive等等。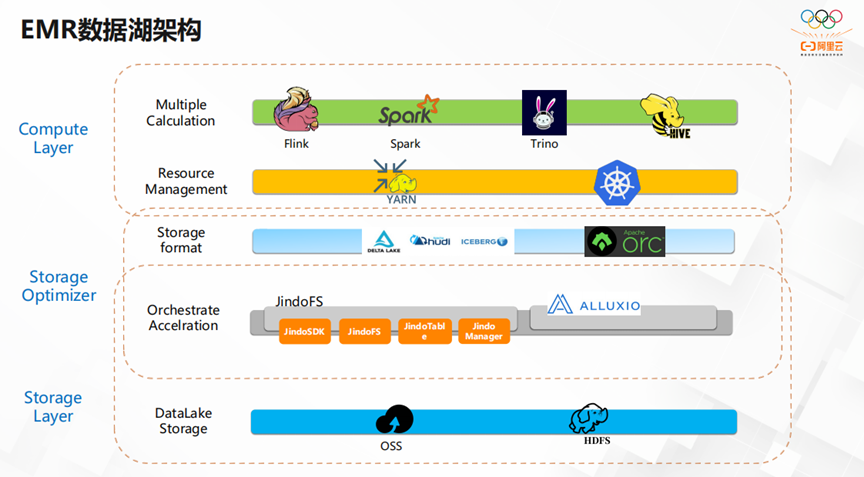
接下来,我们看看EMR Trino的特性。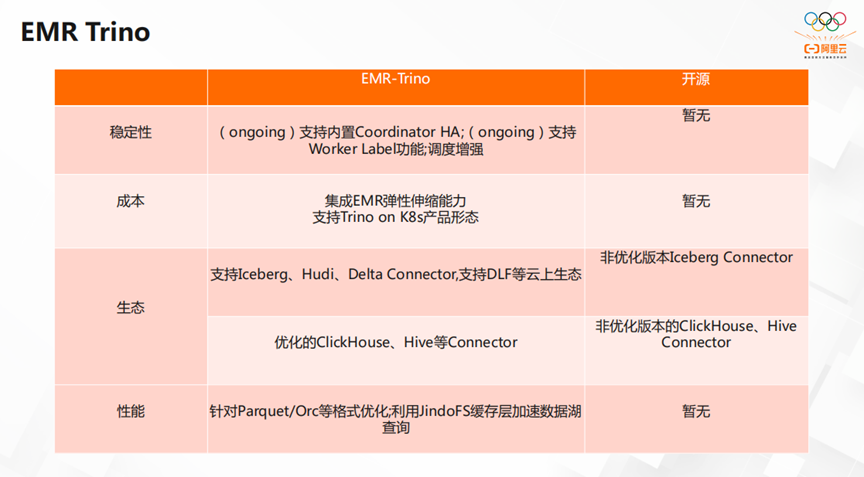
首先在稳定向方面,EMR Trino支持内置Coordinator HA赫尔Worker Label功能。由于EMR Trino集成了EMR弹性伸缩的能力,并且支持Trino on K8s产品形态,所以它大大节省了运维成本。在生态方面,EMR Trino不但支持Iceberg、Hudi、Delta Connector等云上生态,而且支持优化的ClickHouse、Hive等Connector。在性能方面,EMR Trino针对Parquet/Orc等格式,进行优化。并且利用JindoFS的缓存层加速数据湖查询。大幅提升了查询效率。
06
客户案例 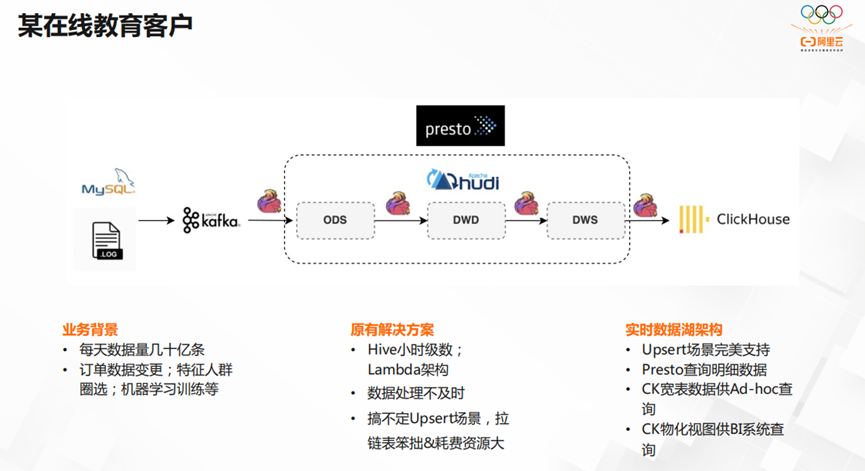
最后,我们一起聊几个客户案例。如上图所示,这是一家在线教育客户。它每天的数据量高达几十亿条,同时还存在订单数据变更,特征人群圈选,机器学习训练等需求。原有的解决方案,存在数据处理不及时,无法应对Upsert场景,并且拉链表笨拙,耗费资源大。经过改造之后,完美支持Upsert场景,Presto可以查询明细数据,CK的宽表数也可供Ad-hoc查询,CK的物化视图供BI系统查询。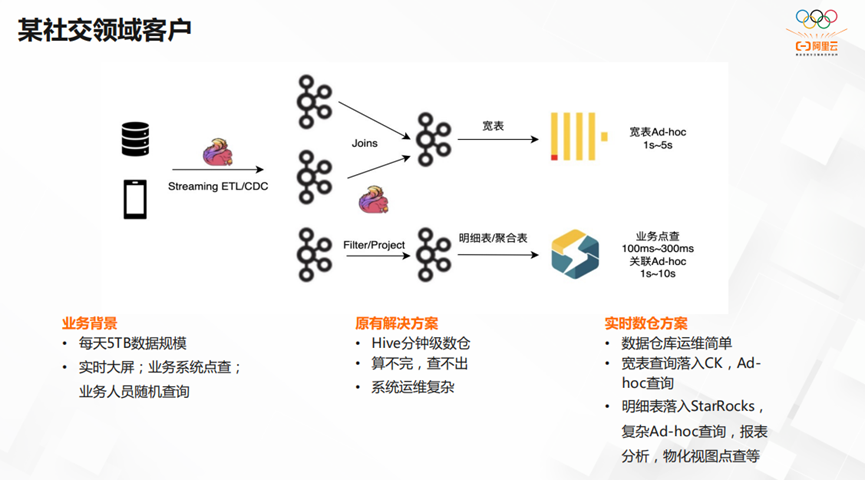
上图是社交领域客户的架构图。它每天有5TB的数据规模,需要支持实时大屏,业务系统点查和业务人员随机查询。在改造之前,Hive是分钟级数仓,它面临算不完,查不出,系统运维复杂的痛点。我们将宽表查询落入CK和Ad-hoc查询,将明细表落入StarRocks,实现了复杂Ad-hoc查询,报表分析,物化视图点查能力。让数据仓库的运维变得简单高效。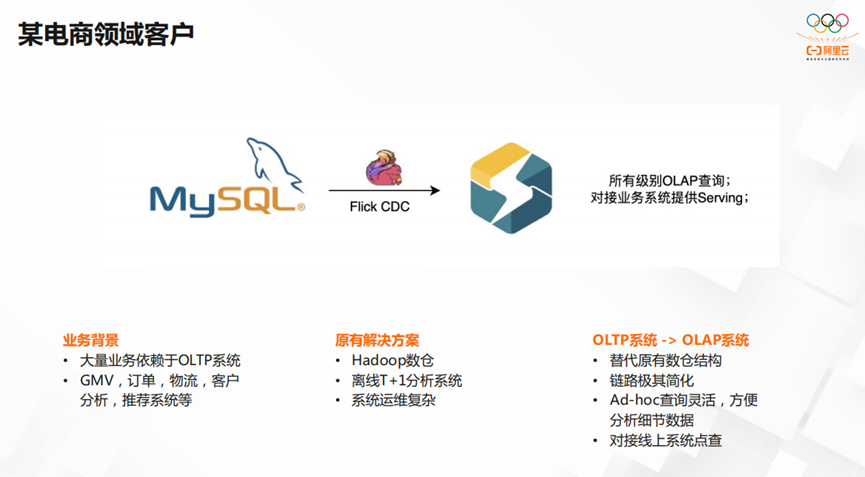
上图是某电商领域的客户,它的大量业务依赖OLTP系统,在GMV,订单,物流,客户分析,推荐系统等方面,都有升级的需求。原先的Hadoop数仓和离线T+1分析系统的方式,让整个系统运维复杂,成本居高不下。我们将OLTP系统逐步过渡到OLAP系统,替代了原有数仓结构的同时,让链路变得极其简化,让Ad-hoc查询灵活,方便运维人员分析细节数据,对接线上系统点查。简化系统的同时,提升了运维人员的工作效率,大幅降低了运维成本。
作者:梦想家 Alex
欢迎关注:大数据梦想家

 分类导航
分类导航